

谷歌出手整頓大模型「健忘症」!回饋注意力機制幫你「更新」上下文,大模型無限記憶力時代將至

编辑|伊风
出品 | 51CTO技术栈(微信号:blog51cto)
谷歌终于出手了!我们将不再忍受大模型的“健忘症”。
TransformerFAM横空出世,放话要让大模型拥有无限记忆力!
话不多说,先来看看TransformerFAM的“疗效”:
 图片
图片
大模型在处理长上下文任务时的性能得到了显著提升!
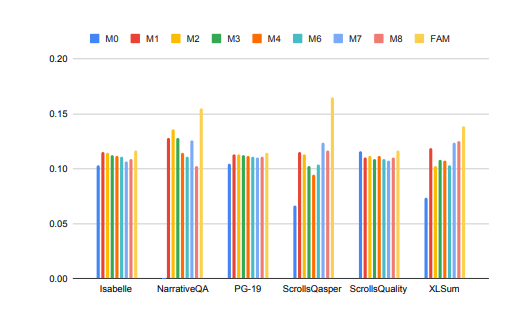
在上图中,Isabelle、NarrativeQA等任务要求模型理解和处理大量上下文信息,并对特定问题给出准确的回答或摘要。在所有任务中,FAM配置的模型都优于所有其他BSWA配置,并且能够看到当超过某个点时,BSWA记忆段数量的增加已经无法继续提升其记忆能力。
看来,在卷长文本、长对话的路上,FAM这颗大模型的“忘不了”确实有点东西。
Google的研究人员介绍了FAM这种新颖的Transformer架构——Feedback Attention Memory。它利用反馈循环使网络能够关注自身的漂移表现,促进Transformer内部工作记忆的出现,并使其能够处理无限长的序列。
简单点说,这个策略有点像我们人工对抗大模型“失忆”的策略:每次和大模型对话前都再输入一次prompt。只不过FAM的做法更高阶一些,在模型处理新的数据块时,它会将之前处理过的信息(即FAM)作为一个动态更新的上下文,再次整合到当前的处理过程中。
这样就能很好地应对“爱忘事”的问题了。更妙的是,尽管引入了反馈机制来维持长期的工作记忆,但FAM的设计旨在保持与预训练模型的兼容性,不需要额外的权重。所以理论上说,大模型的强大记忆力,没有使其变得迟钝或者消耗更多的算力资源。
那么,这么妙的TransformerFAM是如何被探索出来的?相关技术又是啥?
一、从挑战中来,TransformerFAM为何能帮助大模型“记住更多”?
滑动窗口注意力(Sliding Window Attention, SWA)这个概念,对TransformerFAM的设计至关重要。
在传统的Transformer模型中,自注意力(Self-Attention)的复杂度随着序列长度的增加而呈二次方增长,这限制了模型处理长序列的能力。
“在电影《记忆碎片》(2000 年)中,主角患有顺行性遗忘症,这意味着他无法记住过去 10 分钟发生的事情,但他的长期记忆是完好的,他不得不将重要信息纹在身上以记住它们。这与当前大型语言模型(LLMs)的状态类似,”论文中这样写道。
 《记忆碎片》电影截图,图片源于网络
《记忆碎片》电影截图,图片源于网络
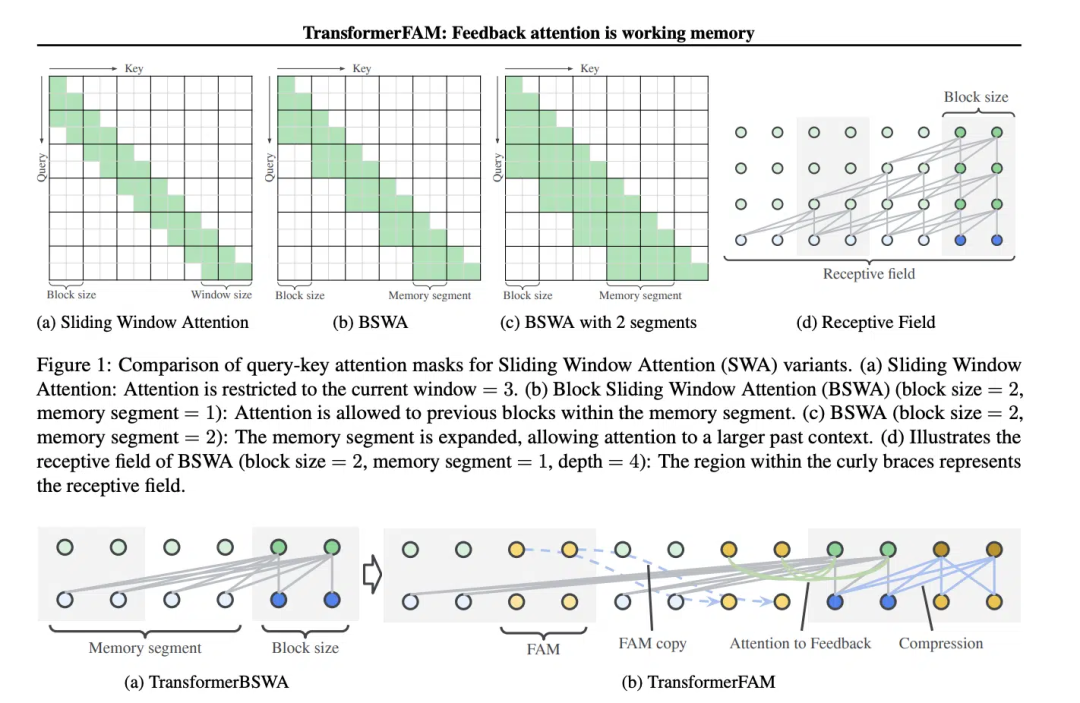
滑动窗口注意力(Sliding Window Attention),它是一种改进的注意力机制,用于处理长序列数据。它受到了计算机科学中滑动窗口技术(sliding window technique)的启发。在处理自然语言处理(NLP)任务时,SWA允许模型在每个时间步骤上只关注输入序列的一个固定大小的窗口,而不是整个序列。因此,SWA的优点在于它可以显著减少计算量。
 图片
图片
但是SWA有局限性,因为它的注意力范围受限于窗口大小,这导致模型无法考虑到窗口之外的重要信息。
TransformerFAM通过添加反馈激活,将上下文表示重新输入到滑动窗口注意力的每个区块中,从而实现了集成注意力、区块级更新、信息压缩和全局上下文存储。
在TransformerFAM中,改进通过反馈循环实现。具体来说,模型在处理当前序列块时,不仅关注当前窗口内的元素,还会将之前处理过的上下文信息(即之前的“反馈激活”)作为额外的输入重新引入到注意力机制中。这样,即使模型的注意力窗口在序列上滑动,它也能够保持对之前信息的记忆和理解。
于是,经过这番改进,TransformerFAM就给了LLMs能够处理无限长度序列的潜力!
2. With a large model of working memory, continue to move towards AGI
TransformerFAM has shown positive prospects in research, which will undoubtedly improve AI's ability to understand and generate long text tasks Performance, such as processing document summarization, story generation, Q&A, etc.
 Picture
Picture
At the same time, whether it is an intelligent assistant or an emotional companion, an AI with unlimited memory sounds more attractive.
Interestingly, the design of TransformerFAM is inspired by the memory mechanism in biology, which coincides with the natural intelligence simulation pursued by AGI. This paper is an attempt to integrate a concept from neuroscience—attention-based working memory—into the field of deep learning.
TransformerFAM introduces working memory into large models through feedback loops, allowing the model to not only remember short-term information, but also maintain the memory of key information in long-term sequences.
Through bold imagination, researchers build hypothetical bridges between the real world and abstract concepts. As innovative achievements like TransformerFAM continue to emerge, technological bottlenecks will be broken through again and again, and a more intelligent and interconnected future is slowly unfolding towards us.
To learn more about AIGC, please visit:
51CTO AI.x Community
https://www.51cto.com/aigc/
以上是谷歌出手整頓大模型「健忘症」!回饋注意力機制幫你「更新」上下文,大模型無限記憶力時代將至的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 加密數字資產交易APP推薦top10(2025全球排名)
Mar 18, 2025 pm 12:15 PM
加密數字資產交易APP推薦top10(2025全球排名)
Mar 18, 2025 pm 12:15 PM
本文推荐十大值得关注的加密货币交易平台,涵盖币安(Binance)、OKX、Gate.io、BitFlyer、KuCoin、Bybit、Coinbase Pro、Kraken、BYDFi和XBIT去中心化交易所。这些平台在交易币种数量、交易类型、安全性、合规性、特色功能等方面各有千秋,例如币安以其全球最大的交易量和丰富的功能著称,而BitFlyer则凭借其日本金融厅牌照和高安全性吸引亚洲用户。选择合适的平台需要根据自身交易经验、风险承受能力和投资偏好进行综合考量。 希望本文能帮助您找到最适合自
 歐易okex賬號怎麼註冊、使用、註銷教程
Mar 31, 2025 pm 04:21 PM
歐易okex賬號怎麼註冊、使用、註銷教程
Mar 31, 2025 pm 04:21 PM
本文詳細介紹了歐易OKEx賬號的註冊、使用和註銷流程。註冊需下載APP,輸入手機號或郵箱註冊,完成實名認證。使用方面涵蓋登錄、充值提現、交易以及安全設置等操作步驟。而註銷賬號則需要聯繫歐易OKEx客服,提供必要信息並等待處理,最終獲得賬號註銷確認。 通過本文,用戶可以輕鬆掌握歐易OKEx賬號的完整生命週期管理,安全便捷地進行數字資產交易。
 binance怎麼註冊詳細教程(2025新手指南)
Mar 18, 2025 pm 01:57 PM
binance怎麼註冊詳細教程(2025新手指南)
Mar 18, 2025 pm 01:57 PM
本文提供Binance幣安註冊及安全設置的完整指南,涵蓋註冊前的準備工作(包括設備、郵箱、手機號及身份證明文件準備),詳細介紹了官網及APP兩種註冊方式,以及不同級別的身份驗證(KYC)流程。此外,文章還重點講解瞭如何設置資金密碼、開啟雙重驗證(2FA,包括谷歌身份驗證器和短信驗證)以及設置防釣魚碼等關鍵安全步驟,幫助用戶安全便捷地註冊和使用Binance幣安平台進行加密貨幣交易。 請務必在交易前了解相關法律法規及市場風險,謹慎投資。
 如何優化jieba分詞以改善景區評論的關鍵詞提取效果?
Apr 01, 2025 pm 06:24 PM
如何優化jieba分詞以改善景區評論的關鍵詞提取效果?
Apr 01, 2025 pm 06:24 PM
如何優化jieba分詞以改善景區評論的關鍵詞提取?在使用jieba分詞處理景區評論數據時,如果發現分詞結果不理�...
 gate.io手機app使用教程
Mar 26, 2025 pm 05:15 PM
gate.io手機app使用教程
Mar 26, 2025 pm 05:15 PM
gate.io手機app使用教程:1、安卓用戶,訪問 Gate.io 官方網站,下載安卓安裝包,您可能需要在手機設置中允許安裝來自未知來源的應用;2、ios用戶,在 App Store 中搜索 "Gate.io" 下載。
 虛擬幣最老的幣排行榜最新更新
Apr 22, 2025 am 07:18 AM
虛擬幣最老的幣排行榜最新更新
Apr 22, 2025 am 07:18 AM
虛擬貨幣“最老”排行榜如下:1. 比特幣(BTC),發行於2009年1月3日,是首個去中心化數字貨幣。 2. 萊特幣(LTC),發行於2011年10月7日,被稱為“比特幣的輕量版”。 3. 瑞波幣(XRP),發行於2011年,專為跨境支付設計。 4. 狗狗幣(DOGE),發行於2013年12月6日,基於萊特幣代碼的“迷因幣”。 5. 以太坊(ETH),發行於2015年7月30日,首個支持智能合約的平台。 6. 泰達幣(USDT),發行於2014年,是首個與美元1:1錨定的穩定幣。 7. 艾達幣(ADA),發
 okex交易平台官網登錄入口
Mar 18, 2025 pm 12:42 PM
okex交易平台官網登錄入口
Mar 18, 2025 pm 12:42 PM
本文詳細介紹了歐易OKEx網頁版登錄的完整步驟,包括準備工作(確保網絡連接穩定及瀏覽器更新)、訪問官網(注意網址準確性,避免釣魚網站)、找到登錄入口(點擊官網首頁右上角的“登錄”按鈕)、輸入登錄信息(郵箱/手機號及密碼,支持驗證碼登錄)、完成安全驗證(滑動驗證、谷歌驗證或短信驗證)等五個步驟,最終成功登錄後即可進行數字資產交易等操作。 安全便捷的登錄流程,保障用戶資產安全。
 虛擬幣購買app安全靠譜的top10推薦
Mar 18, 2025 pm 12:12 PM
虛擬幣購買app安全靠譜的top10推薦
Mar 18, 2025 pm 12:12 PM
2025年全球虛擬幣交易平台Top 10推薦,助您玩轉數字貨幣市場!本文將為您深度解析幣安(Binance)、OKX、Gate.io、BitFlyer、KuCoin、Bybit、Coinbase Pro、Kraken、BYDFi和XBIT去中心化交易所等十家頂級平台的核心優勢和特色功能。無論是追求高流動性、豐富的交易類型,還是注重安全合規、創新功能,都能在此找到適合您的平台。 我們將從交易品種、安全性、特色功能等方面進行全面對比,助您選擇最合適的虛擬貨幣交易平台,把握2025年數字貨幣投資機遇
