

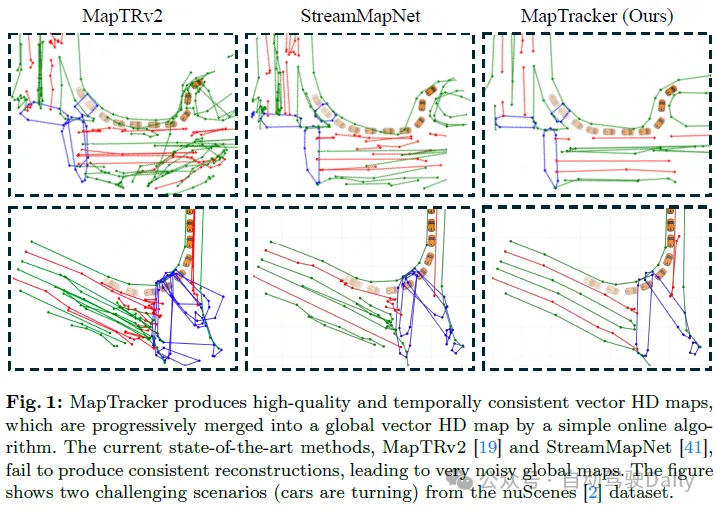
線上地圖還能這樣? MapTracker:用追蹤實現線上地圖新SOTA!

写在前面&笔者的个人理解
该算法允许在线高精度地图构建。我们的方法MapTracker将传感器流累积到两种显示的内存缓冲区中:1)鸟瞰图(BEV)空间中的Raster latents和2)道路元素(即人行横道、车道线和道路边界)上的Vector latents。该方法借鉴了目标跟踪中的查询传播范式,该范式明确地将前一帧的跟踪道路元素与当前帧相关联,同时融合了与距离步幅的内存 latents 子集,以进
开源链接:https://map-tracker.github.io/
总结来说,本文的主要贡献如下:
- 一种新的矢量HD建图算法,将HD建图公式化为跟踪任务,并利用两种表示中的memory latents历史来实现时间一致性;
- 一种改进的矢量HD建图基准,具有时间一致的GT和一致性感知的mAP metric;
- SOTA性能!在传统和新的度量上比当前的最佳方法有显著改进。
相关工作回顾
本文通过两种方式来思考和解决一致向量HD建图问题。我们首先回顾了基于视觉的自动驾驶中使用Transformer和记忆设计的视觉目标跟踪的最新趋势。最后,我们讨论了竞争矢量HD建图方法。
使用transformers进行视觉目标跟踪。视觉目标跟踪有着悠久的历史,其中端到端transformer方法由于其简单性而成为最近的趋势。TrackFormer、TransTrack和MOTR利用注意力机制和跟踪查询来显式关联跨帧的实例。MeMOT和MeMOTR进一步扩展了具有记忆机制的跟踪transformer,以获得更好的长期一致性。本文通过将跟踪查询与更稳健的内存机制结合起来,将矢量HD建图公式化为跟踪任务。
自动驾驶中的Memory设计。单帧自动驾驶系统在处理遮挡、传感器故障或复杂环境方面存在困难。具有Memory的时间建模提供了有希望的补充。存在许多用于光栅BEV功能的Memory设计,这些功能构成了大多数自动驾驶任务的基础。BEVDet4D和BEVFormerv2将多个过去帧的特征叠加为Memory,但计算随着历史长度线性扩展,难以捕获长期信息。VideoBEV跨帧传播BEV光栅查询,以循环积累信息。在向量域中,Sparse4Dv2使用类似的RNN风格的内存进行目标查询,而Sparse4Dv3进一步使用时间去噪进行稳健的时间学习。这些思想已被矢量HD建图方法部分纳入。本文针对道路元素的光栅BEV潜伏时间和矢量潜伏时间提出了一种新的存储器设计。
矢量HD建图。传统上,高精地图是用基于SLAM的方法离线重建的,然后是人工管理,需要高昂的维护成本。随着精度和效率的提高,在线矢量高精地图算法比离线地图算法更受关注,这将简化生产流程并处理地图更改。HDMapNet通过后处理将光栅图分割转化为矢量图实例,并建立了第一个矢量HD建图基准。VectorMapNet和MapTR都利用基于DETR的transformer进行端到端预测。前者自回归地预测每个检测到的曲线的顶点,而后者使用分层查询和匹配损失来同时预测所有顶点。MapTRv2通过辅助任务和网络修改进一步补充了MapTR。曲线表示、网络设计和训练范式是其他工作的重点。StreamMapNet通过借鉴BEV感知中的流思想,朝着一致建图迈出了一步。该想法将过去的信息累积为memory latents,并作为条件(即条件检测框架)通过。SQD MapNet模仿DN-DETR,提出了时间曲线去噪以促进时间学习。
MapTracker
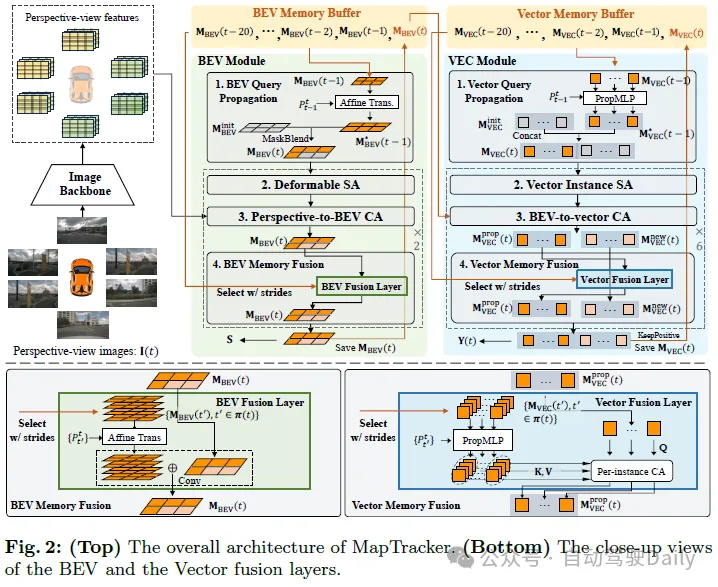
鲁棒记忆机制是MapTracker的核心,它将传感器流累积为两种表示的latent memories:1)自上而下的BEV坐标系中车辆周围区域的鸟瞰(BEV)记忆作为潜在图像;和2)道路元素(即,行人专用区交叉口、车道线和道路边界)的矢量(VEC)记忆作为一组潜在量。
兩個簡單的想法與memory機制實現了一致的建圖。第一個想法是使用歷史的memory buffer,而不是當前幀的單一memory。單一memory應該保存整個歷史的信息,但很容易丟失memory,尤其是在有大量車輛遮擋道路結構的雜亂環境中。具體地說,為了效率和覆蓋率,我們基於車輛運動在每一幀選擇過去latent memories的子集進行融合。第二個想法是將線上高精地圖制定為追蹤任務。 VEC memory機制保持每個道路元素的memory latents期序列,並透過借用追蹤文獻中的查詢傳播範式使該公式變得簡單。本節的其餘部分解釋了我們的神經架構(見圖2和圖3),包括BEV和VEC memory buffers及其對應的網路模組,然後介紹了訓練細節。
Memory Buffers
BEV memory是BEV座標系中的2D latent,以車輛為中心並在第t幀處定向。空間維度(即50×100)涵蓋矩形區域,左/右15m,前/後30m。每個記憶體潛伏時間累積整個過去的訊息,而buffer在最後20幀中保持這樣的memory latents時間,使得memory機制冗餘但穩健。
VECmemory是一組向量潛伏時間,每個向量latents時間累積直到幀t的活動道路元素的資訊。活動元素的數量隨幀而變化。 buffer保存過去20幀的latent vectors及其在幀之間的對應關係(即,對應於相同道路元素的向量潛伏序列)。
BEV Module

#輸入是1)由影像主幹處理的機載環視圖像的CNN特徵及其相機參數; 2) BEV memory buffer和3)車輛運動。以下內容解釋了BEV模組體系結構的四個組成部分及其輸出。
- BEV Query Propagation:BEV memory是車輛座標系中的2D latent image。仿射變換和雙線性插值將目前BEV memory初始化為先前的BEV memory。對於變換後位於latent image之外的像素,每像素可學習的嵌入向量是初始化,其操作在圖3中表示為「MaskBlend」。
- Deformable Self-Attention:可變形的自註意力層豐富了BEV memory。
- Perspective-to-BEV Cross-Attention:與StreamMapNet類似,BEVFormer的空間可變形交叉注意力層將透視圖資訊注入MBEV(t)。
- BEV Memory Fusion:buffer中的memory latents被融合以豐富MBEV(t)。使用所有的memories在計算上是昂貴且冗餘的。
輸出是1)保存到buffer並傳遞到VEC模組的最終memory MBEV(t);以及2)由分割頭推理並用於損失計算的光柵化道路元素幾何圖形S(t )。分割頭是一個線性投影模組,將memory latent中的每個像素投影到2×2的分割掩模,從而產生100×200的掩模。
VEC Module
輸入是BEV memory MBEV(t)和vector memory buffer以及車輛運動;
- ##Vector Query Propagation:vector memory是活動道路元素的一組潛在向量。
- Vector Instance Self Attention:標準的自註意力層;
- BEV-to-Vector Cross Attention:Multi-Point Attention;
- Vector Memory Fusion:對於目前記憶體MVEC(t)中的每個潛在向量,將緩衝器中與相同道路元素相關聯的潛在向量進行融合以豐富其表示。相同的跨步幀選擇選擇四個潛在向量,其中對於一些具有短跟踪歷史的道路元素,所選的幀π(t)將不同且更少。例如,追蹤了兩幀的元素在buffer中只有兩個latents。
Training
BEV loss: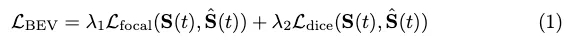
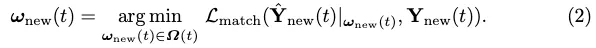
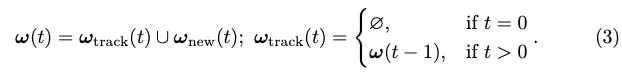
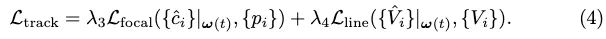
轉換損失。我們藉用StreamMapNet中的轉換損失Ltrans來訓練PropMLP,這強制潛在空間中的查詢轉換保持向量幾何和類別類型。最後的訓練損失是:
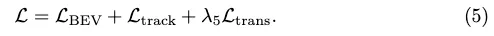
Consistent Vector HD Mapping Benchmarks
Consistent ground truth
MapTR從nuScenes和Agroverse2資料集創建了向量HD建圖基準,被許多後續研究採用。然而,人行橫道是天真地合併在一起的,而且跨框架不一致。分割線也與其圖形追蹤過程的失敗不一致(對於Argoverse2)。
StreamMapNet繼承了VectorMapNet的程式碼,並創建了一個具有更好真實性的基準,該基準已在研討會挑戰中使用。然而,仍然存在一些問題。對於Argoverse2,分隔線有時會分割為較短的線段。對於nuScenes,大型行人穿越道有時會分割出小環路,其不一致性在每個畫面中隨機出現,導致暫時不一致的表示。我們在附錄中提供了現有基準問題的視覺化。
我們改進了現有基準的處理程式碼,以(1)增強每個影格的GT幾何結構,然後(2)計算它們在影格之間的對應關係,形成GT「軌跡」。
(1) 增強每個畫面幾何圖形。我們繼承並改進了在社群中流行的MapTR程式碼庫,同時進行了兩個更改:用StreamMapNet中的處理取代步行區處理,並透過更多的幾何約束來提高品質;以及透過增強圖追蹤演算法來處理原始註釋的雜訊來增強除法器處理中的時間一致性(僅適用於Argoverse2)。
(2) Forming tracks。給定每幀道路元素的幾何結構,我們求解每對相鄰幀之間的最優二分匹配問題,以建立道路元素的對應關係。成對的對應關係被連結以形成道路元素的軌跡。一對道路元素之間的匹配分數定義如下。道路元素幾何圖形是多邊形曲線或環形。我們根據車輛運動將舊幀中的元素幾何體轉換為新幀,然後將具有一定厚度的兩個曲線/循環光柵化為實例遮罩。他們在並集上的交集是匹配的分數。
Consistency-aware mAP metric
mAP度量不會懲罰暫時不一致的重建。我們將重建的道路元素和每個幀中的地面實況與倒角距離獨立匹配,如在標準mAP過程中一樣,然後通過以下檢查消除暫時不一致的匹配。首先,對於不預測追蹤資訊的基線方法,我們使用與獲得GT時間對應關係相同的演算法來形成重建道路元素的軌跡(我們還擴展了演算法,透過權衡速度來重新識別丟失的元素;詳細資訊請參閱附錄)。接下來,讓「祖先」是屬於前一幀中相同軌跡的道路元素。從序列的一開始,如果它們的祖先中有任何一個不匹配,我們就會將每個幀匹配(重建元素和地面實況元素)刪除為暫時不一致。然後利用剩餘的暫時一致的配對來計算標準mAP。
實驗
我們基於StreamMapNet程式庫建立我們的系統,同時使用8個NVIDIA RTX A5000 GPU在nuScenes上為72個epoch和Argoverse2上為35個epoch訓練我們的模型。三個訓練階段的批量大小分別為16、48和16。訓練大約需要三天時間,而推理速度大約為10 FPS。在解釋了資料集、指標和基線方法之後,本節提供了實驗結果。
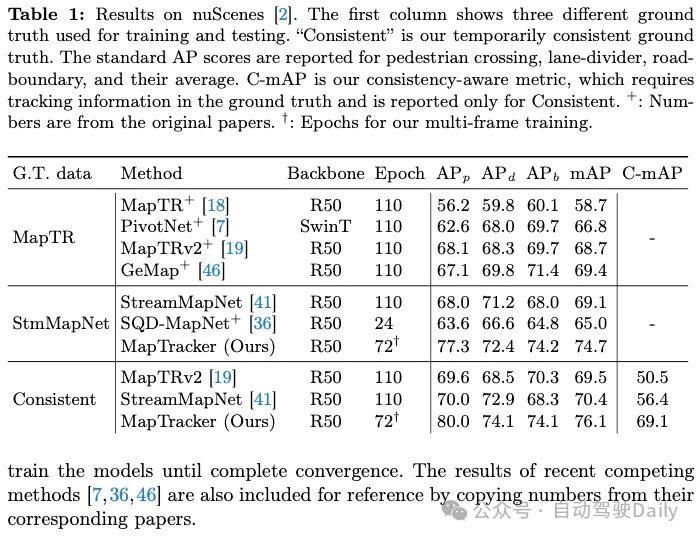
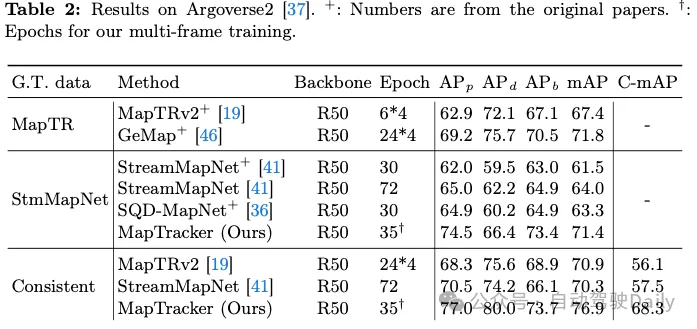
我們的貢獻之一是在兩個現有的對應物(即MapTR和StreamMapNet)上實現了暫時一致的地面實況(GT)。表1和表2顯示了在三個GT中的一個上訓練和測試系統的結果(如第一列所示)。由於我們的程式碼庫是基於StreamMapNet的,我們在StreamMapNet GT和我們的臨時一致GT上評估我們的系統。
nuScenes结果。表1显示,MapTRv2和StreamMapNet都使用我们的GT实现了更好的mAP,这是我们在修复其原始GT中的不一致性时所期望的。StreamMapNet的改进略高,因为它具有时间建模(而MapTR没有),并利用了数据中的时间一致性。MapTracker显著优于竞争方法,尤其是在我们的一致性GT在原始和一致性意识mAP得分中分别提高了8%和22%以上的情况下。注意,MapTracker是唯一产生明确跟踪信息(即,重构元素在帧之间的对应关系)的系统,这是一致性区域mAP所需要的。一个简单的匹配算法为基线方法创建轨迹。
Argoverse2结果。表2显示,MapTRv2和StreamMapNet都通过我们一致的GT获得了更好的mAP分数,它除了暂时一致之外,还具有更高质量的GT(用于人行横道和分隔物),使所有方法都受益。MapTracker在所有设置中都以显著的优势(即分别为11%或8%)优于所有其他基线。一致性意识评分(C-mAP)进一步证明了我们卓越的一致性,比StreamMapNet提高了18%以上。
Results with geographically non-overlapping data
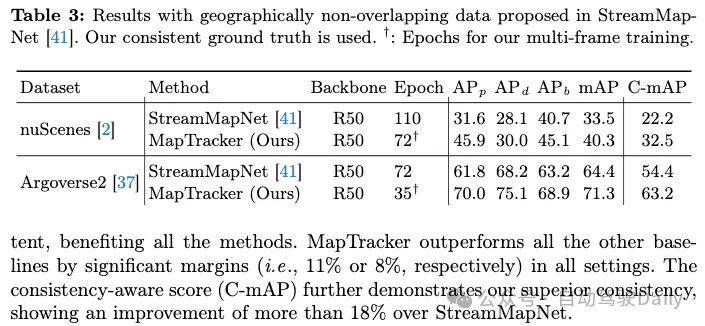
nuScenes和Agroverse2数据集的官方训练/测试划分具有地理重叠(即,训练/测试中出现相同的道路),这允许过度拟合。表3比较了StreamMapNet和MapTracker提出的基于地理上不重叠分割的最佳基线方法。MapTracker始终以显著的优势表现出色,表现出强大的跨场景泛化能力。请注意,对于这两种方法,nuScenes数据集的性能都会降低。经过仔细检查,道路要素的检测是成功的,但回归的坐标误差很大,导致性能低下。附录提供了更多分析。
Ablation studies
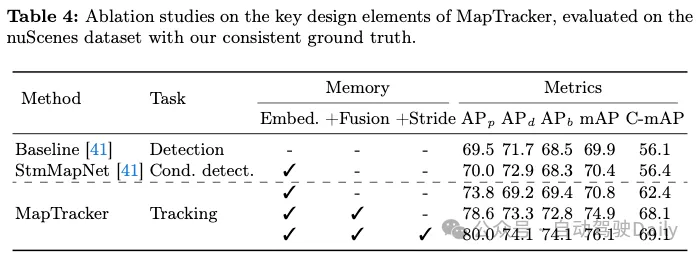
表4中的消融研究证明了MapTracker中关键设计元素的贡献。第一个“基线”条目是StreamMapNet,它没有时间推理能力(即没有BEV和矢量流存储器和模块)。第二个条目是StreamMapNet。两种方法都训练了110个时期,直到完全收敛。最后三个条目是MapTracker的变体,包含或不包含关键设计元素。第一种变体丢弃BEV/VEC模块中的存储器融合组件。该变体利用跟踪公式,但依赖于单个BEV/VEC存储器来保存过去的信息。第二种变体添加了内存缓冲区和内存融合组件,但没有跨步,即使用最新的4帧进行融合。这种变体提高了性能,证明了我们记忆机制的有效性。最后一种变体添加了内存跨步,从而更有效地利用了内存机制并提高了性能。
Qualitative evaluations

图4显示了MapTracker和基线方法在nuScenes和Argoverse2数据集上的定性比较。为了更好地可视化,我们使用一种简单的算法将每帧矢量HD地图合并为全局矢量HD地图。有关合并算法和每帧重建的可视化的详细信息,请参阅附录。MapTracker产生了更精确、更干净的结果,显示出卓越的整体质量和时间一致性。对于车辆正在转弯或没有轻微向前移动的场景(包括图1中的两个示例),StreamMapNet和MapTRv2可能会产生不稳定的结果,从而导致破碎和嘈杂的合并结果。这主要是因为基于检测的公式难以在复杂的车辆运动下维持时间相干重建。
结论
本文介绍了MapTracker,它将在线HD映射公式化为跟踪任务,并利用raster and vector latents的历史来保持时序一致性。我们使用查询传播机制来跨帧关联被跟踪的道路元素,并将所选择的memory entries的子集与距离步幅融合以增强一致性。我们还通过使用跟踪标签生成一致的GT,并通过时序一致性检查增强原始mAP指标,来改进现有的基准。当使用传统度量进行评估时,MapTracker在nuScenes和Agroverse2数据集上显著优于现有方法,并且当使用我们的一致性感知度量进行评估后,它表现出了卓越的时序一致性。
限制:我們確定了MapTracker的兩個限制。首先,目前的追蹤公式不處理道路元素的合併和分割(例如,U形邊界在未來的幀中分割成兩條直線,反之亦然)。基本事實也不能恰當地代表他們。其次,我們的系統仍處於10 FPS,即時效能有點不足,尤其是在關鍵的崩潰事件。優化效率和處理更複雜的現實世界道路結構是我們未來的工作。
以上是線上地圖還能這樣? MapTracker:用追蹤實現線上地圖新SOTA!的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 git怎麼下載項目到本地
Apr 17, 2025 pm 04:36 PM
git怎麼下載項目到本地
Apr 17, 2025 pm 04:36 PM
要通過 Git 下載項目到本地,請按以下步驟操作:安裝 Git。導航到項目目錄。使用以下命令克隆遠程存儲庫:git clone https://github.com/username/repository-name.git
 git怎麼更新代碼
Apr 17, 2025 pm 04:45 PM
git怎麼更新代碼
Apr 17, 2025 pm 04:45 PM
更新 git 代碼的步驟:檢出代碼:git clone https://github.com/username/repo.git獲取最新更改:git fetch合併更改:git merge origin/master推送更改(可選):git push origin master
 git怎麼刪除倉庫
Apr 17, 2025 pm 04:03 PM
git怎麼刪除倉庫
Apr 17, 2025 pm 04:03 PM
要刪除 Git 倉庫,請執行以下步驟:確認要刪除的倉庫。本地刪除倉庫:使用 rm -rf 命令刪除其文件夾。遠程刪除倉庫:導航到倉庫設置,找到“刪除倉庫”選項,確認操作。
 git下載不動怎麼辦
Apr 17, 2025 pm 04:54 PM
git下載不動怎麼辦
Apr 17, 2025 pm 04:54 PM
解決 Git 下載速度慢時可採取以下步驟:檢查網絡連接,嘗試切換連接方式。優化 Git 配置:增加 POST 緩衝區大小(git config --global http.postBuffer 524288000)、降低低速限制(git config --global http.lowSpeedLimit 1000)。使用 Git 代理(如 git-proxy 或 git-lfs-proxy)。嘗試使用不同的 Git 客戶端(如 Sourcetree 或 Github Desktop)。檢查防火
 git怎麼合併代碼
Apr 17, 2025 pm 04:39 PM
git怎麼合併代碼
Apr 17, 2025 pm 04:39 PM
Git 代碼合併過程:拉取最新更改以避免衝突。切換到要合併的分支。發起合併,指定要合併的分支。解決合併衝突(如有)。暫存和提交合併,提供提交消息。
 如何解決PHP項目中的高效搜索問題? Typesense助你實現!
Apr 17, 2025 pm 08:15 PM
如何解決PHP項目中的高效搜索問題? Typesense助你實現!
Apr 17, 2025 pm 08:15 PM
在開發一個電商網站時,我遇到了一個棘手的問題:如何在大量商品數據中實現高效的搜索功能?傳統的數據庫搜索效率低下,用戶體驗不佳。經過一番研究,我發現了Typesense這個搜索引擎,並通過其官方PHP客戶端typesense/typesense-php解決了這個問題,大大提升了搜索性能。
 git commit怎麼用
Apr 17, 2025 pm 03:57 PM
git commit怎麼用
Apr 17, 2025 pm 03:57 PM
Git Commit 是一種命令,將文件變更記錄到 Git 存儲庫中,以保存項目當前狀態的快照。使用方法如下:添加變更到暫存區域編寫簡潔且信息豐富的提交消息保存並退出提交消息以完成提交可選:為提交添加簽名使用 git log 查看提交內容
 git怎麼更新本地代碼
Apr 17, 2025 pm 04:48 PM
git怎麼更新本地代碼
Apr 17, 2025 pm 04:48 PM
如何更新本地 Git 代碼?用 git fetch 從遠程倉庫拉取最新更改。用 git merge origin/<遠程分支名稱> 將遠程變更合併到本地分支。解決因合併產生的衝突。用 git commit -m "Merge branch <遠程分支名稱>" 提交合併更改,應用更新。
