

作者| 陳旭鵬
由於神經系統的缺陷導致的失語症會導致嚴重的生活障礙,它可能會限制人們的職業和社交生活。
近年來,深度學習和腦機介面(BCI)技術的快速發展為開發能夠幫助失語者溝通的神經語音義肢提供了可行性。然而,神經訊號的語音解碼面臨挑戰。
近日,約旦大學VideoLab和Flinker Lab的研究者開發了一個新型的可微分語音合成器,可以利用一個輕型的捲積神經網路將語音編碼為一系列可解釋的語音參數(例如音高、響度、共振峰頻率等),並透過可微分神經網路將這些參數合成為語音。這個合成器還可以透過一個輕型的捲積神經網路來解析語音參數(例如音高、響度、共振峰頻率等),以及通 過可微分語音合成器重新合成語音。
研究者建立了一個高度可解釋且可應用於小數據量情形的神經訊號解碼系統,透過將神經訊號映射到這些語音參數,而不改變原內容的意思。
研究以「A neural speech decoding framework leveraging deep learning and speech synthesis」為題,於2024 年4 月8 日發表在《Nature Machine Intelligence 》雜誌上。

論文連結:https://www.nature.com/articles/s42256-024-00824-8
#研究背景
開發神經-語音解碼器的嘗試大多數依賴於一種特殊的數據:透過皮質電圖(ECoG)記錄獲取接受癲癇手術患者的數據。利用患有癲癇的患者植入的電極,在發音時收集大腦皮層數據,這些數據具有高時空分辨率,已經在語音解碼領域幫助研究者獲得了一系列很顯著的成果,幫助推動了腦機接口領域的發展。
神經訊號的語音解碼面臨兩大挑戰。
首先,用於訓練個人化神經到語音解碼模型的資料在時間上是非常有限的,通常只有十分鐘左右,而深度學習模型往往需要大量的訓練資料來驅動。
其次,人類的發音非常多樣,即使是同一個人重複說出相同的單詞,語速、語調和音調等也會有變化,這給模型構建的表徵空間增加了複雜性。
早期的解碼神經訊號到語音的嘗試主要依賴線性模型,模型通常不需要龐大的訓練資料集,可解釋性強,但是準確率很低。
近期的基於深度神經網絡,尤其是利用卷積和循環神經網路架構,在模擬語音的中間潛在表示和合成後語音品質兩個關鍵維度上展開。例如,有研究將大腦皮質活動解碼成口型運動空間,然後再轉化為語音,雖然解碼性能強大,但重建的聲音聽起來不自然。
另一方面,有些方法透過利用wavenet聲碼器、生成對抗網路(GAN)等,雖然成功重建了自然聽感的語音,但準確度有限。最近,在一個植入了設備的患者的研究中,透過使用量化的HuBERT特徵作為中間表示空間和預訓練的語音合成器將這些特徵轉換成語音,實現了既準確又自然的語音波形。
然而,HuBERT特徵不能表示發音者特有的聲學訊息,只能產生固定統一的發音者聲音,因此需要額外的模型將這種通用聲音轉換為特定患者的聲音。此外,這項研究和大多數先前的嘗試採用了非因果(non-causal)架構,這可能限制其在需要時序因果(causal)操作的腦機介面實際應用中的使用。
主要模型架構
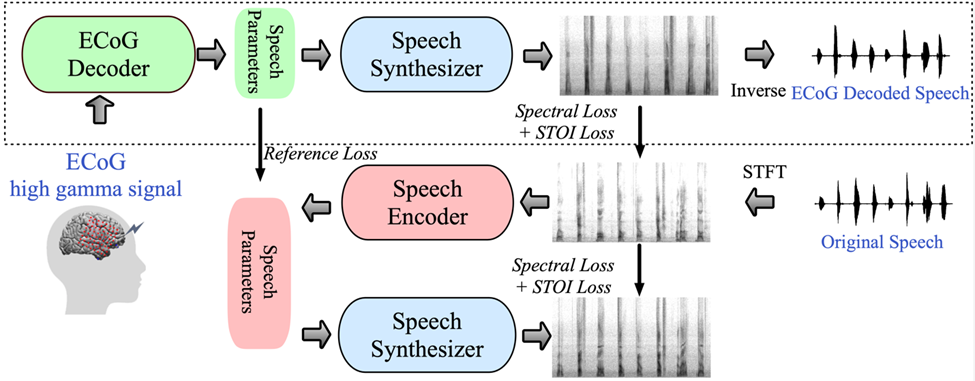
為應對這些挑戰,研究者在這篇文章中介紹了一個新型的從腦電(ECoG)訊號到語音的解碼框架,研究人員建構了一個低維度的中間表示(low dimension latent representation),該表示透過僅使用語音訊號的語音編解碼模型產生(圖1)。
研究提出的框架由兩部分組成:一部分是ECoG解碼器,它能將ECoG訊號轉換為我們可以理解的聲學語音參數(例如音高、是否發聲、響度、以及共振峰頻率等);另一部分是語音合成器,它將這些語音參數轉換為頻譜圖。
研究者らは、微分可能な音声合成器を構築しました。これにより、音声合成器は ECoG デコーダのトレーニング中にトレーニングに参加し、スペクトログラム再構成のエラーを減らすために共同で最適化することができます。この低次元潜在空間は、参照音声パラメータを生成するための軽量の事前トレーニング済み音声エンコーダと組み合わせることで強力な解釈可能性を備えており、研究者が効率的なニューラル音声復号化フレームワークを構築し、データ不足の問題を克服するのに役立ちます。
このフレームワークは、話者自身の声に非常に近い自然な音声を生成でき、ECoG デコーダー部分はさまざまな深層学習モデル アーキテクチャに接続でき、因果的操作もサポートします。研究者らは、ECoG デコーダーとして複数の深層学習アーキテクチャ (畳み込み、リカレント ニューラル ネットワーク、トランスフォーマーを含む) を使用して、48 人の脳神経外科患者から ECoG データを収集および処理しました。
このフレームワークはさまざまなモデルで高い精度を実証しており、畳み込み (ResNet) アーキテクチャで得られる最高のパフォーマンスでは、元のスペクトログラムとデコードされたスペクトログラム間のピアソン相関係数 (PCC) が 0.806 に達しました。研究者らによって提案されたフレームワークは、因果的操作と比較的低いサンプリング レート (低密度、10 mm 間隔) を通じてのみ高精度を達成できます。
研究者らはまた、効果的な音声デコードが脳の左半球と右半球の両方から実行できることを実証し、神経音声デコードの応用を右半球に拡張しました。
研究関連コードのオープンソース:https://github.com/flinkerlab/neural_speech_decoding
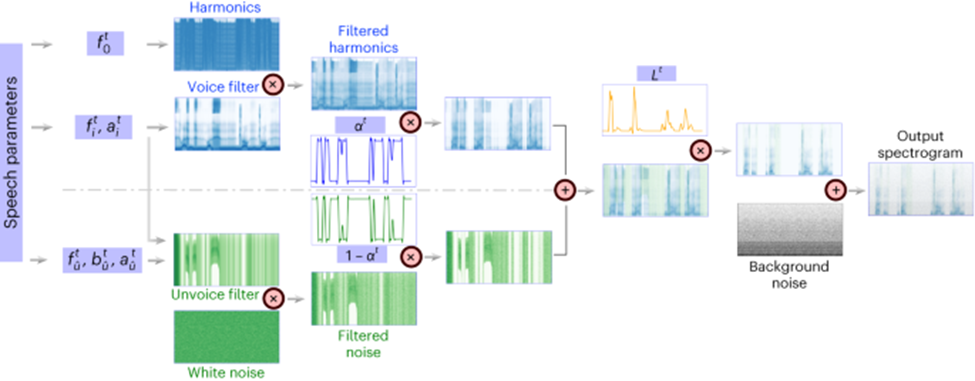
この研究の重要な革新は、音声再合成タスクを非常に効率的にし、非常に小さな音声で高忠実度に合成できる微分可能な音声合成装置 (音声合成装置) を提案することです。原音と一致するオーディオ。
微分可能音声合成の原理は、人間の生成システムの原理を利用し、音声を 2 つの部分 (母音のモデル化に使用) と無声 (子音のモデル化に使用) の 2 つの部分に分割します。
音声部分は、まず基本周波数信号を使用して高調波を生成し、F1 ~ F6 のフォルマントで構成されるフィルターでフィルタリングして、無声部分の母音部分のスペクトル特性を取得します。研究者は対応するフィルターを使用します。ホワイトノイズに対応するスペクトルがフィルタリングによって取得され、学習可能なパラメータによって各瞬間の 2 つの部分の混合比を調整できます。その後、ラウドネス信号が増幅され、バックグラウンドノイズが追加されて、最終的な音声スペクトルが取得されます。この音声合成装置に基づいて,本論文は効率的な音声再合成フレームワークとニューラル音声復号化フレームワークを設計した。
研究結果
時間的因果関係を伴う音声解読結果
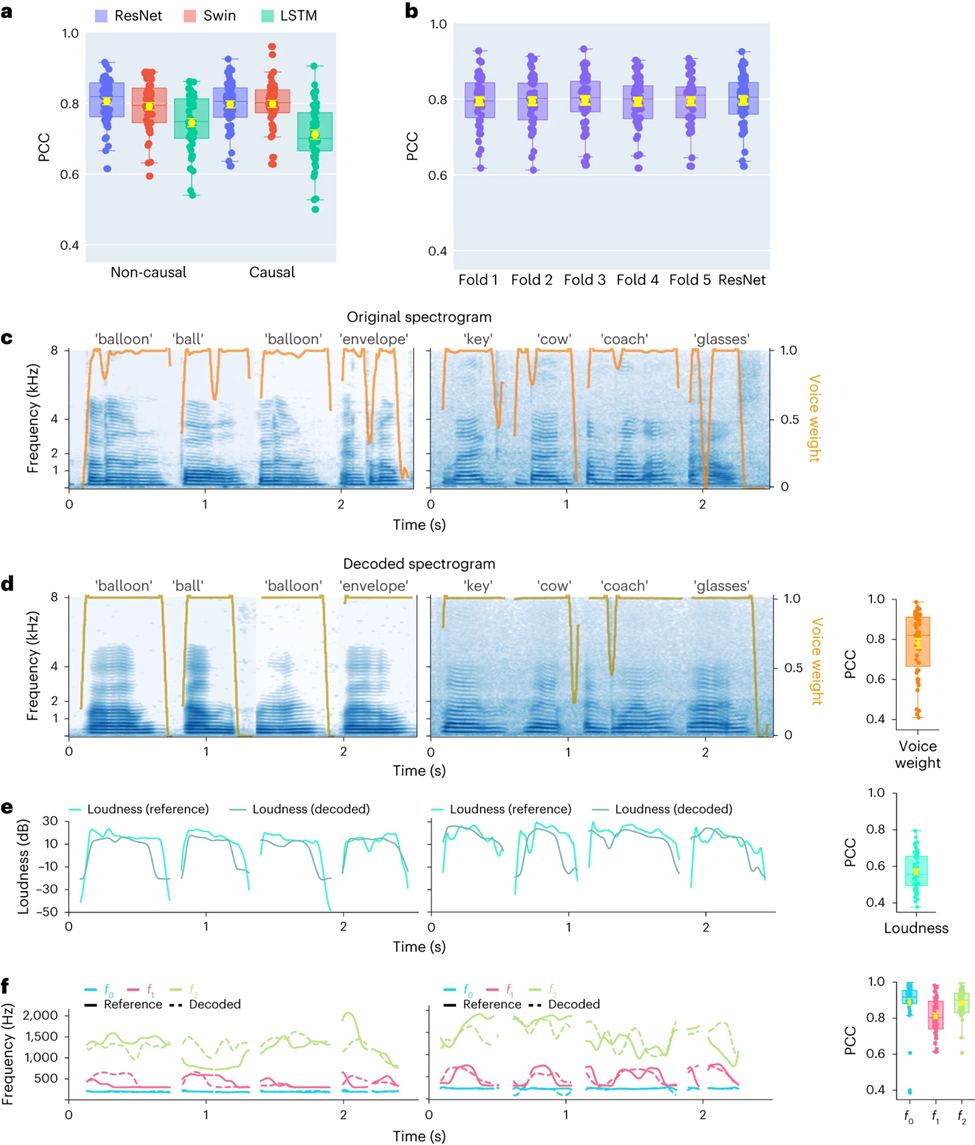
。
さらに、研究者らは、2 人の参加者 (低密度サンプリング レート ECoG) からのデータを示し、単一ワード レベルでの ResNet 因果デコーダーのパフォーマンスを実証しています。デコードされたスペクトログラムは、元の音声のスペクトル時間構造を正確に保持しています (図 2c、d)。
研究者らはまた、ニューラル デコーダーによって予測された音声パラメーターと、音声エンコーダーによってエンコードされたパラメーター (参考値として) を比較し、いくつかの主要な音声パラメーター (N=48) の平均 PCC 値を示しました。 )、音の重み (母音と子音を区別するために使用)、ラウドネス、ピッチ f0、第 1 フォルマント f1 および第 2 フォルマント f2 が含まれます。これらの音声パラメータ、特にピッチ、音の重み、最初の 2 つのフォルマントを正確に再構成することは、参加者の声を自然に模倣する正確な音声デコードと再構成を実現するために重要です。
研究結果は、非因果モデルと因果モデルの両方が合理的な解読結果を取得できることを示しており、これは将来の研究と応用に前向きな指針を提供します。
音声デコードと左脳・右脳神経信号の空間サンプリングレートに関する研究
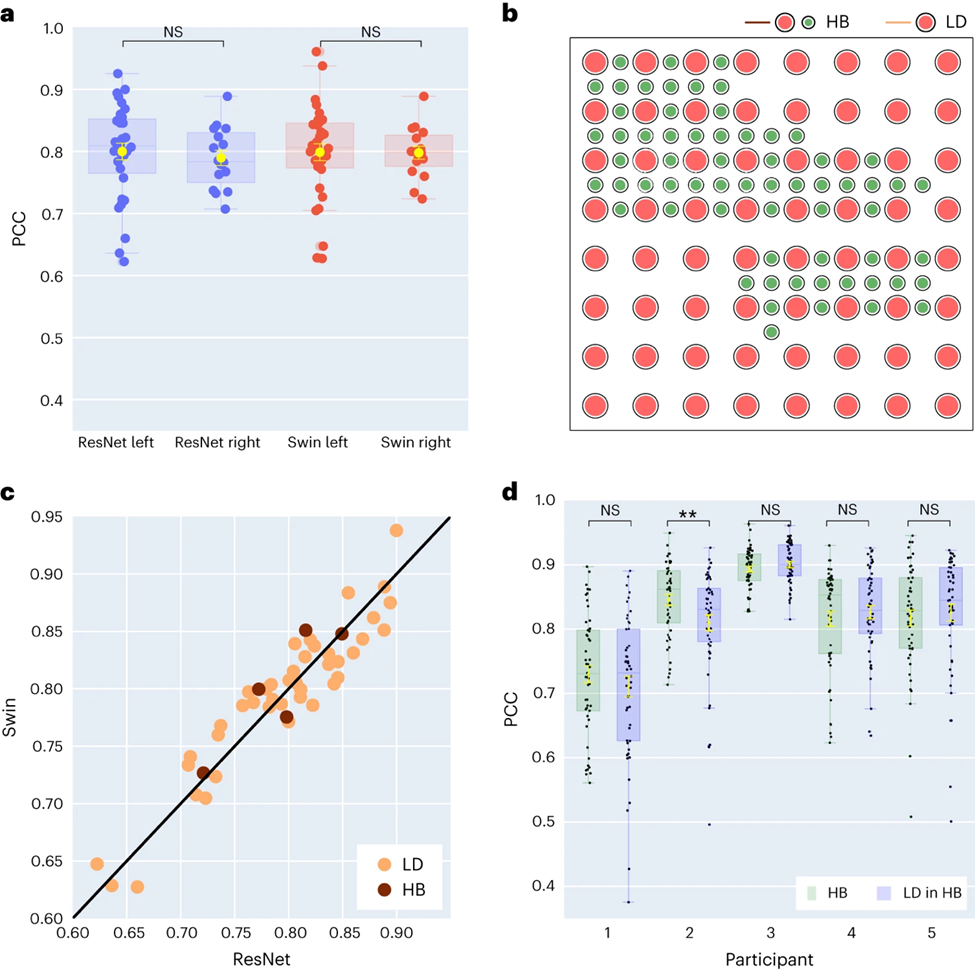
研究者らはさらに、左右の大脳半球の音声解読結果を比較しました。ほとんどの研究は、音声と言語の機能を担う脳の左半球に焦点を当てています。しかし、右脳半球から言語情報がどのように解読されるかについてはほとんどわかっていません。これに応えて、研究者らは参加者の左右の大脳半球のデコード性能を比較し、音声回復に右大脳半球を使用できる可能性を検証した。
研究で収集された 48 人の被験者のうち、16 人の被験者は右脳から ECoG 信号を収集しました。 ResNet と Swin デコーダーのパフォーマンスを比較することにより、研究者らは、右半球でも音声を安定してデコードできる (ResNet の PCC 値は 0.790、Swin の PCC 値は 0.798) ことがわかり、これは左半球のデコード効果とあまり変わらないことを発見しました (図 3a) に示されています。
この発見は、STOI の評価にも当てはまります。これは、左半球に損傷があり言語能力を失った患者にとって、右半球からの神経信号を使用して言語を回復することが実現可能な解決策である可能性があることを意味します。
次に、研究者らは、音声デコード効果に対する電極サンプリング密度の影響を調査しました。以前の研究では主に高密度の電極グリッド (0.4 mm) が使用されていましたが、臨床現場で一般的に使用されている電極グリッドの密度はより低い (LD 1 cm) です。
5 人の参加者は、主に低密度のサンプリングですが、追加の電極が組み込まれたハイブリッド タイプ (HB) 電極グリッド (図 3b を参照) を使用しました。残りの 43 人の参加者は低密度でサンプリングされました。これらのハイブリッド サンプル (HB) のデコード パフォーマンスは、従来の低密度サンプル (LD) と同様ですが、STOI ではわずかに優れています。
研究者らは、デコードに低密度電極のみを使用した場合とすべての混合電極を使用した場合の効果を比較し、両者の差は有意ではないことを発見しました (図 3d を参照)。さまざまな空間からのサンプル密度 音声情報は大脳皮質で学習されますが、このことは、臨床現場で一般的に使用されるサンプリング密度が将来のブレイン-コンピューター インターフェイスのアプリケーションには十分である可能性があることも意味します。
音声デコーディングに対する左脳と右脳の異なる脳領域の寄与に関する研究
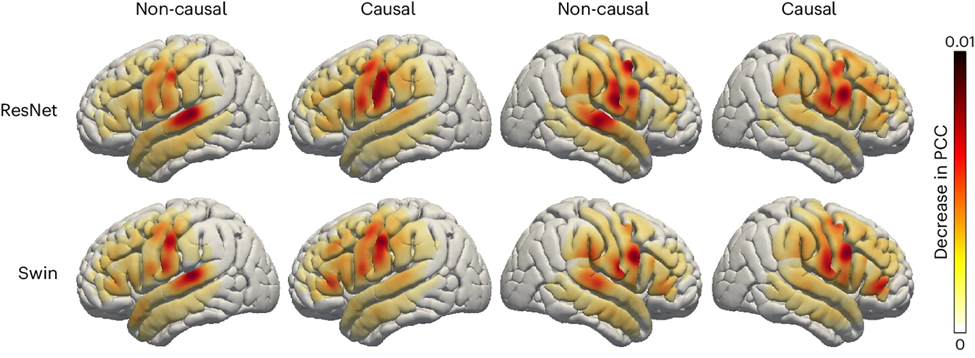
最後に、研究者らは音声復号化プロセスにおける脳の音声関連領域の寄与を調べました。これは、将来の左右への音声復元装置の埋め込みにとって重要な参考資料となります。脳の半球。研究者らは、オクルージョン分析を使用して、音声デコードに対するさまざまな脳領域の寄与を評価しました。
つまり、特定の領域がデコードに重要な場合、その領域の電極信号をブロックすると (つまり、信号をゼロに設定すると)、再構成された音声の精度 (PCC 値) が低下します。
この方法を使用して、研究者らは各領域が閉塞されたときの PCC 値の減少を測定しました。 ResNet と Swin デコーダの因果モデルと非因果モデルを比較すると、聴覚皮質が非因果モデルでより多く寄与していることがわかり、リアルタイム音声デコード アプリケーションでは因果モデルを使用する必要があることが強調されます。リアルタイム音声デコードでは、ニューロフィードバック信号を利用できません。
さらに、感覚運動皮質、特に腹部の寄与は右半球でも左半球でも同様であり、右半球に神経プロテーゼを移植することが可能である可能性があることを示唆しています。
結論と感動的な展望
研究者らは、軽量畳み込みニューラル ネットワークを使用して音声を一連の解釈可能な音声パラメータにエンコードできる、新しいタイプの微分可能な音声合成装置を開発しました。 (ピッチ、ラウドネス、フォルマント周波数など)、微分可能な音声合成装置を通じて音声を再合成します。
研究者らは、神経信号をこれらの音声パラメータにマッピングすることで、解釈可能性が高く、データ量が少ない状況にも適用でき、自然な音声を生成できるニューラル音声デコード システムを構築しました。この方法は参加者 (合計 48 人) 全体で再現性が高く、研究者らは、リカレント アーキテクチャ (LSTM) よりも優れている畳み込みおよびトランスフォーマー (3D Swin) アーキテクチャを使用した因果解読の有効性を実証することに成功しました。
このフレームワークは、高い空間サンプリング密度と低い空間サンプリング密度を処理でき、左半球と右半球からの EEG 信号を処理できるため、強力な音声デコードの可能性が示されます。
これまでの研究のほとんどは、リアルタイムのブレイン-コンピューター インターフェイス アプリケーションにおけるデコード操作の時間的因果関係を考慮していませんでした。多くの非因果モデルは、聴覚感覚フィードバック信号に依存しています。研究者らの分析では、非因果モデルは主に上側頭回の寄与に依存しているのに対し、因果モデルは基本的にこれを排除していることが示された。研究者らは、フィードバック信号に過度に依存しているため、リアルタイム BCI アプリケーションにおける非因果モデルの汎用性が制限されていると考えています。
一部の方法では、被験者の想像上の音声を解読するなど、トレーニング中のフィードバックを回避しようとします。それにもかかわらず、ほとんどの研究は依然として非因果モデルを採用しており、トレーニングと推論中のフィードバック効果を排除できません。さらに、文献で広く使用されているリカレント ニューラル ネットワークは通常双方向であるため、非因果的な動作や予測遅延が発生しますが、私たちの実験では、一方向にトレーニングされたリカレント ネットワークのパフォーマンスが最悪であることが示されています。
この研究ではリアルタイムのデコードはテストされていませんが、研究者らは神経信号から音声を合成する際に 50 ミリ秒未満の遅延を達成し、聴覚遅延にはほとんど影響せず、通常の音声生成が可能でした。
この研究では、カバレージの密度を高めることでデコードのパフォーマンスが向上するかどうかを調査しました。研究者らは、低密度と高密度のグリッド カバレッジの両方で高いデコード パフォーマンスが達成されることを発見しました (図 3c を参照)。さらに、研究者らは、すべての電極を使用した場合のデコード性能は、低密度電極のみを使用した場合の性能と大きく変わらないことを発見しました (図 3d)。
これは、低密度の参加者であっても、手頭周囲のカバレージが十分である限り、研究者が提案した ECoG デコーダは音声を再構成するために神経信号から音声パラメータを抽出できることを証明しています。もう一つの注目すべき発見は、右半球の皮質構造と、音声解読に対する右頭頭周囲皮質の寄与でした。これまでのいくつかの研究では、右半球が母音と文の解読に寄与している可能性があることが示されていますが、今回の結果は、右半球における堅牢な音韻表現の証拠を提供しています。
研究者らは、現在のモデルのいくつかの制限についても言及しました。たとえば、デコードプロセスには ECoG 録音と組み合わせた音声トレーニングデータが必要ですが、これは失語症患者には適用できない可能性があります。将来的には、研究者らは、非グリッド データを処理し、複数の患者、マルチモーダルな EEG データをより適切に活用できるモデル アーキテクチャを開発したいと考えています。
この記事の筆頭著者: Xupeng Chen、Ran Wang、責任著者: Adeen Flinker。
資金援助: 国立科学財団 (助成金番号 IIS-1912286、2309057 (Y.W.、A.F.) および国立衛生研究所 R01NS109367、R01NS115929、R01DC018805 (A.F.)) 。
神経音声デコードにおける因果関係の詳細については、著者による別の論文「分散型フィードフォワードおよびフィードバック皮質処理が人間の音声生成をサポートする」を参照してください: https :/ /www.pnas.org/doi/10.1073/pnas.2300255120
出典: ブレイン コンピューター インターフェイス コミュニティ
以上是AI輔助腦機介面研究,紐約大學突破性神經語音解碼技術,登Nature子刊的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















