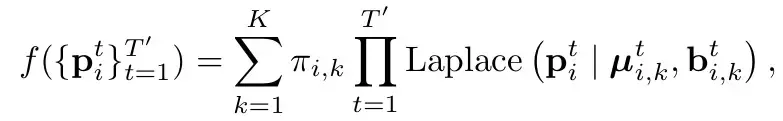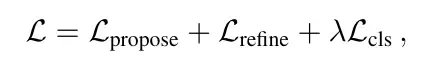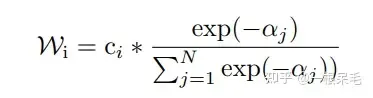HiVT的演化版(不先看HiVT也能直接讀這篇),效能和效率上大幅提升。
文章也很容易閱讀。
【軌跡預測系列】【筆記】HiVT: Hierarchical Vector Transformer for Multi-Agent Motion Prediction - 知乎(zhihu.com)
原文連結:
##https: //openaccess.thecvf.com/content/CVPR2023/papers/Zhou_Query-Centric_Trajectory_Prediction_CVPR_2023_paper.pdf
#Abstract
Agent作為中心進行預測的模型存在一個問題,當一個問題視窗移動時需要重複normalize多次到agent中心,再進行重複encoding的過程,對於onboard使用是不划算的。因此對於場景的encoding我們採用了query-centric的框架,可重複使用已經計算過的結果,不依賴全局的時間座標系。同時,因為對於不同agent共享了場景特徵,使得agent的軌跡decoding過程可更加並行化處理。
對於場景進行了複雜的編碼,目前的解碼方法對於mode的資訊抓取還是比較困難,特別是對於長時間的預測。為了解決這個問題,我們首先使用anchor-free的query產生軌跡proposal(走一步看一步的提取特徵方法),這樣model能夠更好利用不同時間刻位的場景特徵。接著是調整模組,利用上一步得到的proposal來進行軌跡的調優(動態的anchor-based)。透過這些高品質的anchor,我們的query-based decoder可以更好地處理mode的特徵。
打榜成功。這個設計也實現了場景特徵encoding和並行多agent的decoding的pipeline。
Introduction
目前的軌跡預測paper有這麼多問題:
對於多種- 異質的場景訊息額度處理效率低。無人駕駛任務裡,數據以一幀一幀的流給到model,包含向量化的高精地圖和周圍agent的歷史軌跡。最近的factorized attention方法(時空分開分別進行attentin)將這些資訊的處理提升到新高度。但這需要對於每個場景元素做attention,如果場景非常複雜,cost還是很大的。
隨著預測的時間增長,預測的- 不確定性也在爆炸性成長。例如在路口的車可能直行或轉彎。為了避免錯過潛在的可能性,模型需要取得多mode的分佈,而不是只預測出現頻率最高的mode。但是gt只有一個,沒辦法對多個可能性進行比較好的學習。有些paper提出了多個手捏的anchor來監督的做法,這個效果就完全取決於anchor的品質高低了。當anchor無法準確cover gt時,這個做法就很糟糕了。也有別的做法直接預測多mode,忽略了mode塌縮和訓練不穩定的問題。
為了解決上述問題,我們提出了QCNet。
首先,我們想要在利用好強大的factorized attention的同時,提高onboard的inference速度。過去的agent-centric encoding辦法顯然不行。當下一幀資料到來,視窗就會移動,但還是和上一幀有很大部分重疊的,所以我們有機會
重複使用這些feature。但是agent-centric辦法需要轉到agent座標系,導致其必須重新encode場景。為了解決這個問題,我們使用了query-centric的方法:場景元素在它們自己的時空座標系內進行特徵提取,和全局座標系無關(ego在哪裡無關了)。 (高精地圖可以用因為地圖元素有長久的id,非高精地圖應該就不好用了,地圖元素的得在前後幀tracking住)

這使得我們可以把之前處理好的encoding結果重複使用,對於agent來說直接用這些cache的feature,這樣就能節省latency了。
其次,為了更好地用這些場景encode結果進行多mode長時間預測,我們使用了anchor-free的query來一步步(在上一個位置的地方)提取場景的feature,這樣每一次的decode都是非常短的一步。這個做法可以使得對於場景的特徵提取重心放在agent未來在的某個位置,而不是為了考慮未來多個時刻的位置,去提取遠處的feature。這樣得到的高品質anchor會在下一個refine的module進行精細調整。這樣
結合了anchor-free和anchor-based的做法充分利用了兩個辦法的優點,實現多mode長時間的預測。
這個做法是第一個探討了軌跡預測的連續性來實現高速inference的辦法。同時decoder部分也兼顧了多mode和長時間預測的任務。
Approach
Input and Output
同時prediction模組還可以從高精地圖獲得M個polygon,每個polygon都有多個點以及語意資訊(crosswalk,lane等類型)。
預測模組使用T個時刻的上述的agent state和地圖信息,要給出K個總共T'長度預測軌跡,同時還有其機率分佈。
Query-Centric Scene Context Encoding
#第一步自然是場景的encode。目前流行的factorized attention(時間和空間維度分別做attention)是這麼做的,具體來說一共有三步:
- 時間維度attention,時間複雜度O(A #),每個agent自己的時間維度矩陣乘法
- agent和map的cross attention,時間複雜度O(ATM),在每個時刻,agent和地圖元素的矩陣乘法
- agent和agent間的attention,時間複雜度O(T), 在每個時刻,agent和agent矩陣乘法
這個做法和之前的先在時間維度壓縮feature到當下時刻,再agent和agent,agent和地圖間交互的做法比起來,是對於過去每個時刻去做交互,因此可以獲取更多信息,比如agent和map間在每個時刻的交互演變。
但缺點是三次方的複雜度隨著場景變得複雜,元素變多,會變得很大。我們的目標就是既用好這個factorized attention,同時不讓時間複雜度這麼容易爆炸。
一個很容易想到的辦法是利用上一幀的結果,因為在時間維度上其實有T-1幀是完全重複的。但因為我們需要把這些feature旋轉平移到agent目前幀的位置和朝向,因此沒辦法就這樣使用上一幀運算得到的結果。
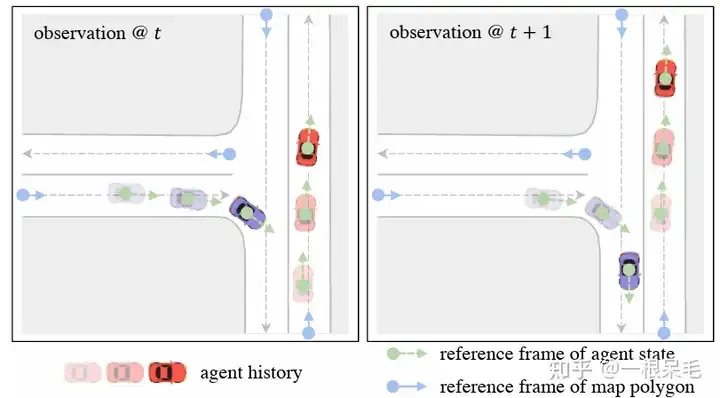
為了解決座標系的問題,採用了query-centric辦法,來學習場景元素的特徵,而不依賴它們的全局座標。這個做法對每個場景元素建立了局部的時空座標系,在這個座標系內提取特徵,即使ego到別處,這個局部提取出來的特徵也是不變的。這個局部時空座標係自然也有一個原點位置和方向,這位置資訊作為key,提取出來的特徵作為value,以便於之後的attention操作。整個做法分為下面幾步:
Local Spacetime Coordinate System
對於agent i在t時刻的feature來說,選擇這個時刻的位置和朝向作為參考系。對於map元素來說,則採用這個元素的起始點作為參考系。這樣的參考系選擇方法可以在ego移動後提取的feature保持不變。
Scene Element Embedding
對於每個元素內的別的向量特徵,都在上述參考系裡取得極座標表示表達。然後將它們轉成傅立葉特徵來獲取高頻訊號。 concat上語意特徵後再MLP取得特徵。對於map元素,為了確保內部點的順序不相關性,先做attention後pooling的操作。最後得到agent特徵為[A, T, D], map特徵為[M, D]. D是特徵維度,保持一致才可以方便attention的矩陣相乘。這樣提取出來的特徵可以使得ego在任何地方都能使用。
傅立葉embedding: 製造常態分佈的embedding,對應各種頻率的權重,乘輸入和2Π, 最後取cos和sin作為feature。直覺理解的話應該是把輸入當作一個訊號,把訊號解碼成多個基本訊號(多個頻率的訊號)。這樣可以更好的抓取高頻訊號,高頻訊號對於結果的精細程度很重要,一般的做法容易失去精細的高頻訊號。值得注意的是對於noisy資料不建議使用,因為會誤抓錯誤的高頻訊號。 (感覺有點像overfit,不能太general但又不能精準過頭)
Relative Spatial-Temporal Positional Embedding
#Self-Attention for Map Encoding
#Factorized Attention for Agent Encoding
#附近的定義為agent周圍50m範圍內。一共會進行次。
值得注意的是,透過上述方法得到的feature具備了時空不變性,即不管ego在什麼時刻到什麼地方,上述feature都是不變的,因為都沒有針對當前的位置資訊進行平移旋轉。由於相較於上一幀只是多了新的一幀數據,並不需要計算之前的時刻的feature,所以總的計算複雜度除以了T。
Query-Based Trajectory Decoding
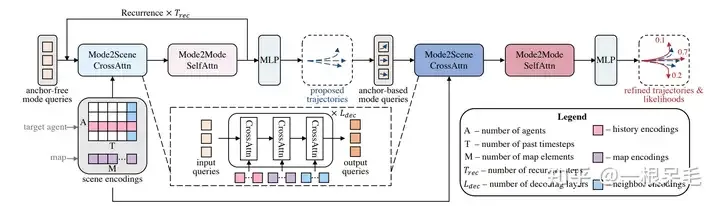
##類似DETR的anchor-free query去某些key value裡做attention的辦法會導致訓練不穩定,模態塌縮的問題,同時長時間預測也不可靠,因為不確定度會在後面爆炸。因此此模型採用了先來一次粗的anchor-free query辦法,再對這個輸出進行refine的anchor-base辦法。
整個網路結構
Mode2Scene and Mode2Mode Attention
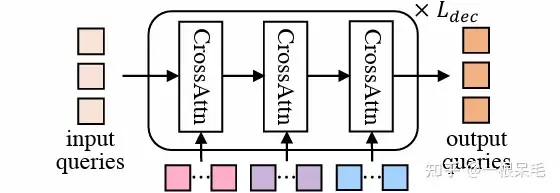
Mode2Scene的兩個步驟都採用了DETR結構:query為K個軌跡mode (粗的proposal步是直接隨機產生的,refine步是由proposal步得到的feature作為輸入),然後在場景feature(agent歷史,map,周圍agent)上做多次cross attention。
DETR結構
Mode2Mode則是在K個mode間進行self attention,企圖實現mode間的diverse,不要都聚在一起。
Reference Frames of Mode Queries
為了並行預測多個agent的軌跡,場景的encoding是被多個agent分享的。因為場景feature都是相對於自身的feature,所以要使用的話還是得轉到agent的視角。對於mode的query,會附加上agent的位置和朝向資訊。和之前encode相對位置類似的操作,也會對場景元素和agent的相對位置的資訊進行embedding作為key和value。 (直覺上說就是agent每個mode在附近資訊使用上的一個加權注意力)
Anchor-Free Trajectory Proposal
第一次是anchor free的辦法,採用可以學習的query來製造相對低品質的軌跡proposal,總共會產生K個proposal。由於會用cross attention的方式從場景資訊中提取特徵,因此可以高效產生比較少而有效的anchor供第二次refine使用。 self attention則使得各proposal整體會更diverse。
Anchor-Based Trajectory Refinement
anchor free的辦法雖然比較簡單,但也存在訓練不穩定的問題,有可能mode塌縮。同時,隨機產生的mode也需要能在全場景裡對於不同agent都有不錯的表現,這比較難,很容易生成出不符合運動學的或者不符合交通的軌跡proposal。因此我們想到可以再來一次anchor-based修正。在proposal的基礎上預測了一個offset(加到原proposal以獲得修正後軌跡),並預測了每個新軌蹟的機率。
這個模組同樣使用了DETR的形式,每個mode的query都是用上一步的proposal來提取,具體是用了一個小的GRU來embed每個anchor(一步步往前走) ,使用到最後一個時刻的feature作為query。這些基於anchor的query可以提供一定的空間訊息,使得attention時更容易捕捉有用的信息。
Training Objectives
和HiVT一樣(參考HiVT的分析),採用Laplace分佈。直白的講法就是把每個mode下每個時刻建模為一個laplace分佈(參考一般的高斯分佈,由mean和var,代表這個點的位置和其不確定性)。並認為時刻之間是獨立的(直接連乘)。 Π代表了對應mode的機率。
Loss的話由3部分組成
#主要分為兩個部分:
分類loss和回歸loss。
分類loss是指預測機率的loss,這個地方要注意的是需要
打斷梯度回傳,不可以讓機率的引起的梯度傳到對於座標的預測(即在假設每個mode預測位置為合理的前提下)。 label則是最接近gt的為1,別的都是0。
回歸loss有兩個,一個是一階段的proposal的loss,一個是二階段的refine的loss。採用贏者全拿的辦法,也就是只計算最接近gt的mode的loss,兩個階段的迴歸loss都要算算出來。為了訓練的穩定性,這裡在兩個階段中也打斷了梯度回傳,使得proposal學習就專門學習proposal,refine就只學refine。
Experiments
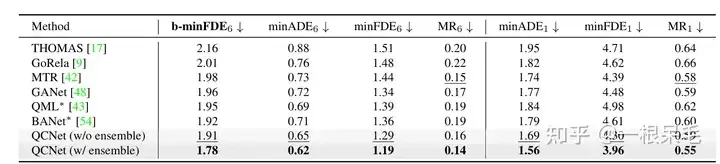
Argoverse2基本各項SOTA(* 表示使用了ensemble技巧)
#b-minFDE相較於minFDE的差異在於額外乘上了與其機率相關的係數. 即目標希望FDE最小的那條軌跡的機率越高越好。
關於ensemble技巧,感覺是有點作弊的:可以參考BANet裡的介紹,以下簡單介紹一下。
生成軌蹟的最後一步同時連做好多遍結構一樣的submodel(decoder),會給出多組預測,例如有7個submodel,每個有6條預測,一共42條。然後用kmeans來進行聚類(以最後一個座標點為聚類標準),目標是6組,每組7條,然後每組裡面進行加權平均獲得新軌跡。
加權方法如下,為當前軌跡和gt的b-minFDE,c為當前軌蹟的機率,在每組裡面進行權重計算,然後對軌跡座標加權求和獲得一條新軌跡。 (感覺多少有些tricky,因為c其實是這個軌跡在submodel輸出裡的機率,拿來在聚類裡算有點不太符合預期)
並且這麼操作後新軌蹟的機率也很難精準計算,不能用上述方法,否則總機率和就不一定是1了。似乎也只能等權重地算聚類裡的機率了。
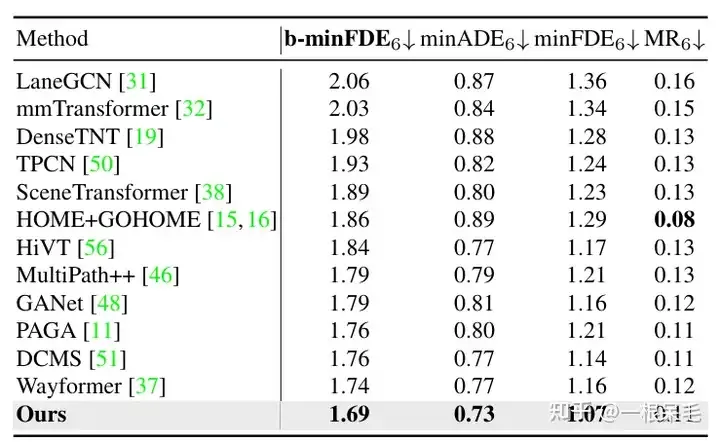
Argoverse1也是遙遙領先
關於場景encode的研究:如果復用了先前的場景encode結果,infer的時間可以大幅減少。 agent與場景資訊的factorized attention互動次數變多,預測效果也會變好,只是latency也漲的很兇,需要權衡。
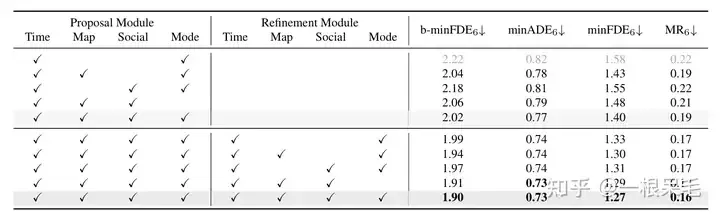
各種操作的研究:證明了refine的重要性,以及factorized attention在各種互動中的重要性,缺一不可。