

Transformer本來可以深謀遠慮,但就是不做

語言模型是否會規劃未來 token?這篇論文給你答案。
「別讓 Yann LeCun 看見了。」
Yann LeCun 表示太遲了,他已經看到了。今天要介紹的這篇 「LeCun 非要看」的論文探討的問題是:Transformer 是深謀遠慮的語言模型嗎?當它在某個位置執行推理時,它會預先考慮後面的位置嗎?
這項研究得出的結論是:Transformer 有能力這樣做,但在實踐中不會這樣做。
我們都知道,人類會思考而後言。十年的語言學研究顯示:人類在使用語言時,內心會預測即將出現的語言輸入、單字或句子。
不同於人類,現在的語言模型在「說話」時會為每個 token 分配固定的計算量。那麼我們不禁要問:語言模型會和人類一樣預先性地思考嗎?
根據最近的一些研究已經顯示:可以透過探查語言模型的隱藏狀態來預測下一 token。有趣的是,透過在模型隱藏狀態上使用線性探針,可以在一定程度上預測模型在未來 token 上的輸出,並且可以對未來輸出進行可預測的修改。 近期的一些研究已經表明,可以透過探查語言模型的隱藏狀態來預測下一 token。有趣的是,透過在模型隱藏狀態上使用線性探針,可以在一定程度上預測模型在未來 token 上的輸出,並且可以對未來輸出進行可預測的修改。
這些發現表明在給定時間步驟的模型活化至少在一定程度上可以預測未來輸出。
但是,我們還不清楚原因:這只是資料的偶然屬性,還是因為模型會刻意為未來時間步驟準備資訊(但這會影響模型在目前位置的表現)?
為了解答這個問題,近日科羅拉多大學博爾德分校和康乃爾大學的三位研究者發布了一篇題為《語言模型是否會規劃未來 token? 》的論文。

論文標題:Do Language Models Plan for Future Tokens?
論文地址:https://arxiv.org/pdf/2404.00859.pdf
研究概覽
他們觀察到,在訓練期間的梯度既會為當前token 位置的損失優化權重,也會為該序列後面的token 進行優化。他們又進一步問:目前的 transformer 權重會以怎樣的比例為目前 token 和未來 token 分配資源?
他們考慮了兩種可能性:預先快取假設(pre-caching hypothesis)和麵包屑假設(breadcrumbs hypothesis)。

預先快取假設是指transformer 會在時間步驟t 計算與當前時間步驟的推理任務無關但可能對未來時間步驟t τ 有用的特徵,而麵包屑假設是指與時間步驟t 最相關的特徵已經等同於將在時間步驟t τ 最有用的特徵。
為了評估哪個假設是正確的,團隊提出了一種短視型訓練方案(myopic training scheme),該方案不會將當前位置的損失的梯度傳播給先前位置的隱藏狀態。
上述假設和方案的數學定義和理論描述請參考原文。
實驗結果
為了了解語言模型是否可能直接實現預先緩存,他們設計了一種合成場景,其中只能透過明確的預先緩存完成任務。他們配置了一個任務,其中模型必須為下一 token 預先計算訊息,否則就無法在一次單向通過中準確計算出正確答案。

時定義中所建立的合成資料集定義。
在這個合成場景中,團隊發現了明顯的證據可以說明 transformer 可以學習預先快取。當基於 transformer 的序列模型必須預先計算資訊來最小化損失時,它們就會這樣做。
之後,他們又探究了自然語言模型(預先訓練的 GPT-2 變體)是會展現出麵包屑假設還是會展現出預先緩存假設。他們的短視型訓練方案實驗顯示在這種設定中,預先緩存出現的情況少得多,因此結果更偏向於麵包屑假設。
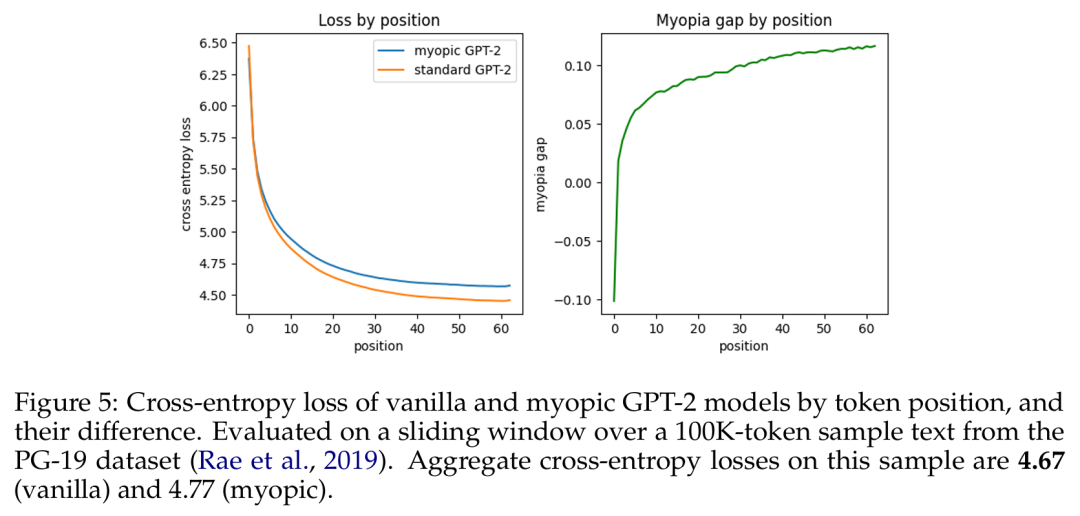
基于 token 位置的原始 GPT-2 模型与短视型 GPT-2 模型的交叉熵损失及其差异。
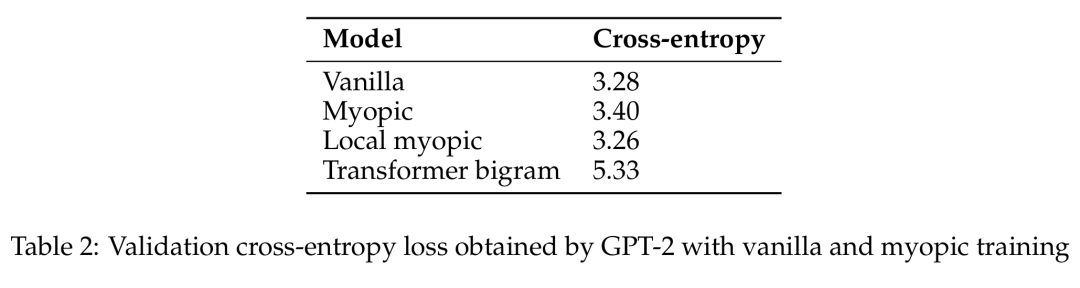
GPT-2 通过原始和短视型训练获得的验证交叉熵损失。
于是该团队声称:在真实语言数据上,语言模型并不会在显著程度上准备用于未来的信息。相反,它们是计算对预测下一个 token 有用的特征 —— 事实证明这对未来的步骤也很有用。
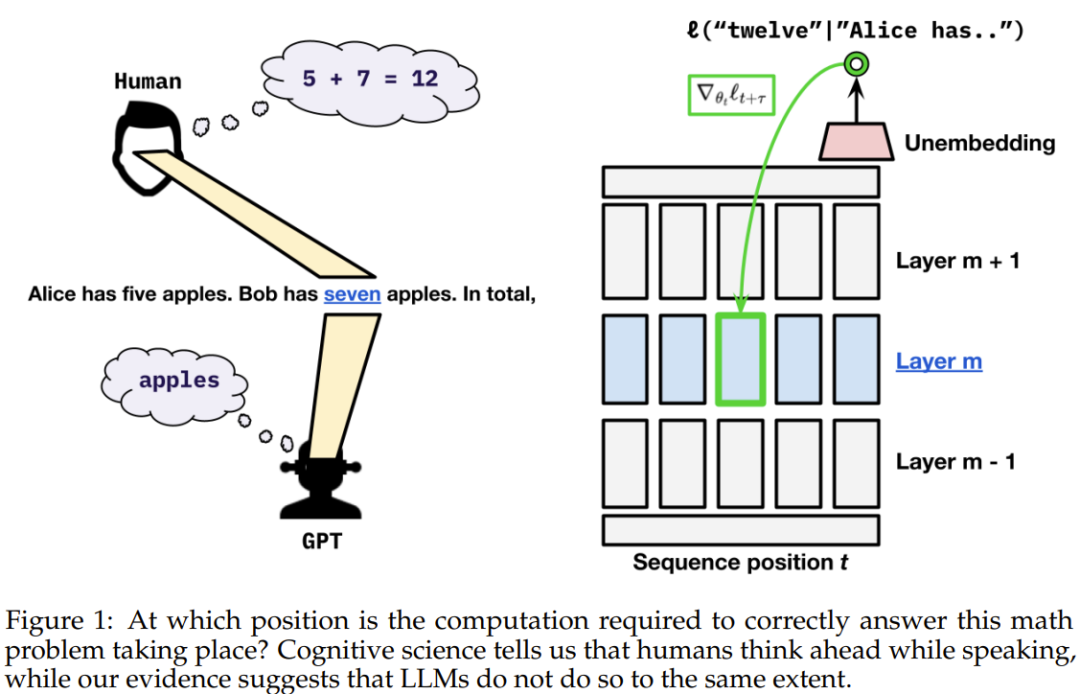
该团队表示:「在语言数据中,我们观察到贪婪地针对下一 token 损失进行优化与确保未来预测性能之间并不存在显著的权衡。」
因此我们大概可以看出来,Transformer 能否深谋远虑的问题似乎本质上是一个数据问题。

可以想象,也许未来我们能通过合适的数据整理方法让语言模型具备人类一样预先思考的能力。
以上是Transformer本來可以深謀遠慮,但就是不做的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 突破傳統缺陷檢測的界限,\'Defect Spectrum\'首次實現超高精度豐富語意的工業缺陷檢測。
Jul 26, 2024 pm 05:38 PM
突破傳統缺陷檢測的界限,\'Defect Spectrum\'首次實現超高精度豐富語意的工業缺陷檢測。
Jul 26, 2024 pm 05:38 PM
在現代製造業中,精準的缺陷檢測不僅是確保產品品質的關鍵,更是提升生產效率的核心。然而,現有的缺陷檢測資料集常常缺乏實際應用所需的精確度和語意豐富性,導致模型無法辨識特定的缺陷類別或位置。為了解決這個難題,由香港科技大學廣州和思謀科技組成的頂尖研究團隊,創新地開發了「DefectSpectrum」資料集,為工業缺陷提供了詳盡、語義豐富的大規模標註。如表一所示,相較於其他工業資料集,「DefectSpectrum」資料集提供了最多的缺陷標註(5438張缺陷樣本),最細緻的缺陷分類(125個缺陷類別
 英偉達對話模式ChatQA進化到2.0版本,上下文長度提到128K
Jul 26, 2024 am 08:40 AM
英偉達對話模式ChatQA進化到2.0版本,上下文長度提到128K
Jul 26, 2024 am 08:40 AM
開放LLM社群正是百花齊放、競相爭鳴的時代,你能看到Llama-3-70B-Instruct、QWen2-72B-Instruct、Nemotron-4-340B-Instruct、Mixtral-8x22BInstruct-v0.1等許多表現優良的模型。但是,相較於以GPT-4-Turbo為代表的專有大模型,開放模型在許多領域仍有明顯差距。在通用模型之外,也有一些專精關鍵領域的開放模型已被開發出來,例如用於程式設計和數學的DeepSeek-Coder-V2、用於視覺-語言任務的InternVL
 數百萬晶體資料訓練,解決晶體學相位問題,深度學習方法PhAI登Science
Aug 08, 2024 pm 09:22 PM
數百萬晶體資料訓練,解決晶體學相位問題,深度學習方法PhAI登Science
Aug 08, 2024 pm 09:22 PM
編輯|KX時至今日,晶體學所測定的結構細節和精度,從簡單的金屬到大型膜蛋白,是任何其他方法都無法比擬的。然而,最大的挑戰——所謂的相位問題,仍然是從實驗確定的振幅中檢索相位資訊。丹麥哥本哈根大學研究人員,開發了一種解決晶體相問題的深度學習方法PhAI,利用數百萬人工晶體結構及其相應的合成衍射數據訓練的深度學習神經網絡,可以產生準確的電子密度圖。研究表明,這種基於深度學習的從頭算結構解決方案方法,可以以僅2埃的分辨率解決相位問題,該分辨率僅相當於原子分辨率可用數據的10%到20%,而傳統的從頭算方
 GoogleAI拿下IMO奧數銀牌,數學推理模型AlphaProof面世,強化學習 is so back
Jul 26, 2024 pm 02:40 PM
GoogleAI拿下IMO奧數銀牌,數學推理模型AlphaProof面世,強化學習 is so back
Jul 26, 2024 pm 02:40 PM
對AI來說,奧數不再是問題了。本週四,GoogleDeepMind的人工智慧完成了一項壯舉:用AI做出了今年國際數學奧林匹克競賽IMO的真題,並且距拿金牌僅一步之遙。上週剛結束的IMO競賽共有六道賽題,涉及代數、組合學、幾何和數論。谷歌提出的混合AI系統做對了四道,獲得28分,達到了銀牌水準。本月初,UCLA終身教授陶哲軒剛剛宣傳了百萬美元獎金的AI數學奧林匹克競賽(AIMO進步獎),沒想到7月還沒過,AI的做題水平就進步到了這種水平。 IMO上同步做題,做對了最難題IMO是歷史最悠久、規模最大、最負
 PRO | 為什麼基於 MoE 的大模型更值得關注?
Aug 07, 2024 pm 07:08 PM
PRO | 為什麼基於 MoE 的大模型更值得關注?
Aug 07, 2024 pm 07:08 PM
2023年,幾乎AI的每個領域都在以前所未有的速度進化,同時,AI也不斷地推動著具身智慧、自動駕駛等關鍵賽道的技術邊界。在多模態趨勢下,Transformer作為AI大模型主流架構的局面是否會撼動?為何探索基於MoE(專家混合)架構的大模型成為業界新趨勢?大型視覺模型(LVM)能否成為通用視覺的新突破? ……我們從過去的半年發布的2023年本站PRO會員通訊中,挑選了10份針對以上領域技術趨勢、產業變革進行深入剖析的專題解讀,助您在新的一年裡為大展宏圖做好準備。本篇解讀來自2023年Week50
 為大模型提供全新科學複雜問答基準與評估體系,UNSW、阿貢、芝加哥大學等多家機構共同推出SciQAG框架
Jul 25, 2024 am 06:42 AM
為大模型提供全新科學複雜問答基準與評估體系,UNSW、阿貢、芝加哥大學等多家機構共同推出SciQAG框架
Jul 25, 2024 am 06:42 AM
編輯|ScienceAI問答(QA)資料集在推動自然語言處理(NLP)研究中發揮著至關重要的作用。高品質QA資料集不僅可以用於微調模型,也可以有效評估大語言模型(LLM)的能力,尤其是針對科學知識的理解和推理能力。儘管目前已有許多科學QA數據集,涵蓋了醫學、化學、生物等領域,但這些數據集仍有一些不足之處。其一,資料形式較為單一,大多數為多項選擇題(multiple-choicequestions),它們易於進行評估,但限制了模型的答案選擇範圍,無法充分測試模型的科學問題解答能力。相比之下,開放式問答
 準確率達60.8%,浙大基於Transformer的化學逆合成預測模型,登Nature子刊
Aug 06, 2024 pm 07:34 PM
準確率達60.8%,浙大基於Transformer的化學逆合成預測模型,登Nature子刊
Aug 06, 2024 pm 07:34 PM
編輯|KX逆合成是藥物發現和有機合成中的關鍵任務,AI越來越多地用於加快這一過程。現有AI方法性能不盡人意,多樣性有限。在實踐中,化學反應通常會引起局部分子變化,反應物和產物之間存在很大重疊。受此啟發,浙江大學侯廷軍團隊提出將單步逆合成預測重新定義為分子串編輯任務,迭代細化目標分子串以產生前驅化合物。並提出了基於編輯的逆合成模型EditRetro,該模型可以實現高品質和多樣化的預測。大量實驗表明,模型在標準基準資料集USPTO-50 K上取得了出色的性能,top-1準確率達到60.8%。
 Nature觀點,人工智慧在醫學上的測試一片混亂,該怎麼做?
Aug 22, 2024 pm 04:37 PM
Nature觀點,人工智慧在醫學上的測試一片混亂,該怎麼做?
Aug 22, 2024 pm 04:37 PM
編輯|ScienceAI基於有限的臨床數據,數百種醫療演算法已被批准。科學家們正在討論由誰來測試這些工具,以及如何最好地進行測試。 DevinSingh在急診室目睹了一名兒科患者因長時間等待救治而心臟驟停,這促使他探索AI在縮短等待時間中的應用。 Singh利用了SickKids急診室的分診數據,與同事們建立了一系列AI模型,用於提供潛在診斷和推薦測試。一項研究表明,這些模型可以加快22.3%的就診速度,將每位需要進行醫學檢查的患者的結果處理速度加快近3小時。然而,人工智慧演算法在研究中的成功只是驗證此
