

聊聊端到端與下一代自動駕駛系統,以及端到端自動駕駛的一些迷思?

最近一個月由於眾所周知的一些原因,非常密集地和行業內的各種老師同學進行了交流。交流中必不可免的一個話題自然是端到端與火爆的特斯拉 FSD V12。想藉此機會,整理當下這個時刻的一些想法和觀點,供大家參考和討論。

如何定義端對端的自動駕駛系統,應該期望端對端解決什麼問題?
依照最傳統的定義,端到端的系統指的是一套系統,輸入感測器的原始訊息,直接輸出任務關心的變數。例如,在影像辨識中,CNN相對於傳統的特徵提取器 分類器的方法就可以稱之為端到端。在自動駕駛任務中,輸入各種感知器的資料(相機/LiDAR/Radar/IMU等),直接輸出車輛行駛的控制訊號(油門/方向盤角度等)。為了考慮不同車型之間的適配問題,也可以將輸出放寬為車輛行駛的軌跡。這便是一種傳統意義上的定義,或者說是我所謂的做狹義端對端的定義。在這樣一個基礎上,也衍生出了一些中間任務的監督來提升性能能力。
然而,除了這樣狹義的定義之外,我們還應該從本質上思考一下,端到端的本質是什麼? 我認為端對端的本質應該是感知訊息的無損傳遞。我們先回想一下在非端到端系統中,感知和PnC模組的介面是什麼樣子的。一般我們會有針對白名單物體(車,人,etc)的偵測/屬性分析/預測,會有對靜態環境的理解(道路結構/限速/紅綠燈,etc),如果做的更細緻一些的話,還會做通用障礙物的一些檢測工作。 從宏觀的角度來講,感知輸出的這些訊息,都是對複雜駕駛場景的一種抽象,而且是人工定義的顯式抽象。然而,對於一些非常見場景中,現在的顯式抽象難以充分錶達場景中會影響駕駛行為的因素,亦或是我們需要定義的任務過多過瑣碎,也難以枚舉盡所有需要的任務。所以端到端系統,提供了一種(也許是隱式)全面表示,希望能夠自動地無損地將這樣的資訊作用於PnC。我認為,所有能滿足這樣的系統,都可以叫做廣義端對端。
對於其他的問題,例如對動態互動場景的一些最佳化,我個人的觀點認為至少並非只有端到端才能解決這些問題,傳統方法是可以解決好這些問題的。當然,在資料量夠大的時候,端到端可能會提供一個還不錯的solution。關於這個事情是否有必要,會在後幾個問題中展開討論。

關於端對端自動駕駛的一些誤解?
一定要輸出控制訊號和路點才是端到端
#對於廣義端到端的概念,如果能認同上面所講的概念,那麼這個問題就很容易理解了。端到端的強調的是訊息的無損傳遞,而不是一定要直接輸出任務量。這樣的端到端處理方法需要大量的兜底方案來確保安全,而且在實作過程中也會遇到一些問題,在後續處理中會逐漸展開。
端對端系統一定要基於大模型或純視覺
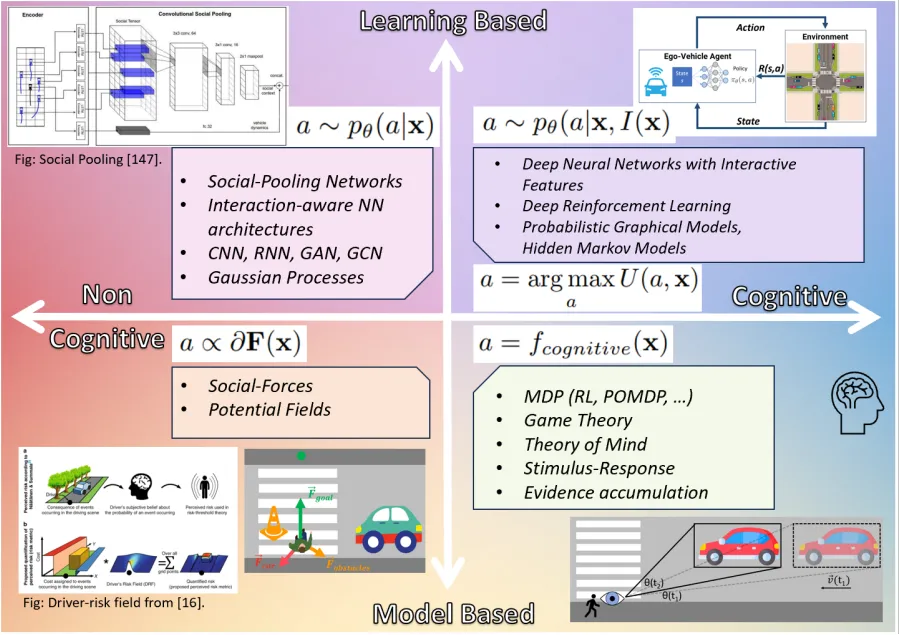
#端對端自動駕駛的概念和大模型自動駕駛以及純視覺自動駕駛沒有任何必然的關聯。這三個概念是完全獨立存在的,一個端到端的系統不必一定是傳統意義上的大模型驅動的,也不一定是純粹視覺。三者之間有些關聯,但不等同。
之前我有一篇文章詳細闡述過這些概念之間的關係,詳見:https://zhuanlan.zhihu.com/p/664189972
長遠來看,上述狹義的端對端系統有沒有可能達到L3等級以上自動駕駛?
其實我先想來吐槽一句,號稱要用大模型來顛覆L4的人,都沒有實際做過L4;號稱端到端包治百病的人,也都從來沒做過PnC。於是和許多對端到端狂熱的人聊下來,就變成了一個純粹的無法證實也無法證偽的宗教信仰之爭。我們做前沿研發的同學,還是應該更實事求是,講究證據一些。 。 。最起碼對想要顛覆的東西有一些基礎認知和了解其中棘手的問題,這是應該有的基本科學素質。 。 。
言歸正傳,目前來看,我是悲觀的。暫且不論目前號稱是純端到端的FSD,性能還遠遠不能達到L3級別以上所需的可靠性和穩定性,未來就算是統計意義上這個車輛和人類是一樣安全的,還要面臨如何和人類駕駛員的錯誤做align的問題。更直白一點來說,就是說,一個自動駕駛系統想要讓大眾和輿論接受,關鍵可能不在於一個絕對的事故率和致死率,而是在於大眾是否能接受有一些場景中,對於人類是相對輕鬆解決,而機器會犯錯的。這個需求對於純端到端系統來說更難以實現。更具體的在我21年的一個回答中有闡述,詳見:
如何看待李彥宏朋友圈發表:無人駕駛肯定會出事,只是這個機率比有人駕駛低多了?
https://www.zhihu.com/question/530828899/answer/2590673435?utm_psn=1762524415009697792
#在北美的Waymo和Cruise為例,其實分別都沒有出過不少事故,但是為什麼Cruise最後一次出現的事故讓監管和大眾尤為不能接受呢?這起事故發生了兩次傷害,第一次的碰撞,對於人類駕駛也是相當難以避免的,其實也是可以接受的。但在這次的碰撞發生之後,發生了嚴重的二次傷害:系統錯誤地判斷了碰撞位置和傷員位置,為了不阻塞交通,降級到了靠邊停車的模式,將傷員拖拽很久。這樣的一個行為,是任何一個正常的人類駕駛員都不會做出的事情,而且影響非常惡劣。這個事情直接導致了Cruise後續的一些動盪。這個事情其實也給我們敲響了警鐘,如何避免這樣的事情發生,應該是自動駕駛系統研發和營運上認真考慮的問題。
那麼站在現在的這個時刻,下一代量產輔助駕駛系統中切實可行的方案是什麼?
簡單來說,我認為一個合適的系統應該是先充分挖掘傳統系統的能力上限,然後再去結合端到端的靈活和普適性,也就是一個漸進式端對端的方案。當然這兩者如何有機地結合就是個付費內容了,哈哈。 。 。但我們可以分析一下,現在所謂的端到端或是learning based planner實際落地在做的事情是什麼。
以我有限的了解,目前所謂端到端模型在行車中使用的時候,在輸出的軌跡之後都會去接一個基於傳統方法兜底的方案,或者是這樣的learning based planner和傳統的軌跡規劃演算法會同時輸出多條軌跡,再透過一個selector來選擇一條執行。如果這樣設計系統架構,這麼一個級連繫統的效能上限其實是被這樣的兜底方案和selector限制住的。如果這樣的方案仍然是基於純feedforward learning的,仍會有不可預測的失效,本質上並不能達到兜底的目的。如果考慮在這樣輸出的軌跡上使用一個傳統的規劃方法再去優化或選擇,那相當於learning based方法出的軌跡,只是給這樣的一個最佳化和搜尋問題做了一個初始解,我們為何不直接去優化和搜尋這樣的軌跡呢?
當然有同學會跳出來講,這樣的一個優化或搜尋問題是非凸的,狀態空間很大不可能在車載系統上跑到即時。我請大家在這裡仔細想這樣一個問題:在過去10年中,感知系統至少吃到了100x的算力紅利發展,但是我們的PnC模組呢?如果我們同樣允許PnC模組使用大算力,結合上近幾年先進優化演算法的一些發展,這樣的結論仍然成立嗎?針對這樣的問題,我們不應該固步自封,路徑依賴,而是從第一原理思考什麼才是對的。

数据驱动和传统方法之间关系如何调和?
其实和自动驾驶非常类似的一个例子就是下棋,刚好在今年2月份的时候Deepmind发表了一篇文章(Grandmaster-Level Chess Without Search:https://arxiv.org/abs/2402.04494)就在探索只用数据驱动,抛弃AlphaGo和AlphaZero中的MCTS search是否可行。类比到自动驾驶中就是,只用一个网络直接输出action,抛弃掉后续所有的步骤。文章的结论是,在相当的规模的数据和模型参数下,不用搜索仍然可以得到一个还算合理的结果,然而和加上搜索的方法比,还有非常显著的差距。(文章中这里的对比其实也不尽公平,实际差距应该更大)尤其是在解一些困难的残局上,纯数据驱动性能非常糟糕。这类比到自动驾驶中,也就是意味着,需要多步博弈的困难场景或corner case,仍然很难完全抛弃掉传统的优化或者搜索算法。像AlphaZero一样合理地运用各种技术的优势,才是最为高效提升性能的方式。
传统方法 = rule based if else?
这个观念也是我在和很多人的交流中需要反复纠正的。按照很多人的定义,只要不是纯数据驱动,就叫做rule based。还是举下棋这个例子,去死记硬背定式和棋谱是rule based,但是像AlphaGo和AlphaZero一样通过搜索和优化赋予模型reasoning的能力,我认为并不能叫做rule based。这恰恰也是目前大模型本身所欠缺的,也是研究者通过CoT等方式试图赋予一个learning based model的。然而人开车每一个动作都是有明确的动机的,这和需要纯数据驱动的图像识别等无法清晰描述原因的任务不同。在一个合适的算法架构设计下,决策轨迹都应该成为变量,在一个科学的目标指引下统一优化。而不是通过强行打patch和调参去修各种case。这样的一个系统自然也不会存在各种hardcode的奇怪的rule。
总结
最终总结一下,端到端也许是一个很有希望的技术路线,但是这样一个概念如何付诸实践还有很多有待探索的事情。是不是狂堆数据和模型参数就是唯一正确的解决方案,目前在我看来并不是的。我觉得,任何时刻作为一个前沿研究的技术人员,我们都应该真正奉行马斯克所讲的第一性原理和工程师思维,从实践中思考问题的本质,而不是将马斯克本身变成第一性原理。想要真正遥遥领先,就不应该放弃思考,人云亦云,否则就只能在不断想要弯道超车。
以上是聊聊端到端與下一代自動駕駛系統,以及端到端自動駕駛的一些迷思?的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 為何在自動駕駛方面Gaussian Splatting如此受歡迎,開始放棄NeRF?
Jan 17, 2024 pm 02:57 PM
為何在自動駕駛方面Gaussian Splatting如此受歡迎,開始放棄NeRF?
Jan 17, 2024 pm 02:57 PM
寫在前面&筆者的個人理解三維Gaussiansplatting(3DGS)是近年來在顯式輻射場和電腦圖形學領域出現的一種變革性技術。這種創新方法的特點是使用了數百萬個3D高斯,這與神經輻射場(NeRF)方法有很大的不同,後者主要使用隱式的基於座標的模型將空間座標映射到像素值。 3DGS憑藉其明確的場景表示和可微分的渲染演算法,不僅保證了即時渲染能力,而且引入了前所未有的控制和場景編輯水平。這將3DGS定位為下一代3D重建和表示的潛在遊戲規則改變者。為此我們首次系統性地概述了3DGS領域的最新發展與關
 自動駕駛場景中的長尾問題怎麼解決?
Jun 02, 2024 pm 02:44 PM
自動駕駛場景中的長尾問題怎麼解決?
Jun 02, 2024 pm 02:44 PM
昨天面試被問到了是否做過長尾相關的問題,所以就想著簡單總結一下。自動駕駛長尾問題是指自動駕駛汽車中的邊緣情況,即發生機率較低的可能場景。感知的長尾問題是目前限制單車智慧自動駕駛車輛運行設計域的主要原因之一。自動駕駛的底層架構和大部分技術問題已經解決,剩下的5%的長尾問題,逐漸成了限制自動駕駛發展的關鍵。這些問題包括各種零碎的場景、極端的情況和無法預測的人類行為。自動駕駛中的邊緣場景"長尾"是指自動駕駛汽車(AV)中的邊緣情況,邊緣情況是發生機率較低的可能場景。這些罕見的事件
 選擇相機還是光達?實現穩健的三維目標檢測的最新綜述
Jan 26, 2024 am 11:18 AM
選擇相機還是光達?實現穩健的三維目標檢測的最新綜述
Jan 26, 2024 am 11:18 AM
0.寫在前面&&個人理解自動駕駛系統依賴先進的感知、決策和控制技術,透過使用各種感測器(如相機、光達、雷達等)來感知周圍環境,並利用演算法和模型進行即時分析和決策。這使得車輛能夠識別道路標誌、檢測和追蹤其他車輛、預測行人行為等,從而安全地操作和適應複雜的交通環境。這項技術目前引起了廣泛的關注,並認為是未來交通領域的重要發展領域之一。但是,讓自動駕駛變得困難的是弄清楚如何讓汽車了解周圍發生的事情。這需要自動駕駛系統中的三維物體偵測演算法可以準確地感知和描述周圍環境中的物體,包括它們的位置、
 你是否真正掌握了座標系轉換?自動駕駛離不開的多感測器問題
Oct 12, 2023 am 11:21 AM
你是否真正掌握了座標系轉換?自動駕駛離不開的多感測器問題
Oct 12, 2023 am 11:21 AM
一先導與重點文章主要介紹自動駕駛技術中幾種常用的座標系統,以及他們之間如何完成關聯與轉換,最終建構出統一的環境模型。這裡重點理解自車到相機剛體轉換(外參),相機到影像轉換(內參),影像到像素有單位轉換。 3d向2d轉換會有對應的畸變,平移等。重點:自車座標系相機機體座標系需要被重寫的是:平面座標系像素座標系難點:要考慮影像畸變,去畸變和加畸變都是在像平面上去補償二簡介視覺系統一共有四個座標系:像素平面座標系(u,v)、影像座標系(x,y)、相機座標系()與世界座標系()。每種座標系之間均有聯繫,
 SIMPL:用於自動駕駛的簡單高效的多智能體運動預測基準
Feb 20, 2024 am 11:48 AM
SIMPL:用於自動駕駛的簡單高效的多智能體運動預測基準
Feb 20, 2024 am 11:48 AM
原文標題:SIMPL:ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving論文連結:https://arxiv.org/pdf/2402.02519.pdf程式碼連結:https://github.com/HKUST-Aerial-Robotics/SIMPLobotics單位論文想法:本文提出了一種用於自動駕駛車輛的簡單且有效率的運動預測基線(SIMPL)。與傳統的以代理為中心(agent-cent
 FisheyeDetNet:首個以魚眼相機為基礎的目標偵測演算法
Apr 26, 2024 am 11:37 AM
FisheyeDetNet:首個以魚眼相機為基礎的目標偵測演算法
Apr 26, 2024 am 11:37 AM
目標偵測在自動駕駛系統當中是一個比較成熟的問題,其中行人偵測是最早得以部署演算法之一。在多數論文當中已經進行了非常全面的研究。然而,利用魚眼相機進行環視的距離感知相對來說研究較少。由於徑向畸變大,標準的邊界框表示在魚眼相機當中很難實施。為了緩解上述描述,我們探索了擴展邊界框、橢圓、通用多邊形設計為極座標/角度表示,並定義一個實例分割mIOU度量來分析這些表示。所提出的具有多邊形形狀的模型fisheyeDetNet優於其他模型,並同時在用於自動駕駛的Valeo魚眼相機資料集上實現了49.5%的mAP
 自動駕駛與軌跡預測看這篇就夠了!
Feb 28, 2024 pm 07:20 PM
自動駕駛與軌跡預測看這篇就夠了!
Feb 28, 2024 pm 07:20 PM
軌跡預測在自動駕駛中承擔著重要的角色,自動駕駛軌跡預測是指透過分析車輛行駛過程中的各種數據,預測車輛未來的行駛軌跡。作為自動駕駛的核心模組,軌跡預測的品質對於下游的規劃控制至關重要。軌跡預測任務技術堆疊豐富,需熟悉自動駕駛動/靜態感知、高精地圖、車道線、神經網路架構(CNN&GNN&Transformer)技能等,入門難度很高!許多粉絲期望能夠盡快上手軌跡預測,少踩坑,今天就為大家盤點下軌跡預測常見的一些問題和入門學習方法!入門相關知識1.預習的論文有沒有切入順序? A:先看survey,p
 聊聊端到端與下一代自動駕駛系統,以及端到端自動駕駛的一些迷思?
Apr 15, 2024 pm 04:13 PM
聊聊端到端與下一代自動駕駛系統,以及端到端自動駕駛的一些迷思?
Apr 15, 2024 pm 04:13 PM
最近一個月由於眾所周知的一些原因,非常密集地和業界的各種老師同學進行了交流。交流中必不可免的一個話題自然是端到端與火辣的特斯拉FSDV12。想藉此機會,整理當下這個時刻的一些想法和觀點,供大家參考和討論。如何定義端到端的自動駕駛系統,應該期望端到端解決什麼問題?依照最傳統的定義,端到端的系統指的是一套系統,輸入感測器的原始訊息,直接輸出任務關心的變數。例如,在影像辨識中,CNN相對於傳統的特徵提取器+分類器的方法就可以稱之為端到端。在自動駕駛任務中,輸入各種感測器的資料(相機/LiDAR
