

nuScenes最新SOTA | SparseAD:稀疏查詢協助高效端對端自動駕駛!

寫在前面&出發點
端到端的範式使用統一的框架在自動駕駛系統中實現多任務。儘管這種範式具有簡單性和清晰性,但端到端的自動駕駛方法在子任務上的表現仍然遠遠落後於單任務方法。同時,先前端到端方法中廣泛使用的密集鳥瞰圖(BEV)特徵使得擴展到更多模態或任務變得困難。這裡提出了一種稀疏查找為中心的端到端自動駕駛範式(SparseAD),其中稀疏查找完全代表整個駕駛場景,包括空間、時間和任務,無需任何密集的BEV表示。具體來說,設計了一個統一的稀疏架構,用於包括檢測、追蹤和線上地圖繪製在內的任務感知。此外,重新審視了運動預測和規劃,同時設計了一個更合理的運動規劃框架。在具有挑戰性的nuScenes資料集上,SparseAD在端到端方法中實現了最先進的全任務效能,並減少了端對端範式與單一任務方法之間的效能差距。
領域背景
自動駕駛系統需要在複雜的駕駛場景中做出正確的決策,以確保駕駛的安全性和舒適性。通常,自動駕駛系統整合了多個任務,如偵測、追蹤、線上地圖、運動預測和規劃。如圖1a所示,傳統的模組化範式將複雜的系統拆分為多個單獨的任務,每個任務都獨立優化。在這種範式中,獨立的單任務模組之間需要手動進行後處理,這使得整個流程變得更繁瑣。另一方面,由於堆疊任務之間的場景資訊損失壓縮,整個系統的誤差會累積,這可能導致潛在的安全問題。
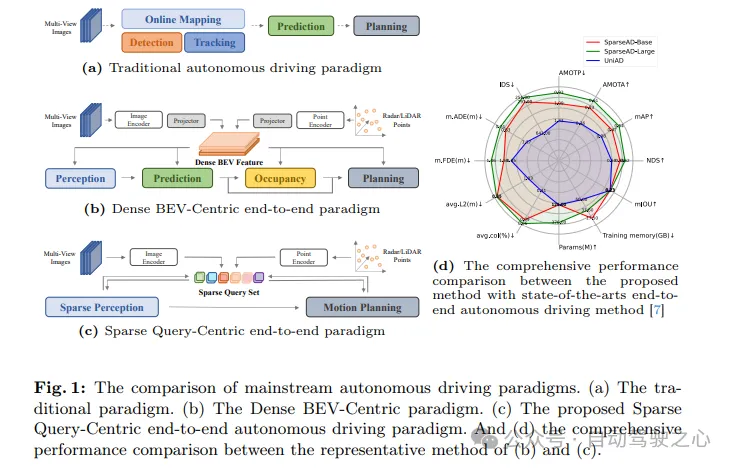
關於上述問題,端對端自動駕駛系統以原始感知器資料作為輸入,並以更簡潔的方式傳回規劃結果。早期的工作提出跳過中間任務,直接從原始感知器資料預測規劃結果。儘管這種方法更為直接,但在模型最佳化、可解釋性和規劃性能方面並不令人滿意。另一種具有更好可解釋性的多面範式是將自動駕駛的多個部分整合到一個模組化的端到端模型中,其中引入了多維度的監督,以提高對複雜駕駛場景的理解能力,並帶來多工的能力。
根據圖1b所示,在大多數先進的模組化端到端方法中,整個驅動場景透過密集集合的鳥瞰圖(BEV)特徵進行表徵,這些特徵包括多感測器和時間信息,並作為全端驅動任務(包括感知、預測和規劃)的輸入。儘管密集集合的BEV特徵在跨空間和時間的多模態和多任務中實現了關鍵作用,將先前使用BEV表示的端到端方法總結為Dense BEV-Centric範式。儘管這些方法具有簡潔性和可解釋性,但它們在自動駕駛的每個子任務上的表現仍然遠遠落後於相應的單任務方法。此外,在Dense BEV-Centric範式下,長期時間融合和多模態融合主要是透過多個BEV特徵圖來實現,這導致了計算成本、記憶體佔用顯著增加,給實際部署帶來了更大的負擔。
這裡提出了一種新穎的稀疏查找為中心的端對端自動駕駛範式(SparseAD)。在這個範式中,整個駕駛場景中的空間和時間元素均由稀疏查找表表示,摒棄了傳統的密集集合鳥瞰圖(BEV)特徵,如圖1c所示。這種稀疏表示使得端到端模型能夠更有效率地利用更長的歷史信息,並擴展到更多模式和任務,同時顯著降低了計算成本和記憶體佔用。
重新設計了模組化端到端架構,並將其簡化為一個由稀疏感知和運動規劃器組成的簡潔結構。在稀疏感知模組中,利用通用的時間解碼器[將包括檢測、追蹤和線上地圖繪製在內的感知任務統一起來。在這個過程中,多感測器特徵和歷史記錄被視為tokens,而物件查詢和地圖查詢則分別代表驅駛場景中的障礙物和道路元素。在運動規劃器中,以稀疏感知查詢作為環境表示,同時對車輛和周圍代理進行多模態運動預測,以獲取自車的多種初始規劃方案。隨後,充分考慮多維度駕駛約束,產生最終的規劃結果。
主要貢獻:
- 提出了一种新颖的以稀疏查询为中心的端到端自动驾驶范式(SparseAD),该范式摒弃了传统的密集鸟瞰图(BEV)表示方法,因此具有巨大的潜力,能够高效地扩展到更多模态和任务。
- 将模块化的端到端架构简化为稀疏感知和运动规划两部分。在稀疏感知部分,以完全稀疏的方式统一了检测、跟踪和在线地图绘制等感知任务;而在运动规划部分,则在更合理的框架下进行了运动预测和规划。
- 在具有挑战性的nuScenes数据集上,SparseAD在端到端方法中取得了最先进的性能,并显著缩小了端到端范式与单任务方法之间的性能差距。这充分证明了所提出的稀疏端到端范式具有巨大的潜力。SparseAD不仅提高了自动驾驶系统的性能和效率,还为未来的研究和应用提供了新的方向和可能性。
SparseAD网络结构
根据图1c所示,在提出的以稀疏查询为中心的范式中,不同的稀疏查询完全代表了整个驾驶场景,不仅负责模块之间的信息传递和交互,还以端到端的方式在多任务中传播反向梯度以进行优化。与以往以密集集鸟瞰图(BEV)为中心的方法不同,SparseAD中没有使用任何视图投影和密集BEV特征,从而避免了沉重的计算和内存负担,SparseAD的详细架构如图2所示。
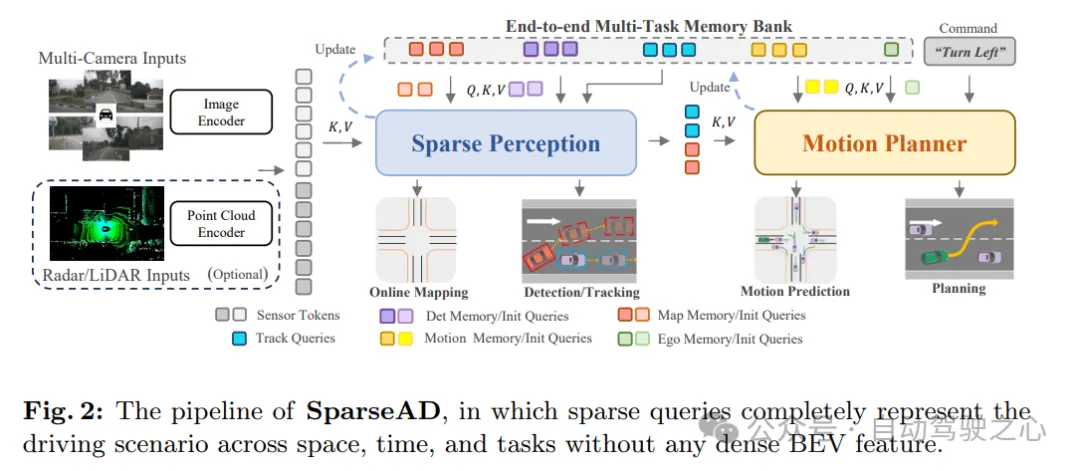
从架构示意图上看,SparseAD主要由三部分组成,包括传感器编码器、稀疏感知和运动规划器。具体来说,传感器编码器将多视图相机图像、雷达或激光雷达点作为输入,并将其编码成高维特征。这些特征随后与位置嵌入(PE)一起作为传感器tokens输入到稀疏感知模块中。在稀疏感知模块中,来自传感器的原始数据将被聚合成多种稀疏感知查询,如检测查询、跟踪查询和地图查询,它们分别代表驾驶场景中的不同元素,并将进一步传播到下游任务中。在运动规划器中,感知查询被视为驾驶场景的稀疏表示,并被充分利用于所有周围agent和自车。同时,考虑了多方面的驾驶约束以生成既安全又符合动力学要求的最终规划。
此外,架构中引入了端到端多任务记忆库,用于统一存储整个驾驶场景的时序信息,这使得系统能够受益于长时间历史信息的聚合,从而完成全栈驾驶任务。
如图3所示,SparseAD的稀疏感知模块以稀疏的方式统一了多个感知任务,包括检测、跟踪和在线地图绘制。具体来说,这里有两个结构完全相同的时序解码器,它们利用来自记忆库的长期历史信息。其中一个解码器用于障碍物感知,另一个用于在线地图绘制。
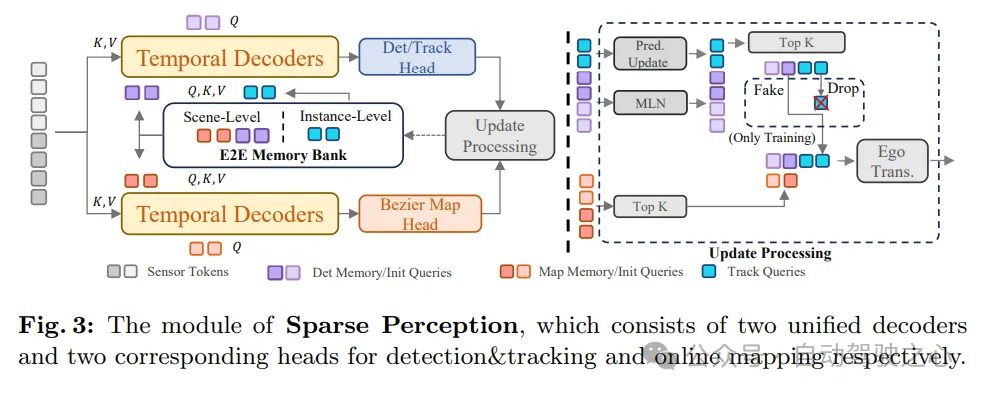
通过不同任务对应的感知查询进行信息聚合后,检测和跟踪头以及地图部分别被用于解码和输出障碍物和地图元素。之后,进行更新过程,该过程会过滤并保存当前帧的高置信度感知查询,并相应地更新记忆库,这将有利于下一帧的感知过程。
通过这种方式,SparseAD的稀疏感知模块实现了对驾驶场景的高效、准确的感知,为后续的运动规划提供了重要的信息基础。同时,通过利用记忆库中的历史信息,模块能够进一步提高感知的准确性和稳定性,确保自动驾驶系统的可靠运行。
稀疏感知
在障碍物感知方面,在统一的解码器内采用联合检测和跟踪的方式,无需任何额外的手工后处理。检测和跟踪查询之间存在明显的不平衡,这可能导致检测性能的显著下降。为了缓解上述问题,从多个角度改进了障碍物感知的性能。首先,引入了两级记忆机制来跨帧传播时序信息。其中,场景级记忆维持没有跨帧关联的查询信息,而实例级记忆则保持跟踪障碍物相邻帧之间的对应关系。其次,考虑到两者起源和任务的不同,对场景级和实例级记忆采用了不同的更新策略。具体来说,通过MLN来更新场景级记忆,而实例级记忆则通过每个障碍物的未来预测进行更新。此外,在训练过程中,还对跟踪查询采用了增强策略,以平衡两级记忆之间的监督,从而增强检测和跟踪性能。之后,通过检测和跟踪头部,可以从检测或跟踪查询中解码出具有属性和唯一ID的3D边界框,然后进一步用于下游任务。
線上地圖建構是一個複雜而重要的任務。根據目前所了解的知識,現有的線上地圖建立方法大多依賴密集的鳥瞰視圖(BEV)特徵來表示駕駛環境。這種方法在擴展感知範圍或利用歷史資訊方面存在困難,因為需要大量的記憶體和計算資源。我們堅信所有的地圖元素都可以以稀疏的方式表示,因此,嘗試在稀疏範式下完成線上地圖建構。具體來說,採用了與障礙物感知任務中相同的時序解碼器結構。最初,帶有先驗類別的地圖查詢被初始化為在駕駛平面上均勻分佈。在時序解碼器中,地圖查詢與感測器標記和歷史記憶標記互動。這些歷史記憶標記實際上是由先前幀中高度可信的地圖查詢組成的。然後,更新後的地圖查詢攜帶了當前幀地圖元素的有效訊息,可以被推送到記憶庫中,以便在未來的幀或下游任務中使用。
顯然,線上地圖建構的流程與障礙物感知大致相同。也就是說,統一了包括檢測、追蹤和線上地圖建構在內的感知任務,採用了一種通用的稀疏方式,這種方式在擴展到更大範圍(例如100m × 100m)或長期融合時更加高效,而且不需要任何複雜的操作(如可變形注意力或多點注意力)。據我們所知,這是第一個在稀疏方式下在統一感知架構中實現線上地圖建構的。隨後,利用分段貝塞爾地圖Head來回歸每個稀疏地圖元素的分段貝塞爾控制點,這些控制點可以方便地轉換以滿足下游任務的要求。
Motion Planner
我們重新審視了自動駕駛系統中的運動預測與規劃問題,並發現許多先前的方法在預測周圍車輛運動時忽略了本車(ego-vehicle)的動態。雖然這在大多數情況下可能不會顯現出來,但在諸如交叉口等場景中,當近處車輛與本車之間交互緊密時,這可能會帶來潛在風險。受此啟發,設計了一個更合理的運動規劃架構。在這個框架中,運動預測器同時預測周圍車輛和本車的移動。隨後,本車的預測結果作為運動先驗被用於後續的規劃優化器。在規劃過程中,我們考慮了不同方面的約束,以產生既滿足安全性又符合動力學要求的最終規劃結果。
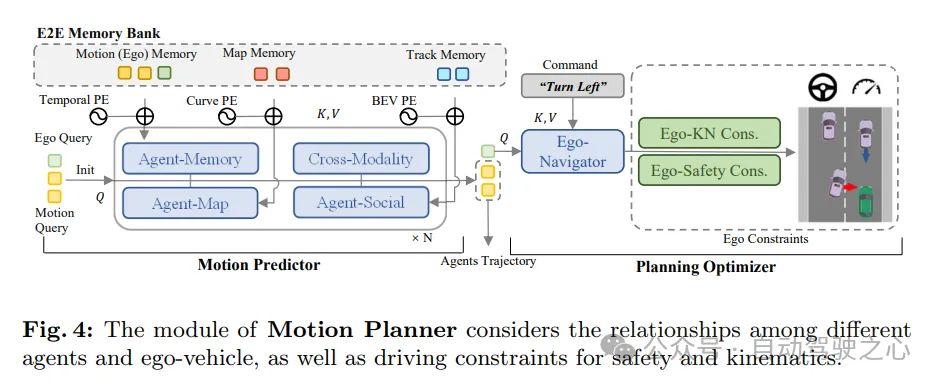
如圖4所示,SparseAD中的運動規劃器將感知查詢(包括軌跡查詢和地圖查詢)作為目前駕駛場景的稀疏表示。多模態運動查詢被用作媒介,以實現對駕駛場景的理解、對所有車輛(包括本車)之間交互的感知,以及對不同未來可能性的博弈。隨後,本車的多模態運動查詢被送入規劃優化器,其中充分考慮了包括高級指令、安全性和動力學在內的多個方面的駕駛約束。
運動預測器。遵循先前的方法,透過標準的transformer層實現了運動查詢與當前駕駛場景表示(包括軌跡查詢和地圖查詢)之間的感知和整合。此外,應用自車agent和跨模態互動來共同建模未來時空場景中周圍agent和本車之間的交互作用。透過多層堆疊結構內部和之間的模組協同作用,運動查詢能夠聚合來自靜態和動態環境的豐富語義資訊。
除了上述內容外,還引入了兩種策略來進一步提高運動預測器的性能。首先,利用軌跡查詢的實例層級時間記憶進行簡單直接的預測,並將其作為周圍agent運動查詢初始化的一部分。透過這種方式,運動預測器能夠從上游任務中獲得的先驗知識中受益。其次,由於端到端記憶庫,能夠以幾乎可忽略的成本、以流式方式透過代理記憶聚合器從保存的歷史運動查詢中同化有用資訊。
要注意的是,本車的多模態運動查詢是同時更新的。透過這種方式,可以獲得本車的運動先驗,這可以進一步促進規劃的學習過程。
規劃最佳化器。借助運動預測器提供的運動先驗,獲得了更好的初始化,從而在訓練過程中減少了繞行。作為運動規劃器的關鍵組成部分,成本函數的設計至關重要,因為它將極大地影響甚至決定最終性能的品質。在所提出的SparseAD運動規劃器中,主要考慮安全和動力學兩大方面的約束,旨在產生令人滿意的規劃結果。具體來說,除了VAD中確定的約束外,還重點關注本車與附近agent之間的動態安全關係,並考慮它們在未來時刻的相對位置。例如,如果agent i相對於本車持續保持在前方左側區域,從而阻止本車向左變換車道,那麼agent i將獲得一個左標籤,表示agent i對本車施加了向左的約束。因此,約束在縱向方向上分為前、後或無,在橫向方向上分為左、右或無。在規劃器中,我們從對應的查詢中解碼其他agent與本車在橫向和縱向方向上的關係。這個過程涉及確定這些方向上其他代理與本車之間所有約束關係的機率。然後,我們利用focal loss作為Ego-Agent關係(EAR)的成本函數,有效地捕捉附近agent帶來的潛在風險:
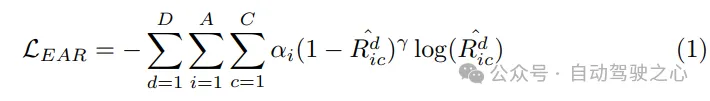
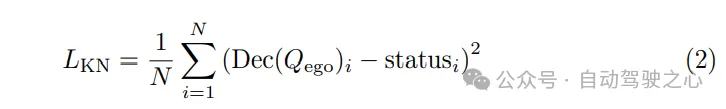
在nuScenes資料集上進行了大量實驗,以證明方法的有效性和優越性。公正地說,將對每個完整任務的表現進行評估,並與先前的方法進行比較。本節實驗使用了SparseAD的三種不同配置,分別是僅使用影像輸入的SparseAD-B和SparseAD-L,以及使用雷達點雲和影像多模態輸入的SparseAD-BR。 SparseAD-B和SparseAD-BR都使用V2-99作為影像骨幹網絡,輸入影像解析度為1600 × 640。 SparseAD-L則進一步利用ViTLarge作為影像骨幹網絡,輸入影像解析度為1600×800。
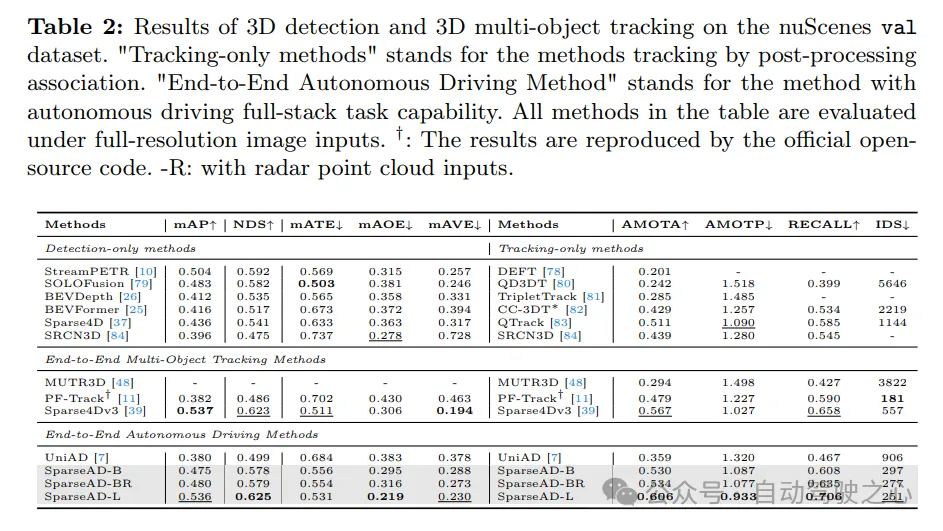
在nuScenes驗證資料集上的3D偵測和3D多目標追蹤結果如下。 「僅追蹤方法」指的是透過後製關聯進行追蹤的方法。 「端到端自動駕駛方法」指的是具備自動駕駛全端任務能力的方法。表中的所有方法都是在全解析度影像輸入下進行評估的。 †:結果是透過官方開源程式碼復現的。 -R:表示使用了雷達點雲輸入。
 與線上建圖方法的效能比較如下,結果是在[1.0m, 1.5m, 2.0m]的閾值下進行評估的。 ‡:透過官方開源程式碼復現的結果。 †:根據SparseAD中規劃模組的需求,我們進一步將邊界細分為路段和車道,並分別進行評估。 ∗:骨幹網路和稀疏感知模組的成本。 -R:表示使用了雷達點雲輸入。
與線上建圖方法的效能比較如下,結果是在[1.0m, 1.5m, 2.0m]的閾值下進行評估的。 ‡:透過官方開源程式碼復現的結果。 †:根據SparseAD中規劃模組的需求,我們進一步將邊界細分為路段和車道,並分別進行評估。 ∗:骨幹網路和稀疏感知模組的成本。 -R:表示使用了雷達點雲輸入。

障礙感知
。在Tab. 2中將SparseAD的檢測和追蹤性能與nuScenes驗證集上的其他方法進行了比較。顯然,SparseAD-B在大多數流行的僅檢測、僅追蹤和端到端多目標追蹤方法中表現出色,同時與SOTA方法如StreamPETR、QTrack在相應任務上的表現相當。透過採用更先進的骨幹網路進行擴展,SparseAD-Large實現了整體更好的性能,其mAP為53.6%,NDS為62.5%,AMOTA為60.6%,整體上優於之前的最佳方法Sparse4Dv3。 在线建图。在Tab. 3中展示了SparseAD与其他先前方法在nuScenes验证集上的在线建图性能比较结果。需要指出的是,根据规划的需求,我们将边界细分为路段和车道,并分别进行评估,同时将范围从通常的60m × 30m扩展到102.4m × 102.4m,以与障碍感知保持一致。在不失公平性的前提下,SparseAD以稀疏的端到端方式实现了34.2%的mAP,无需任何密集的BEV表示,这优于大多数之前流行的方法,如HDMapNet、VectorMapNet和MapTR,在性能和训练成本方面都具有明显优势。尽管性能略逊于StreamMapNet,但我们的方法证明了在线建图可以在统一的稀疏方式下完成,无需任何密集的BEV表示,这对于以显著较低成本实现端到端自动驾驶的实际部署具有重要意义。诚然,如何有效利用其他模态(如雷达)的有用信息仍是一个值得进一步探索的任务。我们相信在稀疏方式下仍有很大的探索空间。 运动预测。在Tab. 4a中展示了运动预测的比较结果,其中指标与VIP3D保持一致。SparseAD在所有端到端方法中实现了最佳性能,具有最低的0.83m minADE、1.58m minFDE、18.7%的遗漏率以及最高的0.308 EPA,优势巨大。此外,得益于稀疏查询中心范式的效率和可扩展性,SparseAD可以有效地扩展到更多模态,并从先进的骨干网络中受益,从而进一步显著提高预测性能。 规划。规划的结果呈现在Tab. 4b中。得益于上游感知模块和运动规划器的卓越设计,SparseAD的所有版本在nuScenes验证数据集上都达到了最先进水平。具体来说,与包括UniAD和VAD在内的所有其他方法相比,SparseAD-B实现了最低的平均L2误差和碰撞率,这证明了我们的方法和架构的优越性。与上游任务(包括障碍感知和运动预测)类似,SparseAD通过雷达或更强大的骨干网络进一步提升了性能。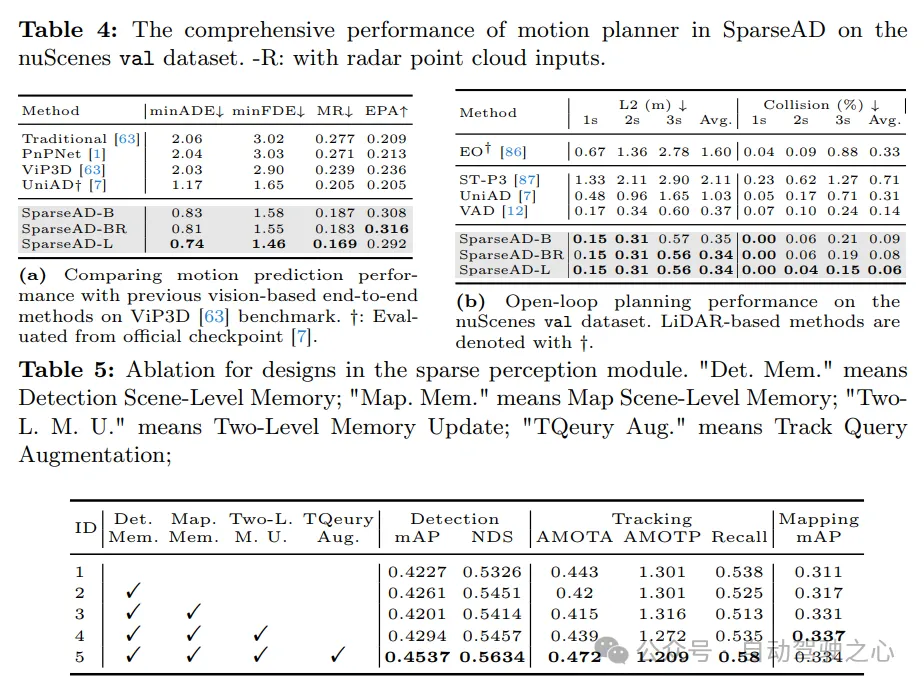

以上是nuScenes最新SOTA | SparseAD:稀疏查詢協助高效端對端自動駕駛!的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 自動駕駛場景中的長尾問題怎麼解決?
Jun 02, 2024 pm 02:44 PM
自動駕駛場景中的長尾問題怎麼解決?
Jun 02, 2024 pm 02:44 PM
昨天面試被問到了是否做過長尾相關的問題,所以就想著簡單總結一下。自動駕駛長尾問題是指自動駕駛汽車中的邊緣情況,即發生機率較低的可能場景。感知的長尾問題是目前限制單車智慧自動駕駛車輛運行設計域的主要原因之一。自動駕駛的底層架構和大部分技術問題已經解決,剩下的5%的長尾問題,逐漸成了限制自動駕駛發展的關鍵。這些問題包括各種零碎的場景、極端的情況和無法預測的人類行為。自動駕駛中的邊緣場景"長尾"是指自動駕駛汽車(AV)中的邊緣情況,邊緣情況是發生機率較低的可能場景。這些罕見的事件

 華為手機記憶體不足怎麼辦(解決記憶體不足問題的實用方法)
Apr 29, 2024 pm 06:34 PM
華為手機記憶體不足怎麼辦(解決記憶體不足問題的實用方法)
Apr 29, 2024 pm 06:34 PM
華為手機內存不足已經成為許多用戶面臨的常見問題、隨著行動應用程式和媒體檔案的增加。幫助用戶充分利用手機的儲存空間、本文將介紹一些實用方法來解決華為手機記憶體不足的問題。 1.清理快取:歷史記錄以及無效數據,以釋放記憶體空間,清除應用程式產生的臨時檔案。在華為手機設定中找到「儲存」點擊,選項「清除快取」按鈕即可刪除應用程式的快取檔案。 2.卸載不常用的應用程式:以釋放記憶體空間,刪除一些不常用的應用程式。拖曳到手機螢幕上方的、長按要刪除的應用程式圖示「卸載」然後點擊確認按鈕即可完成卸載,標誌處。 3.移動應用到
 deepseek怎麼本地微調
Feb 19, 2025 pm 05:21 PM
deepseek怎麼本地微調
Feb 19, 2025 pm 05:21 PM
本地微調 DeepSeek 類模型面臨著計算資源和專業知識不足的挑戰。為了應對這些挑戰,可以採用以下策略:模型量化:將模型參數轉換為低精度整數,減少內存佔用。使用更小的模型:選擇參數量較小的預訓練模型,便於本地微調。數據選擇和預處理:選擇高質量的數據並進行適當的預處理,避免數據質量不佳影響模型效果。分批訓練:對於大數據集,分批加載數據進行訓練,避免內存溢出。利用 GPU 加速:利用獨立顯卡加速訓練過程,縮短訓練時間。
 FisheyeDetNet:首個以魚眼相機為基礎的目標偵測演算法
Apr 26, 2024 am 11:37 AM
FisheyeDetNet:首個以魚眼相機為基礎的目標偵測演算法
Apr 26, 2024 am 11:37 AM
目標偵測在自動駕駛系統當中是一個比較成熟的問題,其中行人偵測是最早得以部署演算法之一。在多數論文當中已經進行了非常全面的研究。然而,利用魚眼相機進行環視的距離感知相對來說研究較少。由於徑向畸變大,標準的邊界框表示在魚眼相機當中很難實施。為了緩解上述描述,我們探索了擴展邊界框、橢圓、通用多邊形設計為極座標/角度表示,並定義一個實例分割mIOU度量來分析這些表示。所提出的具有多邊形形狀的模型fisheyeDetNet優於其他模型,並同時在用於自動駕駛的Valeo魚眼相機資料集上實現了49.5%的mAP
 Edge瀏覽器記憶體佔用太多怎麼辦 記憶體佔用太多的解決方法
May 09, 2024 am 11:10 AM
Edge瀏覽器記憶體佔用太多怎麼辦 記憶體佔用太多的解決方法
May 09, 2024 am 11:10 AM
1.首先,進入Edge瀏覽器點選右上角三個點。 2、然後,在工作列中選擇【擴充】。 3、接著,將不需要使用的插件關閉或卸載即可。
 只要250美元,Hugging Face技術主管手把手教你微調Llama 3
May 06, 2024 pm 03:52 PM
只要250美元,Hugging Face技術主管手把手教你微調Llama 3
May 06, 2024 pm 03:52 PM
我們熟悉的Meta推出的Llama3、MistralAI推出的Mistral和Mixtral模型以及AI21實驗室推出的Jamba等開源大語言模型已經成為OpenAI的競爭對手。在大多數情況下,使用者需要根據自己的資料對這些開源模型進行微調,才能充分釋放模型的潛力。在單一GPU上使用Q-Learning對比小的大語言模型(如Mistral)進行微調不是難事,但對像Llama370b或Mixtral這樣的大模型的高效微調直到現在仍然是一個挑戰。因此,HuggingFace技術主管PhilippSch
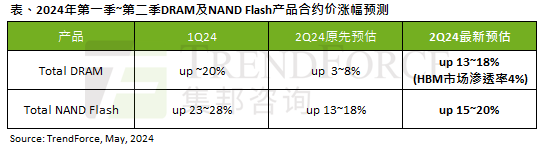 AI 潮影響明顯,TrendForce 上修本季 DRAM 記憶體、NAND 快閃記憶體合約價漲幅預測
May 07, 2024 pm 09:58 PM
AI 潮影響明顯,TrendForce 上修本季 DRAM 記憶體、NAND 快閃記憶體合約價漲幅預測
May 07, 2024 pm 09:58 PM
根據TrendForce的調查報告顯示,AI浪潮對DRAM記憶體和NAND快閃記憶體市場帶來明顯影響。在本站5月7日消息中,TrendForce集邦諮詢在今日的最新研報中稱該機構調升本季兩類儲存產品的合約價格漲幅。具體而言,TrendForce原先預估2024年第二季DRAM記憶體合約上漲3~8%,現估計為13~18%;而在NAND快閃記憶體方面,原預估上漲13~18%,新預估為15 ~20%,僅eMMC/UFS漲幅較低,為10%。 ▲圖源TrendForce集邦諮詢TrendForce表示,該機構原預計在連續
