

發布幾小時,微軟秒刪媲美GPT-4開源大模型!竟因忘記投毒測試

上週,微軟空降了一個堪稱GPT-4等級的開源模型WizardLM-2。
卻沒想到發布幾小時後,立刻被刪除了。
有網友突然發現,WizardLM的模型權重、公告帖子全部被刪除,並且不再微軟集合中,除了提到站點之外,卻找不到任何證據證明這個微軟的官方專案。
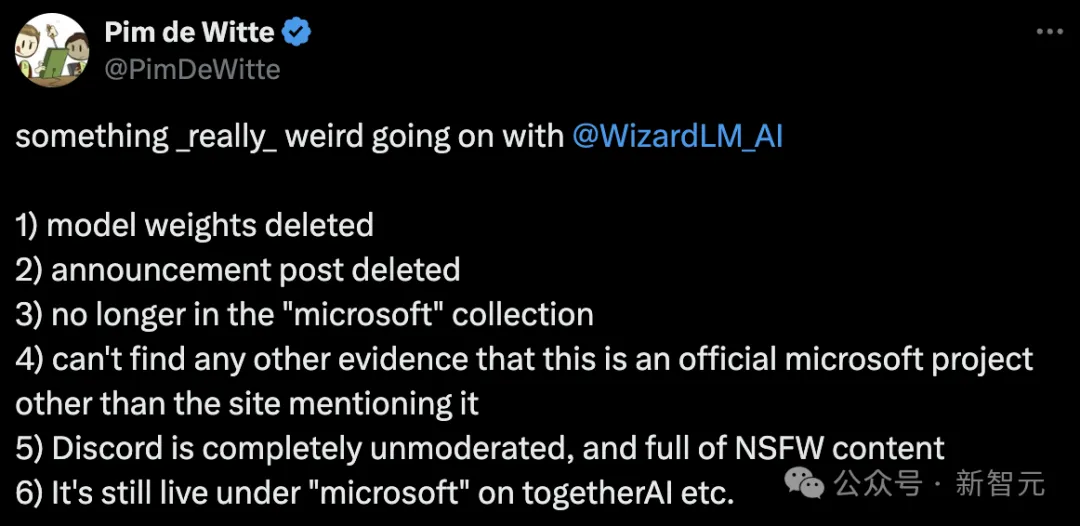
GitHub專案首頁已成404。
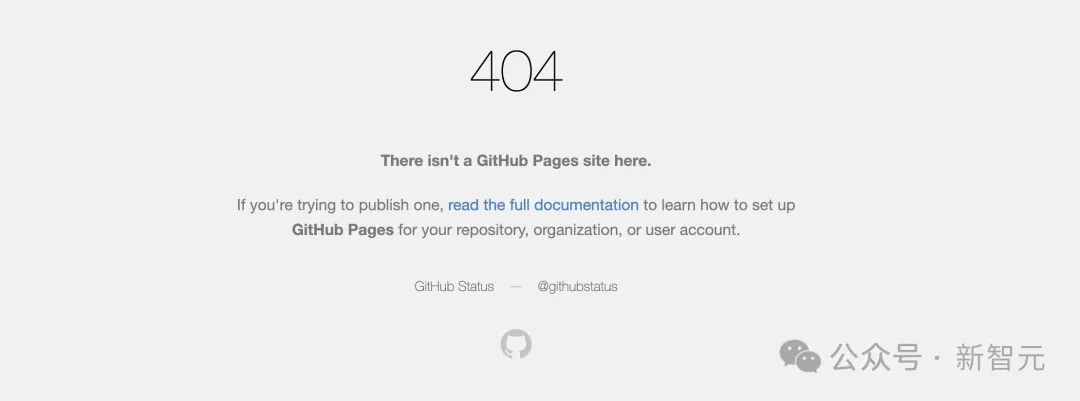
專案位址:https://wizardlm.github.io/
包含模型在HF上的權重,也全部消失了.....
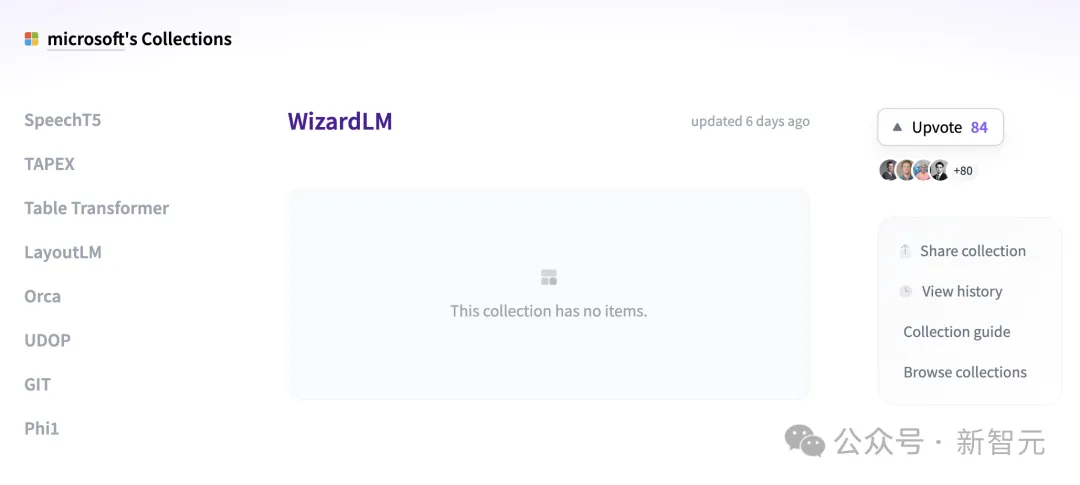
#全網滿臉疑惑,WizardLM怎麼沒了?

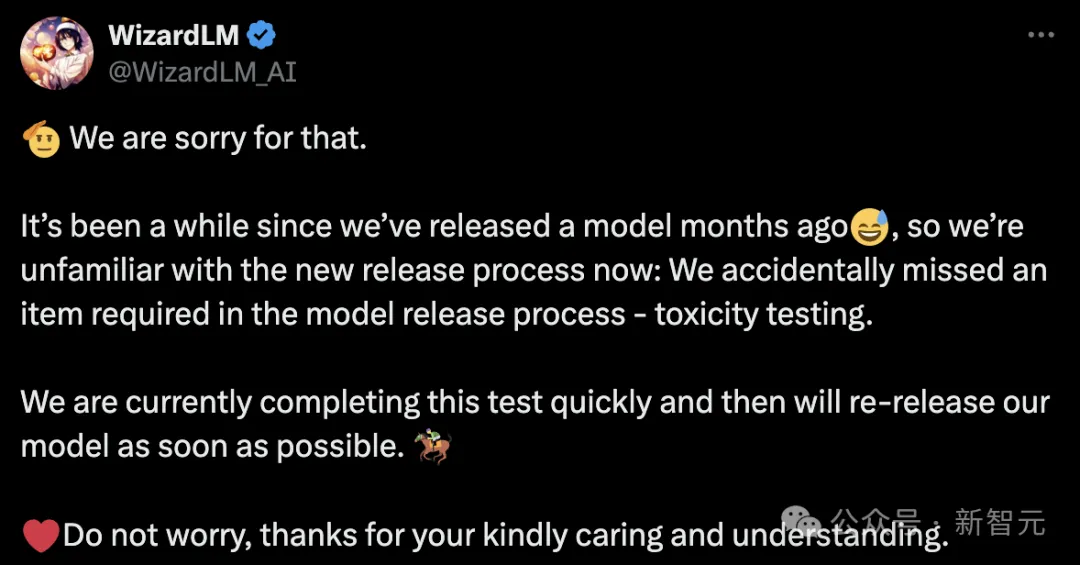
然鵝,微軟之所以這麼做,是因為團隊內部忘記對模型做「測試」。
隨後,微軟團隊現身道歉並解釋道,自幾個月前WizardLM發布以來有一段時間,所以我們對現在新的發布流程不太熟悉。
我們不小心遺漏了模型發佈流程中所需的一項內容:投毒測試
微軟WizardLM升級二代
去年6月,基於LlaMA微調而來的初代WizardLM一經發布,吸引了開源社群一大波關注。

論文網址:https://arxiv.org/pdf/2304.12244.pdf
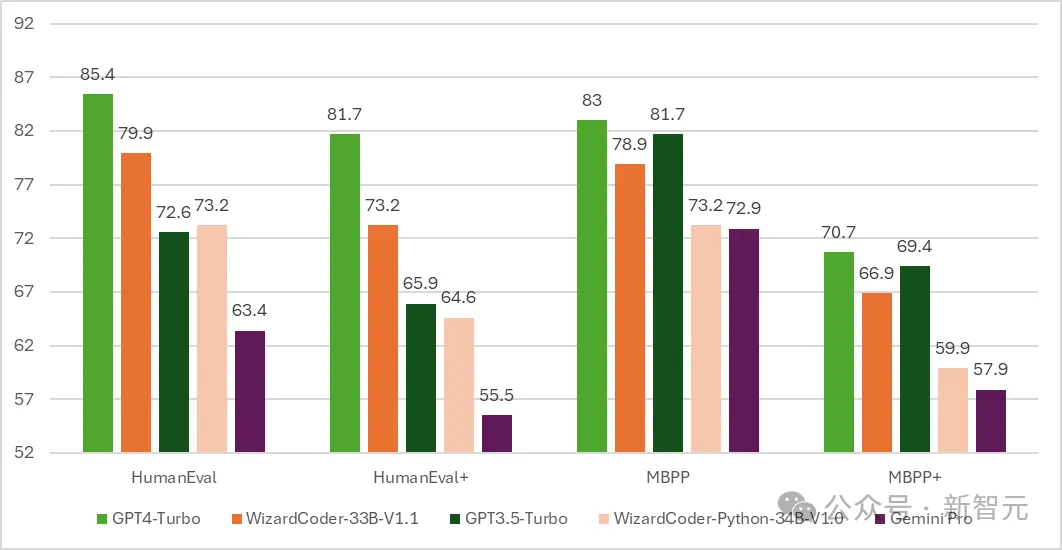
隨後,代碼版的WizardCoder誕生-一個基於Code Llama,利用Evol-Instruct微調的模型。
測試結果顯示,WizardCoder在HumanEval上的pass@1達到了驚人的 73.2%,超越了原始GPT-4。
時間推進到4月15日,微軟開發者宣布了新一代WizardLM,這次是從Mixtral 8x22B微調而來。
它包含了三個參數版本,分別是8x22B、70B和7B。

最值得一提的是,在MT-Bench基準測試中,新模型取得了領先的優勢。
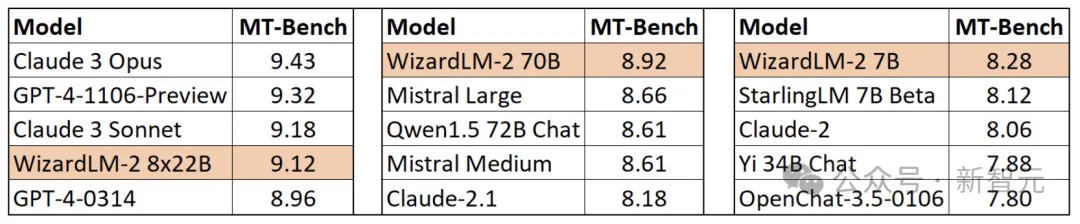
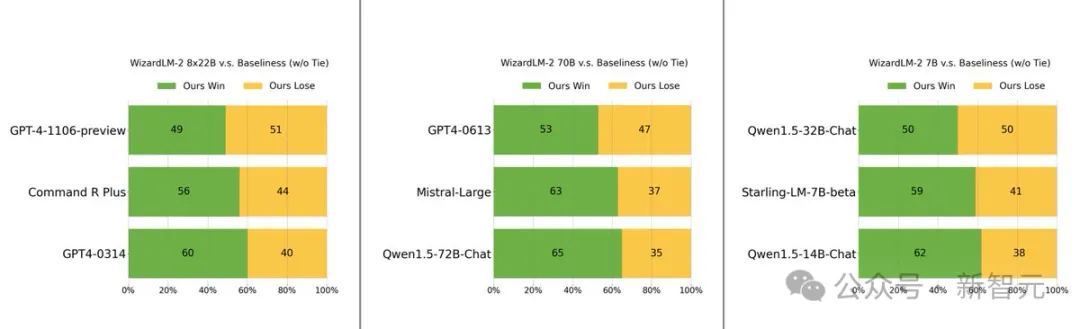
具體來說,最大參數版本的WizardLM 8x22B模型效能,幾乎接近GPT-4和Claude 3。
在相同參數規模下,70B版本位列第一。
而7B版本是最快的,甚至可以達到與,參數規模10倍大的領先模型相當的性能。
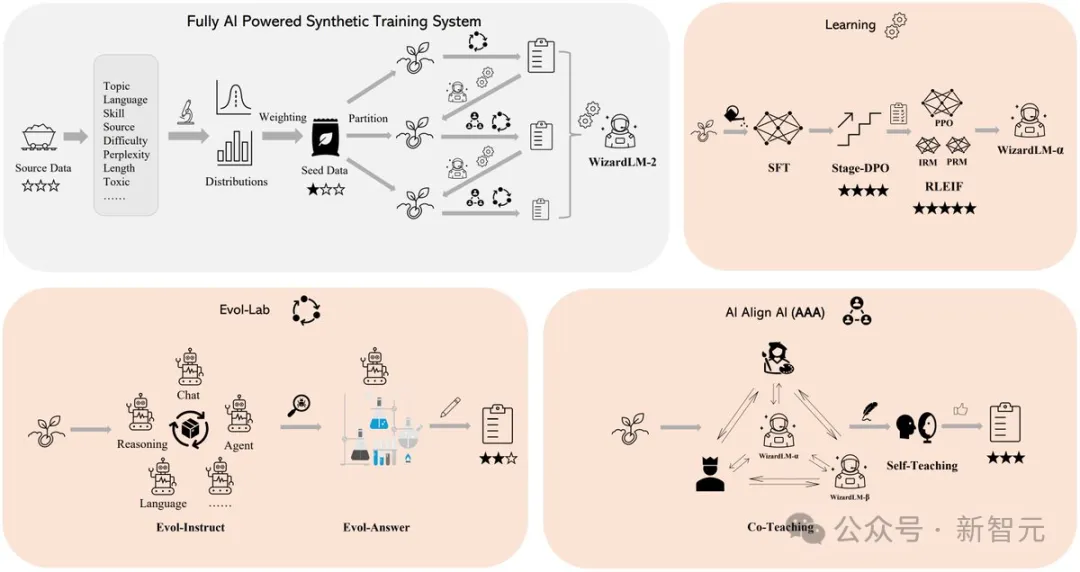
WizardLM 2出色表现的背后的秘诀在于,微软开发的革命性训练方法论Evol-Instruct。
Evol-Instruct利用大型语言模型,迭代地将初始指令集改写成越来越复杂的变体。然后,利用这些演化指令数据对基础模型进行微调,从而显著提高其处理复杂任务的能力。
另一个是强化学习框架RLEIF,也在WizardLM 2开发过程中起到了重要作用。
在WizardLM 2训练中,还采用了AI Align AI(AAA)方法,可以让多个领先的大模型相互指导和改进。
AAA框架由两个主要的组件组成,分别是「共同教学」和「自学」。
共同教学这一阶段,WizardLM和各种获得许可的开源和专有先进模型进行模拟聊天、质量评判、改进建议和缩小技能差距。

通过相互交流和提供反馈,模型可向同行学习并完善自身能力。
对于自学,WizardLM可通过主动自学,为监督学习生成新的进化训练数据,为强化学习生成偏好数据。
这种自学机制允许模型通过学习自身生成的数据和反馈信息来不断提高性能。
另外,WizardLM 2模型的训练使用了生成的合成数据。
在研究人员看来,大模型的训练数据日益枯竭,相信AI精心创建的数据和AI逐步监督的模型将是通往更强大人工智能的唯一途径。
因此,他们创建了一个完全由AI驱动的合成训练系统来改进WizardLM-2。
手快的网友,已经下载了权重
然而,在资料库被删除之前,许多人已经下载了模型权重。
在该模型被删除之前,几个用户还在一些额外的基准上进行了测试。
好在测试的网友对7B模型感到印象深刻,并称这将是自己执行本地助理任务的首选模型。

还有人对其进行了投毒测试,发现WizardLM-8x22B的得分为98.33,而基础Mixtral-8x22B的得分为89.46,Mixtral 8x7B-Indict的得分为92.93。
得分越高越好,也就是说WizardLM-8x22B还是很强的。

如果没有投毒测试,将模型发出来是万万不可的。
大模型容易产生幻觉,人尽皆知。
如果WizardLM 2在回答中输出「有毒、有偏见、不正确」的内容,对大模型来说并不友好。
尤其是,这些错误引来全网关注,对与微软自身来说也会陷入非议之中,甚至会被当局调查。
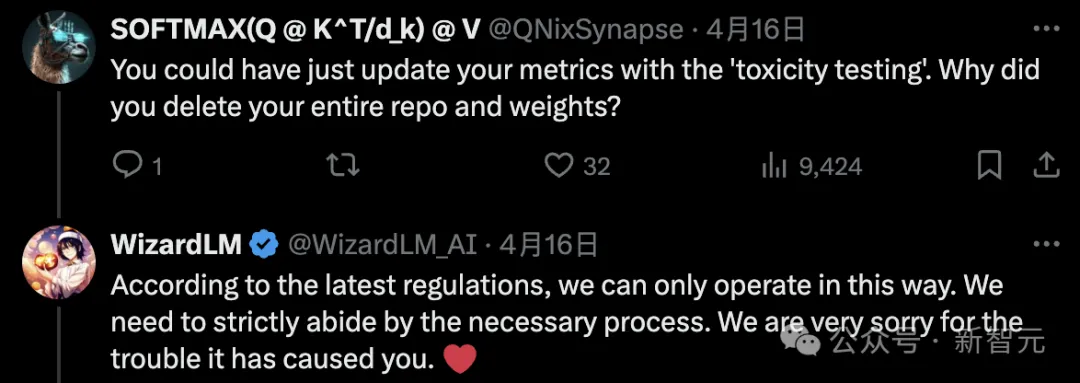
有网友疑惑道,你可以通过「投毒测试」更新指标。为什么要删除整个版本库和权重?
微软作者表示,根据内部最新的规定,只能这样操作。
也有人表示,我們就想要沒有「腦葉切除」的模型。

不過,開發者們還需要耐心等待,微軟團隊承諾,會在測試完成後重新上線。
以上是發布幾小時,微軟秒刪媲美GPT-4開源大模型!竟因忘記投毒測試的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 h5項目怎麼運行
Apr 06, 2025 pm 12:21 PM
h5項目怎麼運行
Apr 06, 2025 pm 12:21 PM
運行 H5 項目需要以下步驟:安裝 Web 服務器、Node.js、開發工具等必要工具。搭建開發環境,創建項目文件夾、初始化項目、編寫代碼。啟動開發服務器,使用命令行運行命令。在瀏覽器中預覽項目,輸入開發服務器 URL。發布項目,優化代碼、部署項目、設置 Web 服務器配置。
 Beego ORM中如何指定模型關聯的數據庫?
Apr 02, 2025 pm 03:54 PM
Beego ORM中如何指定模型關聯的數據庫?
Apr 02, 2025 pm 03:54 PM
在BeegoORM框架下,如何指定模型關聯的數據庫?許多Beego項目需要同時操作多個數據庫。當使用Beego...
 Gitee Pages靜態網站部署失敗:單個文件404錯誤如何排查和解決?
Apr 04, 2025 pm 11:54 PM
Gitee Pages靜態網站部署失敗:單個文件404錯誤如何排查和解決?
Apr 04, 2025 pm 11:54 PM
GiteePages靜態網站部署失敗:404錯誤排查與解決在使用Gitee...
 Go語言中哪些庫是由大公司開發或知名的開源項目提供的?
Apr 02, 2025 pm 04:12 PM
Go語言中哪些庫是由大公司開發或知名的開源項目提供的?
Apr 02, 2025 pm 04:12 PM
Go語言中哪些庫是大公司開發或知名開源項目?在使用Go語言進行編程時,開發者常常會遇到一些常見的需求,�...
 在Go語言中使用Redis Stream實現消息隊列時,如何解決user_id類型轉換問題?
Apr 02, 2025 pm 04:54 PM
在Go語言中使用Redis Stream實現消息隊列時,如何解決user_id類型轉換問題?
Apr 02, 2025 pm 04:54 PM
Go語言中使用RedisStream實現消息隊列時類型轉換問題在使用Go語言與Redis...
 H5頁面製作是否需要持續維護
Apr 05, 2025 pm 11:27 PM
H5頁面製作是否需要持續維護
Apr 05, 2025 pm 11:27 PM
H5頁面需要持續維護,這是因為代碼漏洞、瀏覽器兼容性、性能優化、安全更新和用戶體驗提升等因素。有效維護的方法包括建立完善的測試體系、使用版本控制工具、定期監控頁面性能、收集用戶反饋和製定維護計劃。

 在Go編程中,如何正確管理Mysql和Redis的連接與釋放資源?
Apr 02, 2025 pm 05:03 PM
在Go編程中,如何正確管理Mysql和Redis的連接與釋放資源?
Apr 02, 2025 pm 05:03 PM
Go編程中的資源管理:Mysql和Redis的連接與釋放在學習Go編程過程中,如何正確管理資源,特別是與數據庫和緩存�...
