

8B文字多模態大模型指標逼近GPT4V,位元組、華師、華科聯合提出TextSquare


AIxiv专栏是本站发布学术、技术内容的栏目。 过去几年,本站AIxiv专栏接收报道道约2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道邮箱。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com。
近期,多模态大模型(MLLM)在文本中心的VQA领域取得了显著进展,尤其是多个闭源模型,例如:GPT4V 和 Gemini,甚至在某些方面展现了超越人类能力的表现。但是,开源模型的性能还远远落后于闭源模型,最近许多开创性的研究,例如:MonKey、LLaVAR、TG-Doc、ShareGPT4V 等已经开始关注指令微调数据不足的问题。尽管这些努力取得了显著的效果,但仍存在一些问题,图像描述数据和 VQA 数据属于不同的领域,图像内容呈现的粒度和范围存在不一致性。此外,合成数据的规模相对较小,使得 MLLM 无法充分发挥潜力。

论文标题:TextSquare: Scaling up Text-Centric Visual Instruction Tuning
论文地址:https://arxiv.org/abs/2404.12803
为了减少这一
VQA 数据生成
Square 策略方法包括四个步骤:自问 (Self-Questioning)、回答 (Self-Answering)、推理 (Self-Reasoning) 和评估 (Self-Evaluation)。Self-Questioning 利用MLLM 在文本图像分析和理解方面的能力生成与图像中文本内容相关的问题。Self-Answering 利用各种提示技术,如:思维链 CoT 和少样本,提供回答这些问题。Self-Reasoning 利用MLLMs 强大的推理能力,生成模型背后的推理过程。Self-Evaluation 评估问题的有效性、与图像文本内容的相关性以及答案的准确性,从而提高数据质量并减少偏见。
基于 Square 方法,研究者从各种公共来源收集了一组多样化的含有大量文本的图像,包括自然场景、图表、表单、收据、书籍、PPT、PDF 等构建了 Square-10M,并基于这个数据集训练了以文本理解为中心的 MLLM TextSquare-8B。
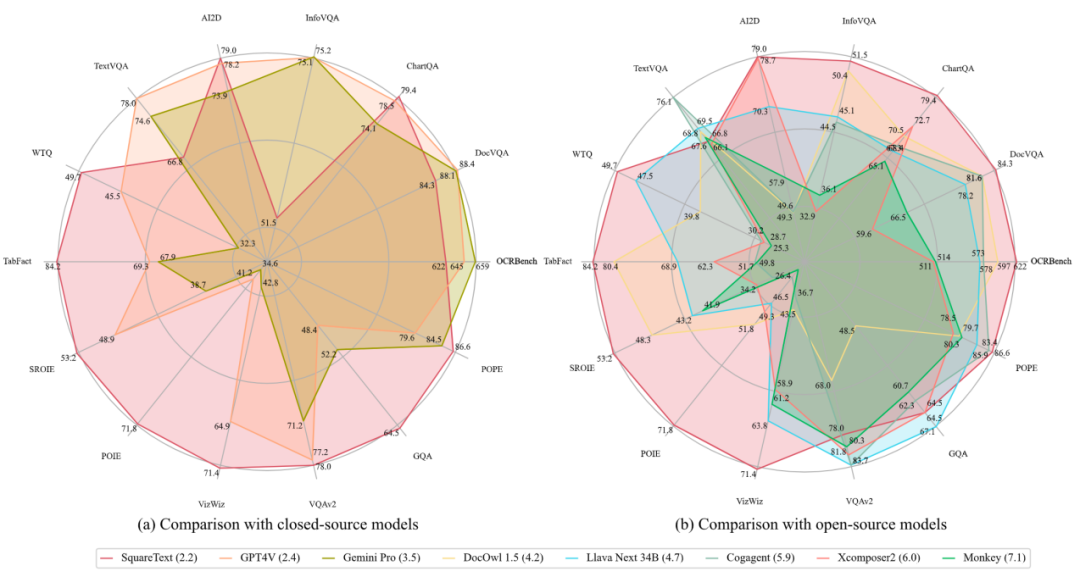
如图 1 所示,TextSquare-8B 在多个 benchmark 可取得与 GPT4V 和 Gemini 相媲美或更优的效果,并显著超过了其他开源模型。TextSquare 实验验证了推理数据对 VQA 任务的积极影响,证明了其能够在减少幻觉的同时提升模型性能。
此外,通过利用大规模的数据集,揭示了指令调整数据规模、训练收敛损失和模型性能之间的关系。尽管少量的指令调整数据可以很好地训练 MLLM,随着指令调整数据的不断扩大,模型的性能能得到进一步增长,指令微调数据和模型之间也存在着相对应的 scaling law。
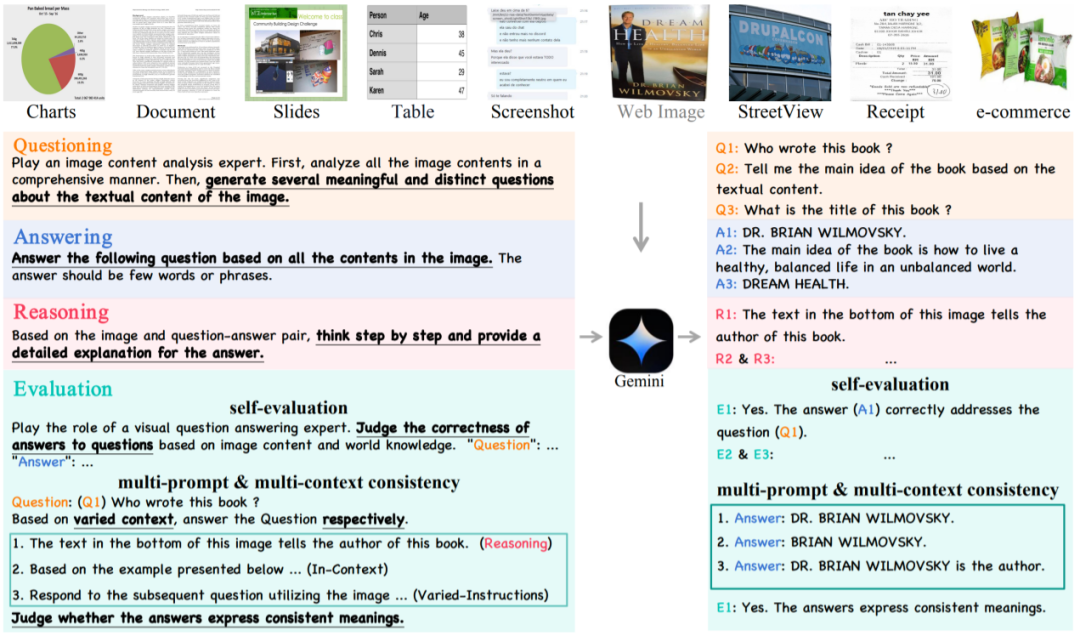
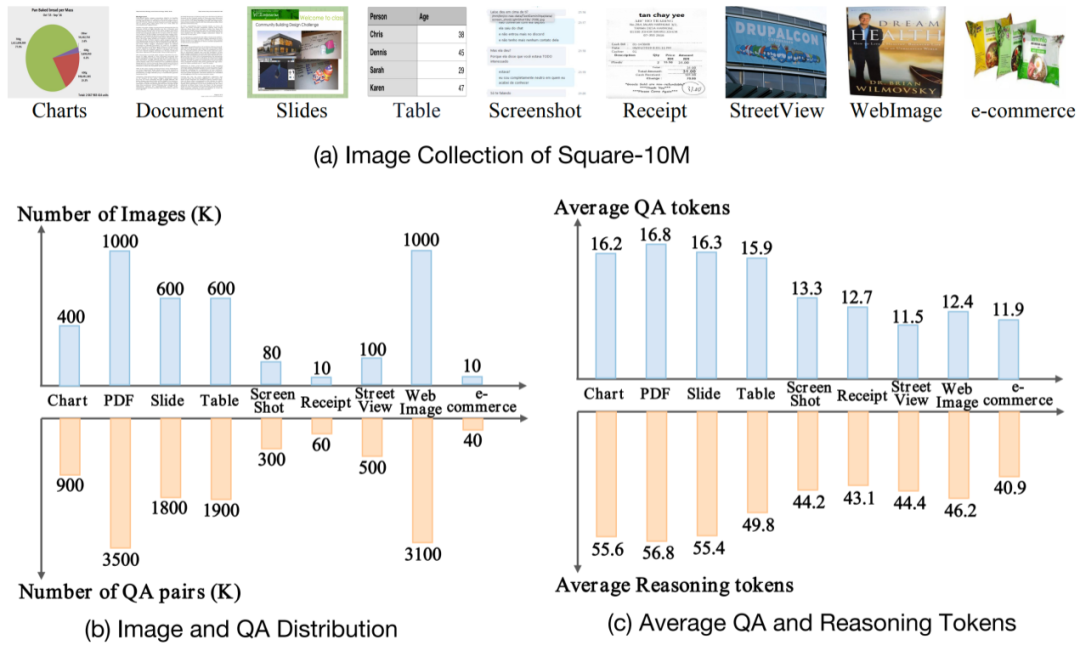
图 3 Square-10M 的图像分布和 QA 分布等详细情况
数据收集
資料收集策略的主要目標是涵蓋廣泛的現實世界文本豐富的場景。為此,研究者收集了 380 萬張的富文本的圖像。這些圖像表現出不同的特性,例如,圖表和表格側重於具有密集統計資訊的文字元素;PPT、螢幕截圖和WebImage 是為文字和突出視覺資訊之間的互動而設計的;文件/ PDF、收據和電子商務包含具有精細和密集文字的圖像;街景源自於自然場景。收集到的圖像形成了現實世界中文本元素的映射,並構成了研究以文本為中心的 VQA 的基礎。
資料產生
研究者利用Gemini Pro 的多模態理解能力從特定資料來源選擇影像,並透過自問、自答、自我推理三個階段產生VQA 及推理上下文對。
Self-Question: 這個階段會給予一些prompt,Gemini Pro 會根據這些提示對影像進行全面分析,並根據理解去產生一些有意義的問題。考慮到通用 MLLM 對文字元素的理解能力通常會比視覺模型弱,我們透過專門的 OCR 模型將提取的文字預處理到 prompt 中去。
Self-Answering: Gemini Pro對生成問題會利用思維鏈(CoT) 和少樣本提示(few-shot prompting) 等技術豐富上下文訊息,提高生成答案的可靠性。
Self-Reasoning: 這個階段會產生答案的詳細原因,迫使Gemini Pro 更多的思考問題和視覺元素之間的聯繫,從而減少幻覺並提高準確的答案。
資料過濾
儘管自我提問、回答和推理是有效的,但生成的圖像- 文本對可能面臨幻覺內容、無意義問題和錯誤答案。因此,我們設計了基於 LLM 的評估能力的過濾規則,以選擇高品質的 VQA 對。
Self-Evaluation 提示 Gemini Pro 和其他 MLLMs 判斷產生的問題是否有意義,以及答案是否足以正確解決問題。
Multi-Prompt Consistency 除了直接評估產生的內容外,研究者還在資料產生中手動增加提示和情境空間。當提供不同的提示時,一個正確且有意義的 VQA 對應該在語義上一致。
Multi-Context Consistency 研究者透過在問題前準備不同的情境資訊來進一步驗證 VQA 對。
TextSquare-8B
TextSquare-8B 借鏡了InternLM-Xcomposer2 的模型結構,包括CLIP ViT-L-14-336 的視覺Encoder,影像解析度進一步提升至700;基於InternLM2-7B-ChatSFT 的大語言模型LLM;一個對齊視覺和文字token 的橋接器projector。
TextSquare-8B 的訓練包括三階段的 SFT:
第一階段,以 490 的解析度全參數 (Vision Encoder, Projector, LLM) 微調模型。
第二階段,輸入解析度增加到 700,只訓練 Vision Encoder 以適應解析度變化。
第三階段,進一步以 700 的解析度進行全參數微調。
TextSquare 證實,在Square-10M 資料集的基礎上,具有8B 參數和正常大小影像解析度的模型可以在以文字為中心的VQA 上實現超過了大多數的MLLM,甚至是閉源模型(GPT4V、Gemini Pro) 的效果。
實驗結果
圖 4(a)顯示 TextSquare 有簡單的算術功能。圖 4(b)顯示了理解文字內容並在密集文本中提供大致位置的能力。圖 4(c)顯示了 TextSquare 對錶格結構的理解能力。

MLLM Benchmark
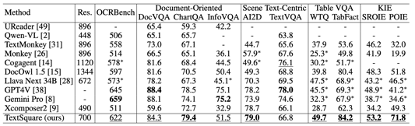
Document-Oriented Benchmark 在文件場景的VQA Benckmark (DocVQA、ChartQA、InfographicVQA) 上平均提升3.5%,優於所有開源模型,在ChartQA 資料集上略高於GPT4V 和Gemini Pro,模型解析度僅700,小於大多數面向文件的MLLM,如果解析度進一步提高,相信模型效能也將進一步提高,Monkey 已證明這一點。
Scene Text-centric Benchmark 自然場景的VQA Benchmark (TextVQA、AI2D) 中取得了SOTA 的效果,但與baseline Xcomposer2 相比沒有較大改進,可能是因為Xcomposer2 已經用了高品質的域內資料進行了充分優化。
Table VQA Benchmark 表格場景的VQA Benchmark (WTQ、TabFact) 中取得遠超GPT4V 及Gemini Pro 的效果,分別超過其他SOTA 模型3% 。
Text-centric KIE Benchmark 文本中心的关键信息提取 KIE 任务的 benchmark (SROIE、POIE),将 KIE 任务转换成 VQA 任务,在两个数据集都取得了最佳的性能,平均提升 14.8%。
OCRBench 包括文本识别、公式识别、文本中心 VQA、KIE 等 29 项 OCR 相关的评估任务,取得了开源模型的最佳性能,并成为第一个 10B 左右参数量达到 600 分的模型。
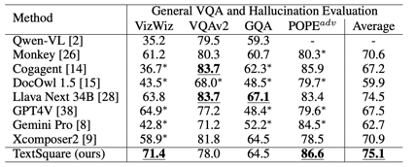
General VQA and Hallucination Evaluation Benchmark 在通用的 VQA Benchmark (VizWiz VQAv2、GQA、POPE) 上 TextSquare 相较于 Xconposer2 没有显著退化,仍然保持着最佳的性能,在 VisWiz 和 POPE 表现出显著的性能,比各最佳的方法高出 3.6%,这突出了该方法的有效性,能减轻模型幻觉。
消融实验

TextSquare 相较于 Xcomposer2 在各 benchmark 平均提升 7.7%。
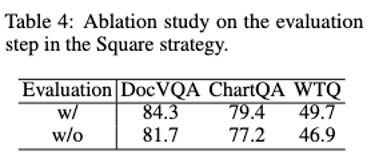
加入自评估后,模型性能有了明显提升。
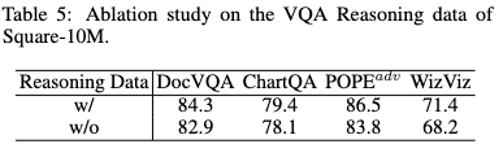
加入推理数据后有助于显著提升性能以及减轻幻觉生成。
数据规模和收敛 loss & 模型性能关系
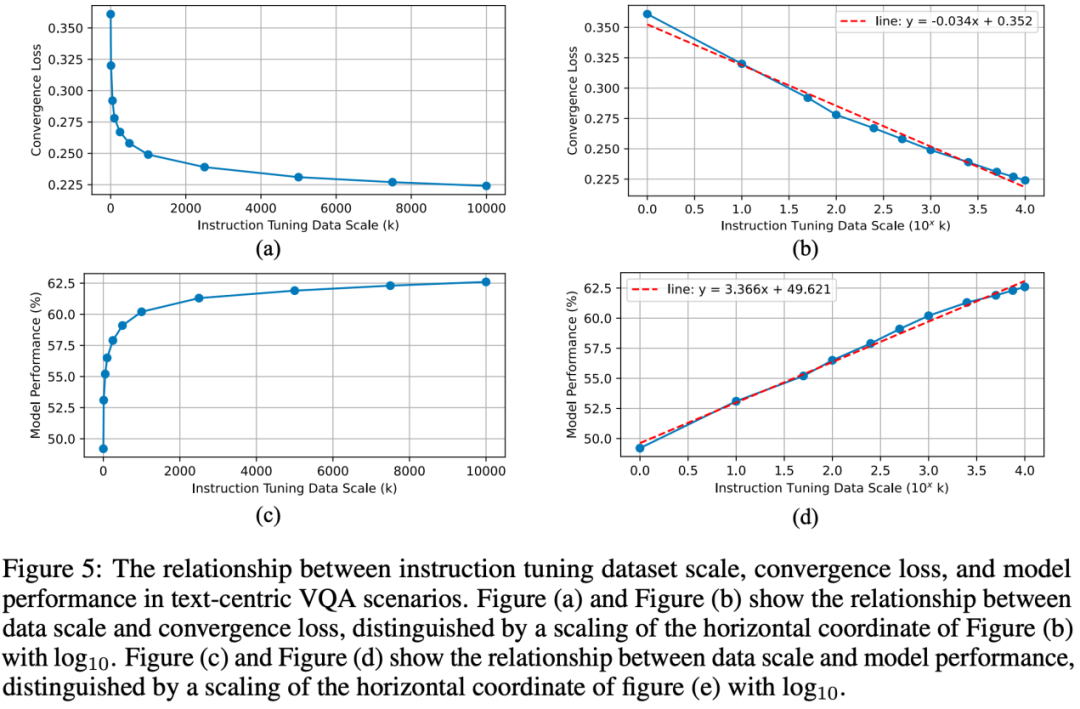
随着数据规模的增长,模型的 loss 继续减少,而下降速度逐渐变慢。收敛损失和指令调整数据尺度之间的关系近似符合对数函数。
随着指令调优数据的增长,模型的性能越来越好,但增长速度继续放缓,也大致符合对数函数。
总体而言,在以文本为中心的 VQA 场景中,在指令调整阶段存在相应的缩放定律,其中模型性能与数据缩放的对数成正比,可以指导潜在更大数据集的构建并预测模型性能。
总结
在本文中,研究者提出了构建高质量的以文本为中心的指令调优数据集(Square-10M)的 Square 策略,利用该数据集,TextSquare-8B 在多个 benchmark 上实现了与 GPT4V 相当的性能,并在各种基准测试上大幅优于最近发布的开源模型。
此外,研究者推导了指令调整数据集规模、收敛损失和模型性能之间的关系,以便为构建更大的数据集铺平道路,证实了数据的数量和质量对模型性能至关重要。
最后,研究者指出,如何进一步提高数据数量和质量以缩小开源模型与领先模型之间的差距,被认为一个有高度希望的研究方向。
以上是8B文字多模態大模型指標逼近GPT4V,位元組、華師、華科聯合提出TextSquare的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 laravel入門實例
Apr 18, 2025 pm 12:45 PM
laravel入門實例
Apr 18, 2025 pm 12:45 PM
Laravel 是一款 PHP 框架,用於輕鬆構建 Web 應用程序。它提供一系列強大的功能,包括:安裝: 使用 Composer 全局安裝 Laravel CLI,並在項目目錄中創建應用程序。路由: 在 routes/web.php 中定義 URL 和處理函數之間的關係。視圖: 在 resources/views 中創建視圖以呈現應用程序的界面。數據庫集成: 提供與 MySQL 等數據庫的開箱即用集成,並使用遷移來創建和修改表。模型和控制器: 模型表示數據庫實體,控制器處理 HTTP 請求。
 使用 Composer 解決推薦系統的困境:andres-montanez/recommendations-bundle 的實踐
Apr 18, 2025 am 11:48 AM
使用 Composer 解決推薦系統的困境:andres-montanez/recommendations-bundle 的實踐
Apr 18, 2025 am 11:48 AM
在開發一個電商網站時,我遇到了一個棘手的問題:如何為用戶提供個性化的商品推薦。最初,我嘗試了一些簡單的推薦算法,但效果並不理想,用戶的滿意度也因此受到影響。為了提升推薦系統的精度和效率,我決定採用更專業的解決方案。最終,我通過Composer安裝了andres-montanez/recommendations-bundle,這不僅解決了我的問題,還大大提升了推薦系統的性能。可以通過一下地址學習composer:學習地址
 解決 Craft CMS 中的緩存問題:使用 wiejeben/craft-laravel-mix 插件
Apr 18, 2025 am 09:24 AM
解決 Craft CMS 中的緩存問題:使用 wiejeben/craft-laravel-mix 插件
Apr 18, 2025 am 09:24 AM
在使用CraftCMS開發網站時,常常會遇到資源文件緩存的問題,特別是當你頻繁更新CSS和JavaScript文件時,舊版本的文件可能仍然被瀏覽器緩存,導致用戶無法及時看到最新的更改。這個問題不僅影響用戶體驗,還會增加開發和調試的難度。最近,我在項目中遇到了類似的困擾,經過一番探索,我找到了wiejeben/craft-laravel-mix這個插件,它完美地解決了我的緩存問題。
 laravel框架安裝方法
Apr 18, 2025 pm 12:54 PM
laravel框架安裝方法
Apr 18, 2025 pm 12:54 PM
文章摘要:本文提供了詳細分步說明,指導讀者如何輕鬆安裝 Laravel 框架。 Laravel 是一個功能強大的 PHP 框架,它 упростил 和加快了 web 應用程序的開發過程。本教程涵蓋了從系統要求到配置數據庫和設置路由等各個方面的安裝過程。通過遵循這些步驟,讀者可以快速高效地為他們的 Laravel 項目打下堅實的基礎。
 如何使用 Composer 簡化郵件營銷:DUWA.io 的應用實踐
Apr 18, 2025 am 11:27 AM
如何使用 Composer 簡化郵件營銷:DUWA.io 的應用實踐
Apr 18, 2025 am 11:27 AM
在進行郵件營銷活動時,我遇到了一個棘手的問題:如何高效地創建並發送HTML格式的郵件。傳統的方法是手動編寫代碼並使用SMTP服務器發送郵件,但這不僅耗時,而且容易出錯。在嘗試了多種解決方案後,我發現了DUWA.io,這是一個簡單易用的RESTAPI,能夠幫助我快速創建和發送HTML郵件。為了進一步簡化開發流程,我決定使用Composer來安裝和管理DUWA.io的PHP庫——captaindoe/duwa。
 使用DICR/YII2-Google將Google API集成在YII2中
Apr 18, 2025 am 11:54 AM
使用DICR/YII2-Google將Google API集成在YII2中
Apr 18, 2025 am 11:54 AM
vProcesserazrabotkiveb被固定,мнелостольностьстьс粹餾標д都LeavallySumballanceFriablanceFaumDoptoMatification,Čtookazalovnetakprosto,kakaožidal.posenesko
 laravel怎麼查看版本號 laravel查看版本號方法
Apr 18, 2025 pm 01:00 PM
laravel怎麼查看版本號 laravel查看版本號方法
Apr 18, 2025 pm 01:00 PM
Laravel框架內置了多種方法來方便地查看其版本號,滿足開發者的不同需求。本文將探討這些方法,包括使用Composer命令行工具、訪問.env文件或通過PHP代碼獲取版本信息。這些方法對於維護和管理Laravel應用程序的版本控制至關重要。
 如何使用 Composer 提升 Laravel 應用的安全性:wiebenieuwenhuis/laravel-2fa 庫的應用
Apr 18, 2025 am 11:36 AM
如何使用 Composer 提升 Laravel 應用的安全性:wiebenieuwenhuis/laravel-2fa 庫的應用
Apr 18, 2025 am 11:36 AM
在開發一個Laravel應用時,我遇到了一個常見但棘手的問題:如何提升用戶賬戶的安全性。隨著網絡攻擊的日益複雜,單一的密碼保護已經不足以保障用戶的數據安全。我嘗試了幾種方法,但效果都不盡如人意。最終,我通過Composer安裝了wiebenieuwenhuis/laravel-2fa庫,成功地為我的應用添加了雙因素認證(2FA),大大提升了安全性。
