

CVPR\'24 | LightDiff:低光照場景下的擴散模型,直接照亮夜晚!

原標題:Light the Night: A Multi-Condition Diffusion Framework for Unpaired Low-Light Enhancement in Autonomous Driving
論文連結:https://arxiv.org/pdf/2404.04804.pdf
作者單位:克利夫蘭州立大學德州大學奧斯汀分校A*STAR 紐約大學加州大學洛杉磯分校

論文思路:
LightDiff 是一種為自動駕駛的視覺中心感知系統提升效益和可擴展性的技術。相較於雷射雷達系統,最近受到了相當多的關注。然而,這些系統在低光照條件下常常會遇到困難,可能會影響其性能和安全性。為了解決這個問題,本文介紹了 LightDiff,這是一個為自動駕駛應用中提升低光照影像品質而設計的自動化框架。具體來說,本文採用了一個多條件控制的擴散模型。 LightDiff 無需人工收集的成對數據,而是利用動態數據退化過程。它結合了一個新穎的多條件適配器,該適配器能夠自適應地控制來自不同模態的輸入權重,包括深度圖、RGB圖像和文字標題,以在低光照和光照條件下同時保持內容的一致性。此外,為了使增強型的圖像和檢測模型的知識相匹配,LightDiff 使用特定於感知的評分作為獎勵,透過強化學習來指導擴散訓練過程。在 nuScenes 資料集上進行的廣泛實驗表明,LightDiff 能夠顯著提高多個最新的3D偵測器在夜間條件下的性能,並同時實現高視覺品質評分,凸顯了其在保障自動駕駛安全方面的潛力。
主要貢獻:
本文提出了Lighting Diffusion (LightDiff)模型,以增強自動駕駛中的低光照相機影像,減少了對大量夜間資料收集的需求,並保持了白天的性能能力。
本文整合了包括深度圖和圖像標題在內的多種輸入模式,並提出了一個多條件適配器,以確保圖像轉換中的語義完整性,同時保持高視覺品質。本文採用了一個實用的過程,從白天資料生成晝夜影像對,以實現高效的模型訓練。
本文介紹了一種使用強化學習的微調機制,結合了感知定制的領域知識(可信的雷射雷達和統計分佈的一致性),以確保擴散過程具有利於人類視覺感知的強度,並利用感知模型進行感知模型。此方法在人類視覺感知方面具有顯著優勢,同時也具有感知模型的優勢。
在nuScenes資料集上進行的廣泛實驗表明,LightDiff 顯著提高了夜間3D車輛輛偵測的效能,並在多個視角指標上超越了其他生成模型。
網頁設計:
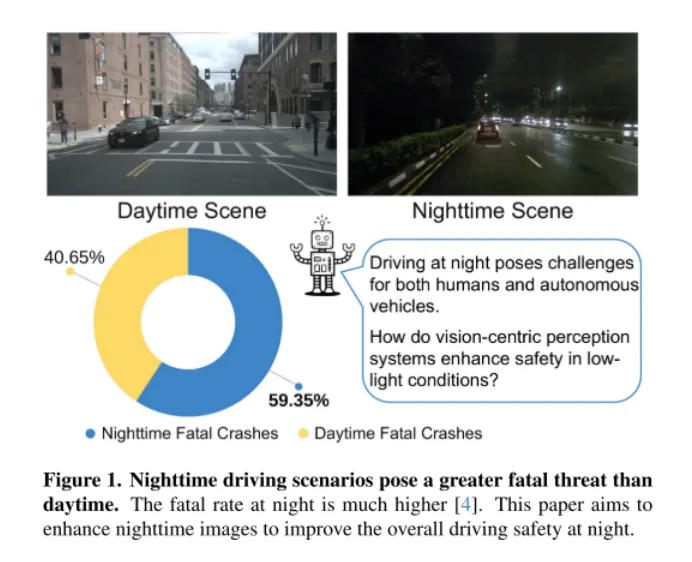
#圖1。夜間駕駛場景比白天更具致命威脅。夜間的致命率要高得多[4]。本文旨在增強夜間影像,以提高夜間駕駛的整體安全性。
如圖1所示,夜間駕駛對人類來說是具有挑戰性的,對於自動駕駛汽車來說更是如此。 2018年3月18日,一起災難性的事件突顯了這項挑戰,當時 Uber Advanced Technologies Group 的一輛自動駕駛汽車在亞利桑那州撞擊並致死了一名行人[37]。這起事件是由於車輛未能在低光照條件下準確檢測到行人而引起的,它將自動駕駛汽車的安全問題推到了前沿,尤其是在這樣要求苛刻的環境中。隨著以視覺為中心的自動駕駛系統越來越多地依賴相機感測器,解決低光照條件下的安全隱患已經變得越來越關鍵,以確保這些車輛的整體安全。
一種直覺的解決方案是收集大量的夜間駕駛數據。然而,這種方法不僅勞動密集、成本高昂,而且由於夜間與白天影像分佈的差異,還有可能損害白天模型的表現。為了應對這些挑戰,本文提出了 Lighting Diffusion (LightDiff )模型,這是一種新穎的方法,它消除了手動資料收集的需求,並保持了白天模型的性能。
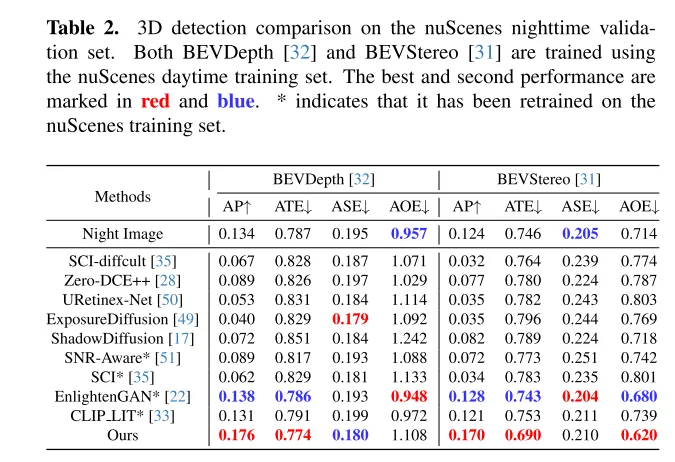
LightDiff 的目標是增強低光相機影像,提高感知模型的效能。透過使用動態的低光衰減過程,LightDiff 從現有的白天資料產生合成的晝夜影像對進行訓練。接著,本文採用了 Stable Diffusion [44]技術,因為它能夠產生高品質的視覺效果,有效地將夜間場景轉換成白天的等效物。然而,在自動駕駛中保持語義一致性至關重要,這是原始 Stable Diffusion 模型面臨的挑戰。為了克服這一點,LightDiff 結合了多種輸入模態,例如估計的深度圖和相機影像標題,配合一個多條件適配器。這個適配器智慧地確定每種輸入模態的權重,確保轉換影像的語義完整性,同時保持高視覺品質。為了引導擴散過程不僅朝著對人類視覺更亮的方向,而且對感知模型也是如此,本文進一步使用強化學習對本文的 LightDiff 進行微調,循環中加入了為感知量身定制的領域知識。本文在自動駕駛資料集nuScenes [7]上進行了廣泛的實驗,並證明了本文的LightDiff 可以顯著提高夜間3D車輛偵測的平均精度(AP),分別為兩個最先進模型BEVDepth [32]和BEVStereo [31]提高了4.2%和4.6%。
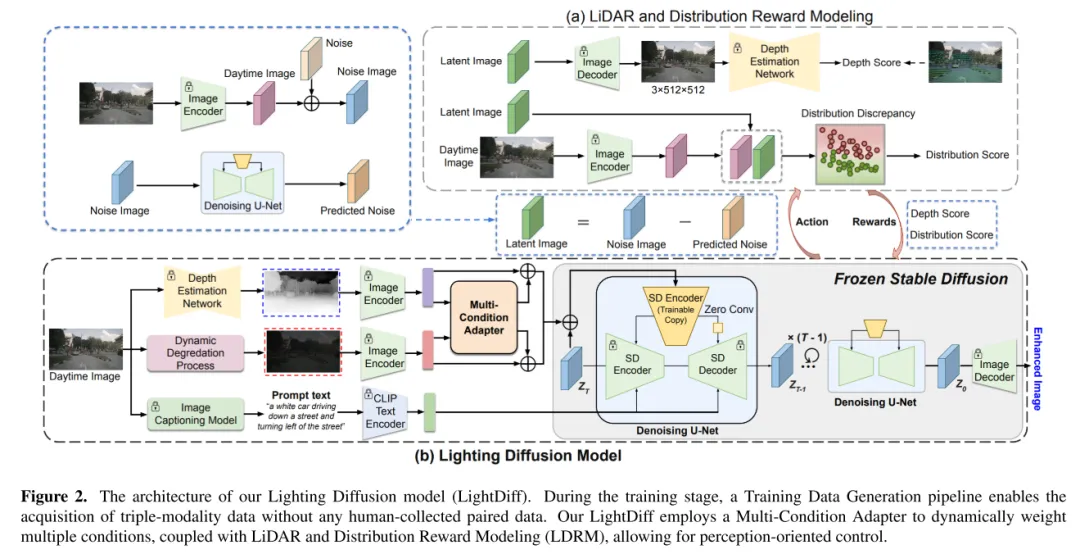
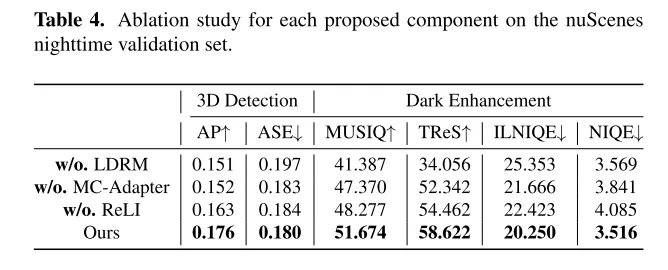
圖2. 本文的 Lighting Diffusion 模型(LightDiff )的架構。在訓練階段,一個訓練資料產生流程使得無需任何人工收集的配對資料就能取得三模態資料。本文的 LightDiff 使用了一個多條件適配器來動態加權多種條件,結合雷射雷達和分佈獎勵建模(LDRM),允許以感知為導向的控制。
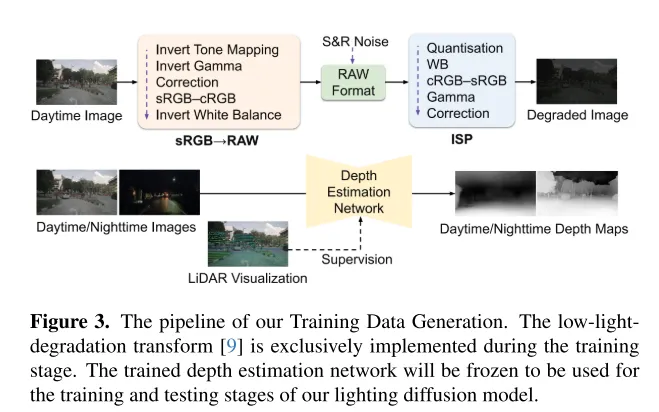
圖3. 本文的訓練資料產生流程。低光照退化轉換[9]僅在訓練階段實施。訓練好的深度估計網路將被凍結,用於本文 Lighting Diffusion 模型的訓練和測試階段。
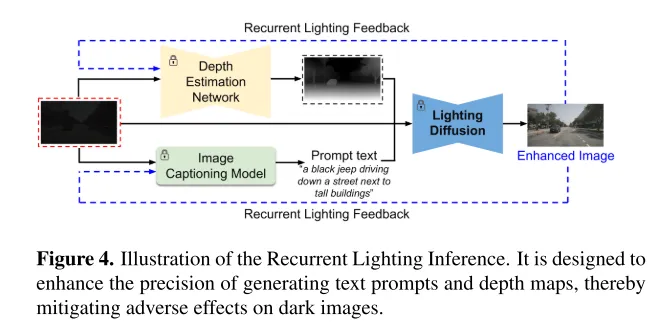
圖4. 循環照明推理(Recurrent Lighting Inference)的示意圖。其設計旨在提高生成文字提示和深度圖的精確度,從而減輕對暗圖像的不利影響。
實驗結果:

圖5. 在 nuScenes 驗證集中的夜間影像範例上的視覺對比。

圖6. 在 nuScenes 驗證集中的夜間影像範例上的三維偵測結果視覺化。本文使用 BEVDepth [32] 作為三維偵測器,並視覺化相機的正視圖和鳥瞰圖(Bird’s-Eye-View)。

圖7. 展示本文的 LightDiff 在有無多條件適配器(MultiCondition Adapter)的情況下的視覺效果。 ControlNet [55]的輸入保持一致,包括相同的文字提示和深度圖。多條件適配器在增強過程中實現了更好的顏色對比和更豐富的細節。
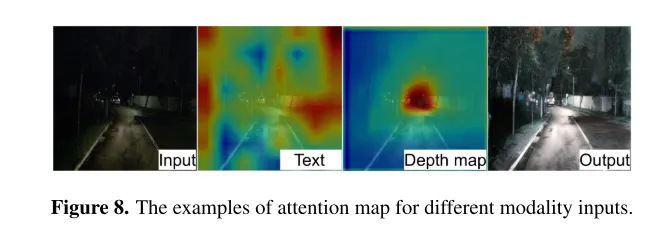
圖8. 不同模態輸入的注意力圖範例。

圖9. 透過循環照明推理(Recurrent Lighting Inference, ReLI)增強多模態產生的示意圖。透過呼叫一次 ReLI,提高了文字提示和深度圖預測的準確性。
总结:
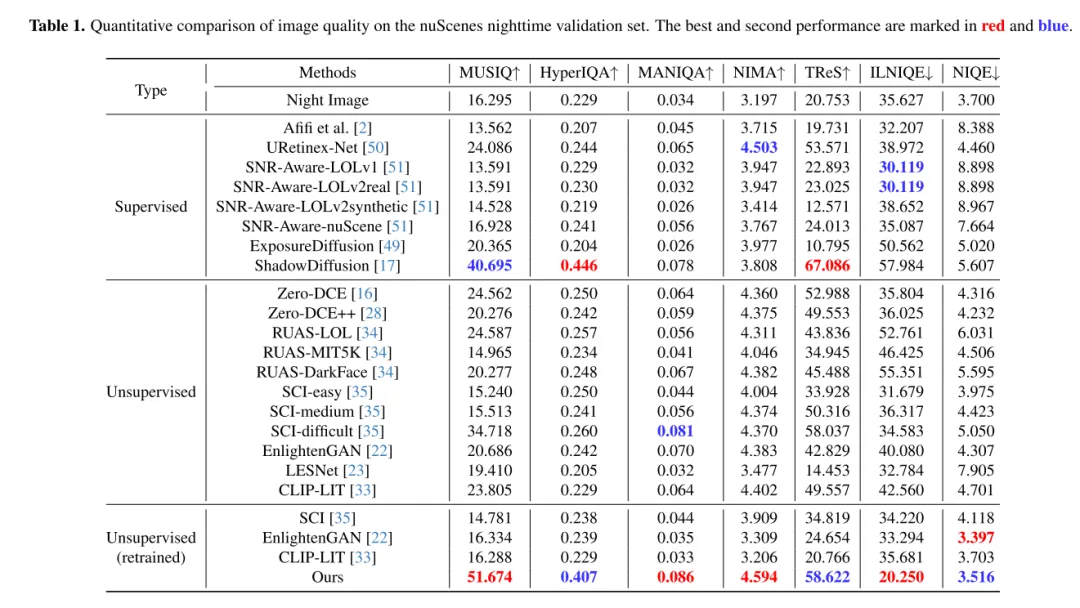
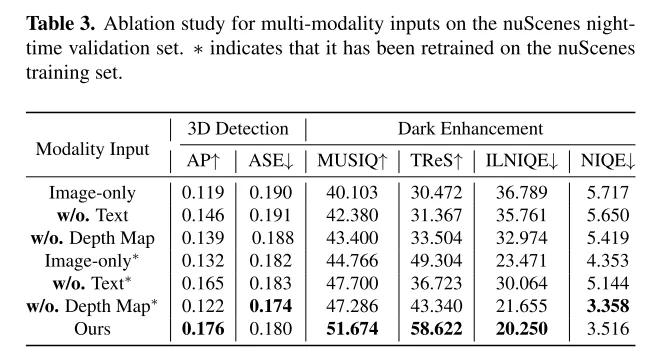
本文介绍了 LightDiff ,这是一个为自动驾驶应用设计的、针对特定领域的框架,旨在提高低光照环境下图像的质量,减轻以视觉为中心的感知系统所面临的挑战。通过利用动态数据退化过程(dynamic data degradation process)、针对不同输入模态的多条件适配器,以及使用强化学习的感知特定评分引导奖励建模,LightDiff 显著提升了 nuScenes 数据集夜间的图像质量和3D车辆检测性能。这一创新不仅消除了对大量夜间数据的需求,还确保了图像转换中的语义完整性,展示了其在提高自动驾驶场景中的安全性和可靠性方面的潜力。在没有现实的成对昼夜图像的情况下,合成带有车灯的暗淡驾驶图像是相当困难的,这限制了该领域的研究。未来的研究可以集中在更好地收集或生成高质量训练数据上。
引用:
@ARTICLE{2024arXiv240404804L,
author = {{Li}, Jinlong and {Li}, Baolu and {Tu}, Zhengzhong and {Liu}, Xinyu and {Guo}, Qing and {Juefei-Xu}, Felix and {Xu}, Runsheng and {Yu}, Hongkai},
title = "{Light the Night: A Multi-Condition Diffusion Framework for Unpaired Low-Light Enhancement in Autonomous Driving}",
journal = {arXiv e-prints},
keywords = {Computer Science - Computer Vision and Pattern Recognition},
year = 2024,
month = apr,
eid = {arXiv:2404.04804},
pages = {arXiv:2404.04804},
doi = {10.48550/arXiv.2404.04804},
archivePrefix = {arXiv},
eprint = {2404.04804},
primaryClass = {cs.CV},
adsurl = {https://ui.adsabs.harvard.edu/abs/2024arXiv240404804L},
adsnote = {Provided by the SAO/NASA Astrophysics Data System}
}
以上是CVPR\'24 | LightDiff:低光照場景下的擴散模型,直接照亮夜晚!的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 邁向『閉環』| PlanAgent:基於MLLM的自動駕駛閉環規劃新SOTA!
Jun 08, 2024 pm 09:30 PM
邁向『閉環』| PlanAgent:基於MLLM的自動駕駛閉環規劃新SOTA!
Jun 08, 2024 pm 09:30 PM
中科院自動化所深度強化學習團隊聯合理想汽車等提出了一種新的基於多模態大語言模型MLLM的自動駕駛閉環規劃框架—PlanAgent。此方法以場景的鳥瞰圖和基於圖的文本提示為輸入,利用多模態大語言模型的多模態理解和常識推理能力,進行從場景理解到橫向和縱向運動指令生成的層次化推理,並進一步產生規劃器所需的指令。在大規模且具有挑戰性的nuPlan基準上對該方法進行了測試,實驗表明PlanAgent在常規場景和長尾場景上都取得了最好(SOTA)性能。與常規大語言模型(LLM)方法相比,PlanAgent所
 如何評估Java框架商業支援的性價比
Jun 05, 2024 pm 05:25 PM
如何評估Java框架商業支援的性價比
Jun 05, 2024 pm 05:25 PM
評估Java框架商業支援的性價比涉及以下步驟:確定所需的保障等級和服務等級協定(SLA)保證。研究支持團隊的經驗和專業知識。考慮附加服務,如昇級、故障排除和效能最佳化。權衡商業支援成本與風險緩解和提高效率。
 PHP 框架的學習曲線與其他語言框架相比如何?
Jun 06, 2024 pm 12:41 PM
PHP 框架的學習曲線與其他語言框架相比如何?
Jun 06, 2024 pm 12:41 PM
PHP框架的學習曲線取決於語言熟練度、框架複雜性、文件品質和社群支援。與Python框架相比,PHP框架的學習曲線較高,而與Ruby框架相比,則較低。與Java框架相比,PHP框架的學習曲線中等,但入門時間較短。
 綜述!全面概括基礎模型對於推動自動駕駛的重要作用
Jun 11, 2024 pm 05:29 PM
綜述!全面概括基礎模型對於推動自動駕駛的重要作用
Jun 11, 2024 pm 05:29 PM
写在前面&笔者的个人理解最近来,随着深度学习技术的发展和突破,大规模的基础模型(FoundationModels)在自然语言处理和计算机视觉领域取得了显著性的成果。基础模型在自动驾驶当中的应用也有很大的发展前景,可以提高对于场景的理解和推理。通过对丰富的语言和视觉数据进行预训练,基础模型可以理解和解释自动驾驶场景中的各类元素并进行推理,为驾驶决策和规划提供语言和动作命令。基础模型可以根据对驾驶场景的理解来实现数据增强,用于提供在常规驾驶和数据收集期间不太可能遇到的长尾分布中那些罕见的可行
 PHP 框架的輕量級選項如何影響應用程式效能?
Jun 06, 2024 am 10:53 AM
PHP 框架的輕量級選項如何影響應用程式效能?
Jun 06, 2024 am 10:53 AM
輕量級PHP框架透過小體積和低資源消耗提升應用程式效能。其特點包括:體積小,啟動快,記憶體佔用低提升響應速度和吞吐量,降低資源消耗實戰案例:SlimFramework創建RESTAPI,僅500KB,高響應性、高吞吐量
 golang框架文件最佳實踐
Jun 04, 2024 pm 05:00 PM
golang框架文件最佳實踐
Jun 04, 2024 pm 05:00 PM
編寫清晰全面的文件對於Golang框架至關重要。最佳實踐包括:遵循既定文件風格,例如Google的Go程式設計風格指南。使用清晰的組織結構,包括標題、子標題和列表,並提供導覽。提供全面且準確的信息,包括入門指南、API參考和概念。使用程式碼範例說明概念和使用方法。保持文件更新,追蹤變更並記錄新功能。提供支援和社群資源,例如GitHub問題和論壇。建立實際案例,如API文件。
 如何為不同的應用場景選擇最佳的golang框架
Jun 05, 2024 pm 04:05 PM
如何為不同的應用場景選擇最佳的golang框架
Jun 05, 2024 pm 04:05 PM
根據應用場景選擇最佳Go框架:考慮應用類型、語言特性、效能需求、生態系統。常見Go框架:Gin(Web應用)、Echo(Web服務)、Fiber(高吞吐量)、gorm(ORM)、fasthttp(速度)。實戰案例:建構RESTAPI(Fiber),與資料庫互動(gorm)。選擇框架:效能關鍵選fasthttp,靈活Web應用選Gin/Echo,資料庫互動選gorm。
 Java框架學習路線圖:不同領域中的最佳實踐
Jun 05, 2024 pm 08:53 PM
Java框架學習路線圖:不同領域中的最佳實踐
Jun 05, 2024 pm 08:53 PM
針對不同領域的Java框架學習路線圖:Web開發:SpringBoot和PlayFramework。持久層:Hibernate和JPA。服務端響應式程式設計:ReactorCore和SpringWebFlux。即時計算:ApacheStorm和ApacheSpark。雲端運算:AWSSDKforJava和GoogleCloudJava。
