

直接擴展到無限長,GoogleInfini-Transformer終結上下文長度之爭

不知 Gemini 1.5 Pro 是否用到了這項技術。
Google又放大招了,發布下一代 Transformer 模型 Infini-Transformer。
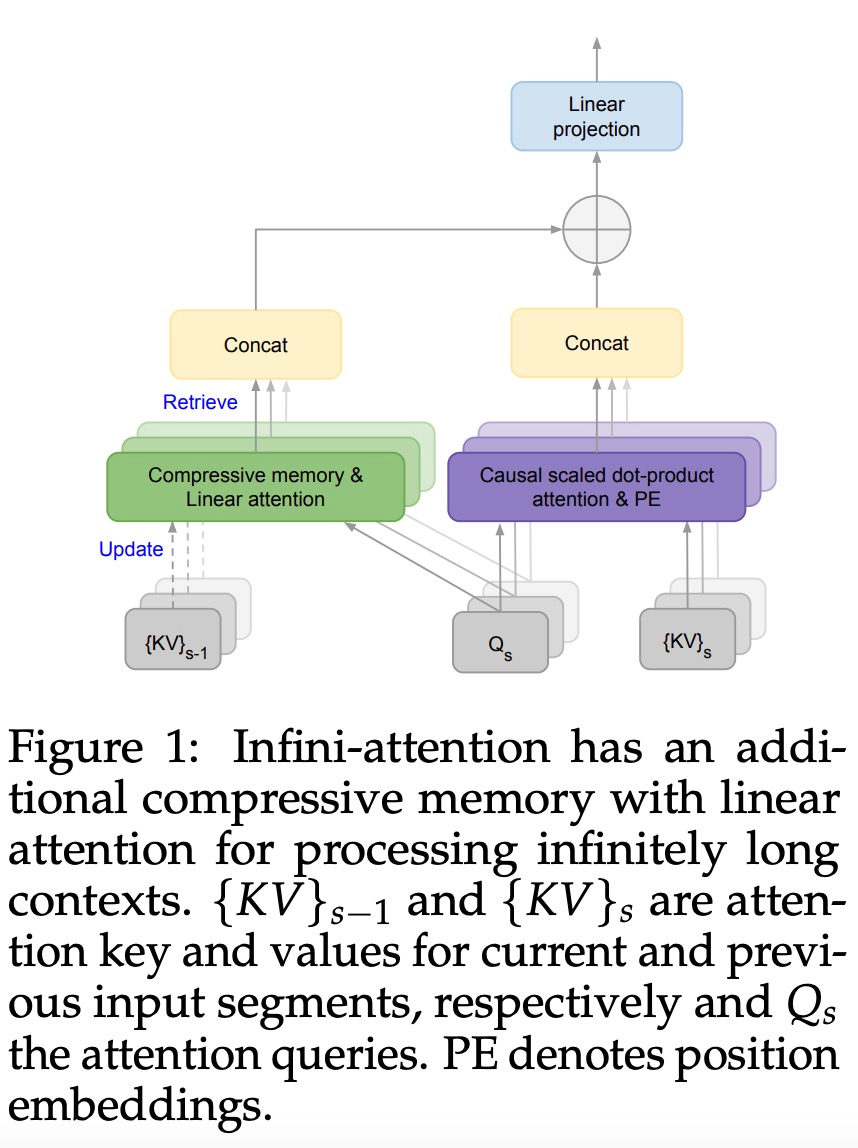
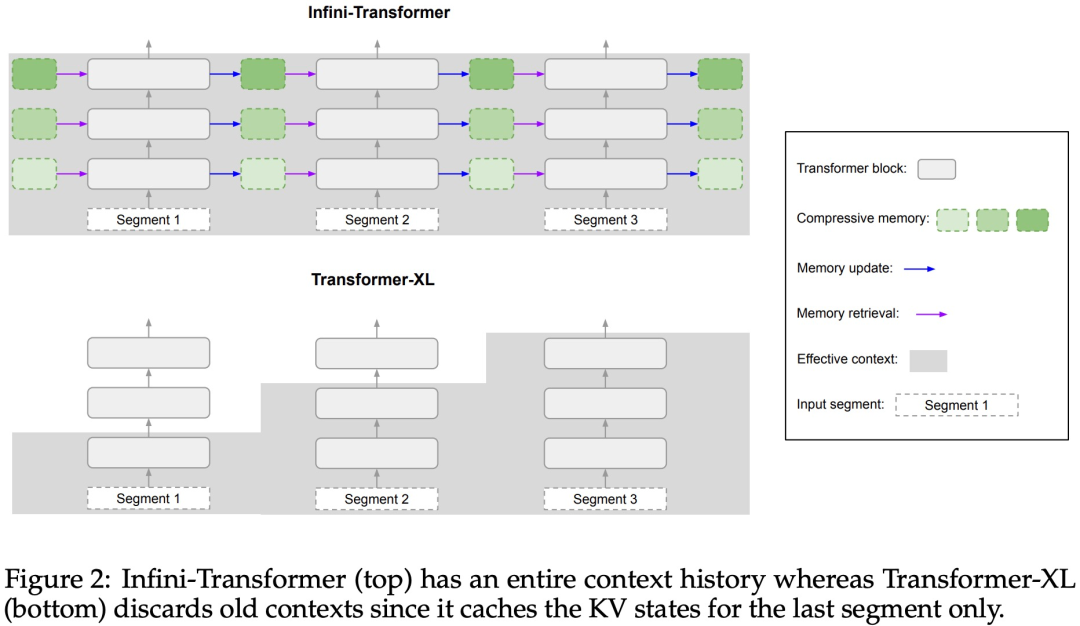
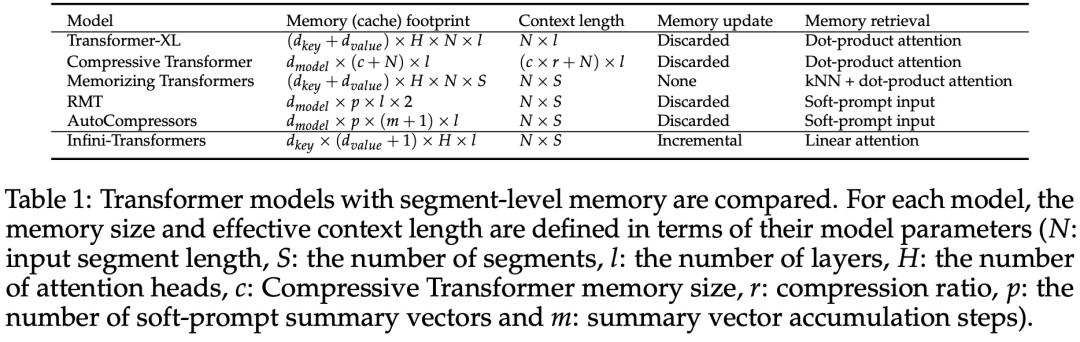
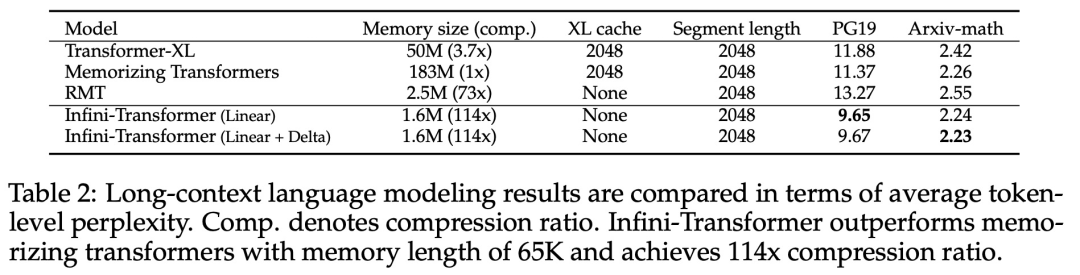
#引入了一個實用且強大的注意力機制Infini-attention——具有長期壓縮記憶體和局部因果注意力,可用於有效地建模長期和短期上下文依賴關係; Infini-attention 對標準縮放點積注意力( standard scaled dot-product attention)進行了最小的改變,並透過設計支持即插即用的持續預訓練和長上下文自適應; - ##該方法使Transformer LLM 能夠透過流的方式處理極長的輸入,在有限的記憶體和計算資源下擴展到無限長的上下文。

- 論文連結:https://arxiv.org/pdf/2404.07143.pdf
- #論文標題:Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention

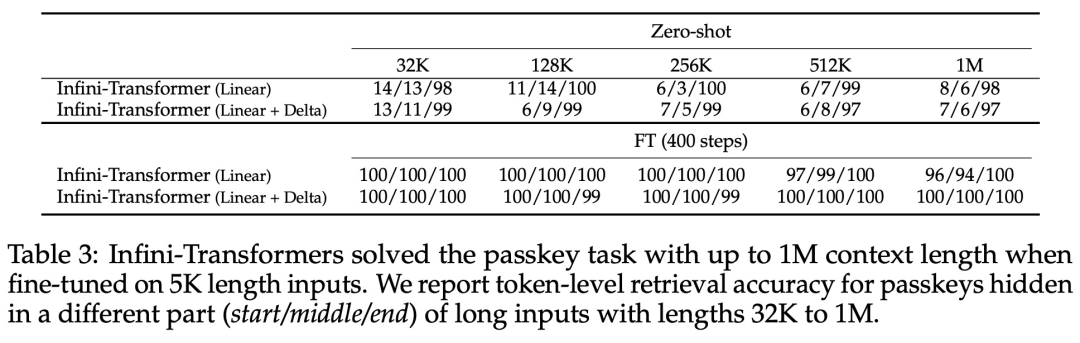
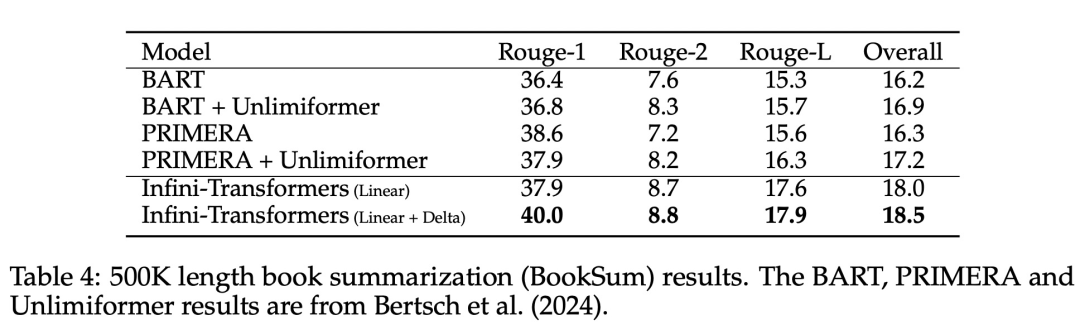

以上是直接擴展到無限長,GoogleInfini-Transformer終結上下文長度之爭的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 Bangla 部分模型檢索中的 Laravel Eloquent ORM)
Apr 08, 2025 pm 02:06 PM
Bangla 部分模型檢索中的 Laravel Eloquent ORM)
Apr 08, 2025 pm 02:06 PM
LaravelEloquent模型檢索:輕鬆獲取數據庫數據EloquentORM提供了簡潔易懂的方式來操作數據庫。本文將詳細介紹各種Eloquent模型檢索技巧,助您高效地從數據庫中獲取數據。 1.獲取所有記錄使用all()方法可以獲取數據庫表中的所有記錄:useApp\Models\Post;$posts=Post::all();這將返回一個集合(Collection)。您可以使用foreach循環或其他集合方法訪問數據:foreach($postsas$post){echo$post->
 CS-第 3 週
Apr 04, 2025 am 06:06 AM
CS-第 3 週
Apr 04, 2025 am 06:06 AM
算法是解決問題的指令集,其執行速度和內存佔用各不相同。編程中,許多算法都基於數據搜索和排序。本文將介紹幾種數據檢索和排序算法。線性搜索假設有一個數組[20,500,10,5,100,1,50],需要查找數字50。線性搜索算法會逐個檢查數組中的每個元素,直到找到目標值或遍歷完整個數組。算法流程圖如下:線性搜索的偽代碼如下:檢查每個元素:如果找到目標值:返回true返回falseC語言實現:#include#includeintmain(void){i
 Redis內存使用率過高怎麼辦?
Apr 10, 2025 pm 02:21 PM
Redis內存使用率過高怎麼辦?
Apr 10, 2025 pm 02:21 PM
Redis內存飆升的原因包括:數據量過大、數據結構選擇不當、配置問題(如maxmemory設置過小)、內存洩漏。解決方法有:刪除過期數據、使用壓縮技術、選擇合適的結構、調整配置參數、檢查代碼是否存在內存洩漏、定期監控內存使用情況。
 Redis持久化對內存的影響是什麼?
Apr 10, 2025 pm 02:15 PM
Redis持久化對內存的影響是什麼?
Apr 10, 2025 pm 02:15 PM
Redis持久化會額外佔用內存,RDB在生成快照時臨時增加內存佔用,AOF在追加日誌時持續佔用內存。影響因素包括數據量、持久化策略和Redis配置。要減輕影響,可合理配置RDB快照策略、優化AOF配置、升級硬件和監控內存使用情況。此外,在性能和數據安全之間尋求平衡至關重要。
 如何根據業務需求設置Redis內存大小?
Apr 10, 2025 pm 02:18 PM
如何根據業務需求設置Redis內存大小?
Apr 10, 2025 pm 02:18 PM
Redis 內存大小設置需要考慮以下因素:數據量及增長趨勢:估算存儲數據的大小和增長率。數據類型:不同類型(如列表、哈希)佔用內存不同。緩存策略:全緩存、部分緩存和淘汰策略會影響內存使用。業務峰值:預留足夠內存應對流量高峰。
 Redis內存數據類型有哪些?
Apr 10, 2025 pm 02:06 PM
Redis內存數據類型有哪些?
Apr 10, 2025 pm 02:06 PM
Redis 提供五種核心內存數據類型:String:基礎字符串存儲,支持遞增/遞減操作。 List:雙向鍊錶,高效插入/刪除操作。 Set:無序集合,用於去重操作。 Hash:鍵值對存儲,適合存儲結構化數據。 Zset:有序集合,每個元素帶分數,可按分數排序。選擇合適的數據類型對於優化性能至關重要。
 XML如何添加新的節點
Apr 02, 2025 pm 07:15 PM
XML如何添加新的節點
Apr 02, 2025 pm 07:15 PM
XML節點添加技巧:通過理解樹狀結構並找到合適的插入點,使用ElementTree庫的SubElement函數創建新節點。更複雜的場景需要根據節點屬性或內容進行選擇性插入或批量添加,這需要邏輯判斷和循環。對於大型文件,考慮使用更快的lxml庫。遵循良好代碼風格,清晰註釋有助於代碼的可讀性和可維護性。
 虛擬幣最老的幣排行榜最新更新
Apr 22, 2025 am 07:18 AM
虛擬幣最老的幣排行榜最新更新
Apr 22, 2025 am 07:18 AM
虛擬貨幣“最老”排行榜如下:1. 比特幣(BTC),發行於2009年1月3日,是首個去中心化數字貨幣。 2. 萊特幣(LTC),發行於2011年10月7日,被稱為“比特幣的輕量版”。 3. 瑞波幣(XRP),發行於2011年,專為跨境支付設計。 4. 狗狗幣(DOGE),發行於2013年12月6日,基於萊特幣代碼的“迷因幣”。 5. 以太坊(ETH),發行於2015年7月30日,首個支持智能合約的平台。 6. 泰達幣(USDT),發行於2014年,是首個與美元1:1錨定的穩定幣。 7. 艾達幣(ADA),發
