

顏水成掛帥,奠定「通用視覺多模態大模型」終極型態!一統理解/生成/分割/編輯


#https://www.php.cn/link/d8a3b2dde3181c8257e2e45efbd1e8ae
論文連結:
論文連結:
# https://www.php.cn/link/0ec5ba872f1179835987f9028c4cc4df
開源程式碼:##https:// www.php.cn/link/26d6e896db39edc7d7bdd357d6984c95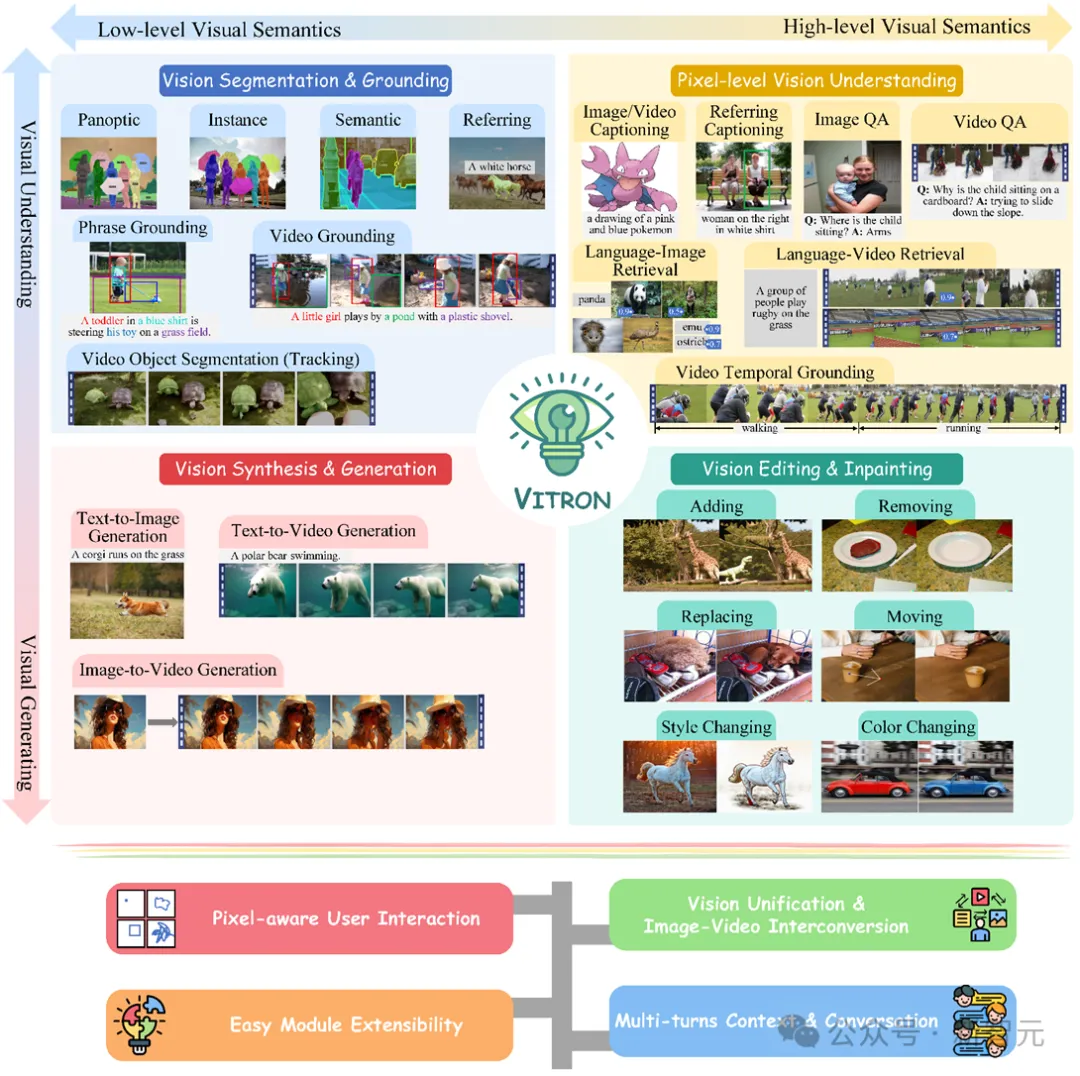
###############################1 ####這是一個重磅的通用視覺多模態大模型,支持從視覺理解到視覺生成、從低層次到高層次的一系列視覺任務,解決了困擾大語言模型產業已久的圖像/視訊模型割裂問題,提供了一個全面統一靜態影像與動態視訊內容的理解、生成、分割、編輯等任務的像素級通用視覺多模態大模型,為下一代通用視覺大模型的終極形態奠定了基礎,也標誌著大模型邁向通用人工智慧(AGI)的又一大步。 ########################Vitron作為一個統一的像素級視覺多模態大語言模型,實現了從低層次到高層次的視覺任務的全面支持,能夠處理複雜的視覺任務,並理解和生成圖像和視頻內容,提供了強大的視覺理解和任務執行能力。同時,Vitron支援與使用者的連續操作,實現了靈活的人機互動,展示了通往更統一的視覺多模態通用模型的巨大潛力。 ########################Vitron相關的論文、程式碼和Demo已全部公開,其在綜合性、技術創新、人機互動和應用潛力等方面展現出的獨特優勢和潛力,不僅推動了多模態大模型的發展,也為未來的視覺大模型研究提供了一個新的方向。 ######目前視覺大語言模型(LLMs)的發展取得了喜人進展。社群越來越相信,建構更通用、更強大的多模態大模型(MLLMs)將會是通往通用人工智慧(AGI)的必經之路。但在向多模態通用大模型(Generalist)的邁進過程中,目前仍存在一些關鍵挑戰。例如很大一部分工作都沒有實現細粒度像素層級的視覺理解,或是缺乏對影像和視訊的統一支援。抑或對於各種視覺任務的支持不充分,離通用大模型相差甚遠。 ######為了填補這個空白,近日,團隊聯合發布開源了Vitron通用像素級視覺多模態大語言模型。 Vitron支援從視覺理解到視覺生成、從低層次到高層次的一系列視覺任務,包括靜態影像和動態影片內容進行全面的理解、生成、分割和編輯等任務。 ###############上圖綜合描繪了Vitron在四大視覺相關任務的功能支持,以及其關鍵優勢。 Vitron也支援與使用者的連續操作,實現靈活的人機互動。該計畫展示了面向更統一的視覺多模態通用模型的巨大潛力,為下一代通用視覺大模型的終極形態奠定了基礎。 ######Vitron相關論文、程式碼、Demo目前已全部公開。 ########################################################### ########################################################### ############################################
大一統的終極多模態大語言模型
近年來,大語言模型(LLMs)展現出了前所未有的強大能力,其被逐漸驗證為乃是通往AGI的技術路線。而多模態大語言模型(MLLMs)在多個社區火熱發展且迅速出圈,透過引入能進行視覺感知的模組,擴展純語言基礎LLMs至MLLMs,眾多在圖像理解方面強大卓越的MLLMs被研發問世,例如BLIP-2、LLaVA、MiniGPT-4等等。同時,專注於視訊理解的MLLMs也陸續面世,如VideoChat、Video-LLaMA和Video-LLaVA等等。
隨後,研究人員主要從兩個維度試圖進一步擴展MLLMs的能力。一方面,研究人員嘗試深化MLLMs對視覺的理解,從粗略的實例級理解過渡到對圖像的像素級細粒度理解,從而實現視覺區域定位(Regional Grounding)能力,如GLaMM、PixelLM、NExT-Chat和MiniGPT-v2等。
另一方面,研究人員嘗試擴充MLLMs可以支援的視覺功能。部分研究已經開始研究讓MLLMs不僅理解輸入視覺訊號,還能支援生成輸出視覺內容。例如,GILL、Emu等MLLMs能夠靈活產生影像內容,以及GPT4Video和NExT-GPT實現視訊生成。
目前人工智慧社群已逐漸達成一致,認為視覺MLLMs的未來趨勢必然會朝著高度統一、能力更強的方向發展。然而,儘管社區開發了眾多的MLLMs,但仍然存在明顯的鴻溝。
1. 幾乎所有現有的視覺LLMs將圖像和視訊視為不同的實體,要么僅支援圖像,要么僅支援視訊。
研究人員主張,視覺應該同時包含了靜態影像和動態影片兩個面向的內涵──這兩者都是視覺世界的核心組成,在大多數場景中甚至可以互換。所以,需要建構一個統一的MLLM框架能夠同時支援影像和視訊模態。
2. 目前MLLMs對視覺功能的支援還有所不足。
大多數模型只能被理解,或最多產生圖像或影片。研究人員認為,未來的MLLMs應該是一個通用大語言模型,能涵蓋更廣泛的視覺任務和操作範圍,實現對所有視覺相關任務的統一支持,達到「one for all」的能力。這一點對實際應用尤其是在經常涉及一系列迭代和互動操作的視覺創作中至關重要。
例如,使用者通常首先從文字開始,透過文生圖,將一個想法轉化為視覺內容;然後透過進一步的細粒度圖像編輯來完善初始想法,添加更多細節;接著,透過圖像生成影片來創建動態內容;最後,進行幾輪迭代交互,如影片編輯,完善創作。
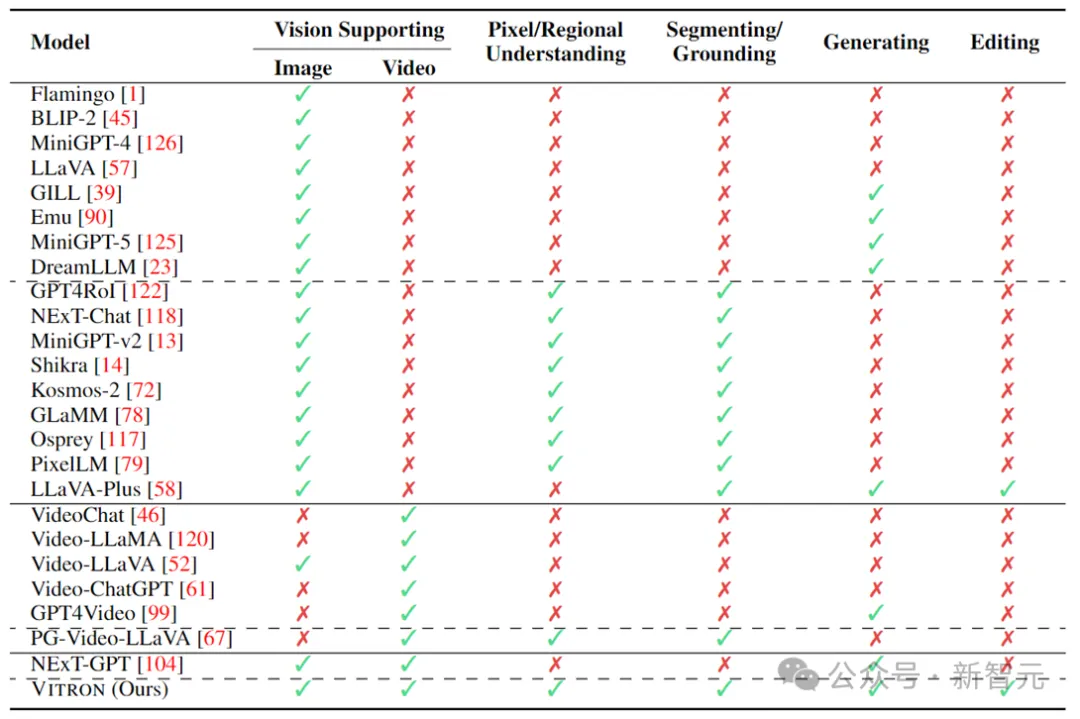
上表簡單地歸納了現有的視覺MLLM的能力(只代表性地囊括了部分模型,覆蓋不完整)。為了彌補這些差距,該團隊提出一種通用的像素級視覺MLLM—Vitron。
Vitron系統架構:三大關鍵模組
Vitron整體框架如下圖所示。 Vitron採用了與現有相關MLLMs相似的架構,包括三個關鍵部分:1) 前端視覺&語言編碼模組,2) 中心LLM理解和文本生成模組,以及3) 後端用戶響應和模組調用以進行視覺操控模組。
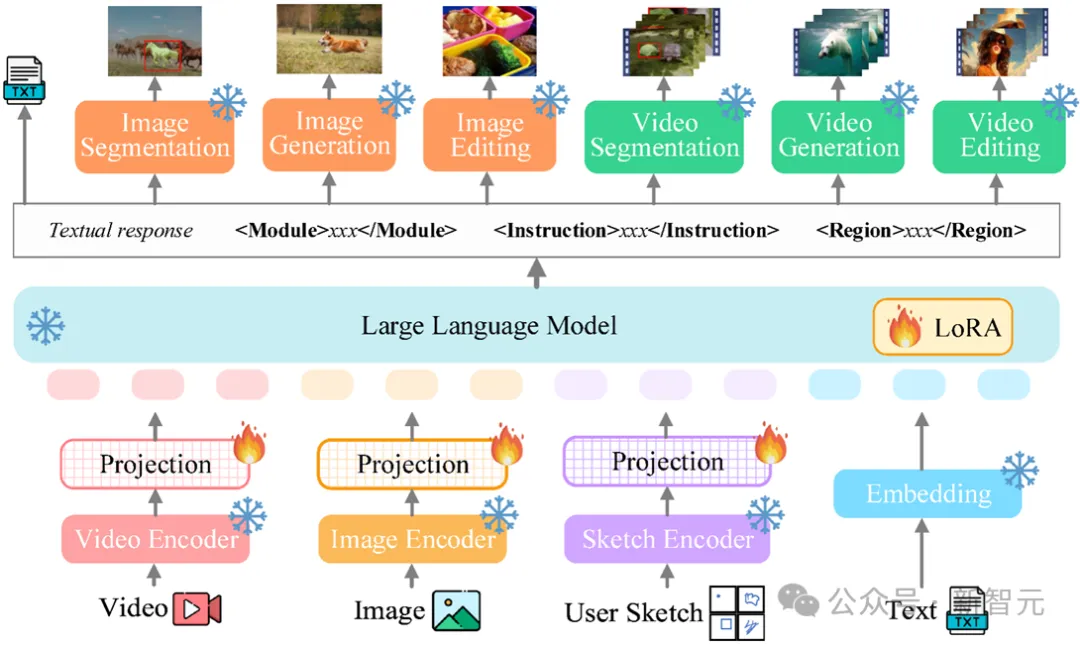
#前端模組:#視覺-語言編碼
#為了感知影像和視訊模態訊號,並支援細粒度使用者視覺輸入,Vitron整合了影像編碼器、視訊編碼器、區域框架/草圖編碼器。
中心模組:核心LLM
Vitron使用的是Vicuna(7B,v1 .5),來實現理解、推理、決策和多輪用戶互動。
後端模組:使用者回應與模組呼叫
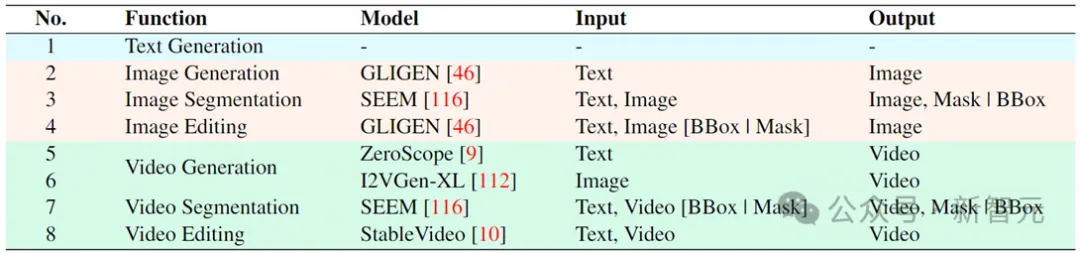
Vitron模型訓練三大階段
基於上述架構,再對Vitron進行訓練微調,以賦予其強大的視覺理解和任務執行能力。模型訓練主要囊括三個不同的階段。
步驟一:視覺-語言整體對齊學習。將輸入的視覺語言特徵映射到一個統一的特徵空間中,從而使其能夠有效理解輸入的多模態訊號。這是一種粗粒度的視覺-語言對齊學習,可以讓系統具有整體上有效處理傳入的視覺訊號。研究人員採用了現存的圖像-標題對(CC3M)、視訊-標題對(Webvid)和區域-標題對(RefCOCO)的資料集進行訓練。
步驟二:細粒度的時空視覺定位指令微調。系統採用了呼叫外部模組方式來執行各種像素級視覺任務,但LLM本身並未經過任何細粒度的視覺訓練,這將會阻礙了系統實現真正的像素級視覺理解。為此,研究人員提出了一種細粒度的時空視覺定位指令微調訓練,核心思想是使LLM能夠定位影像的細粒度空間性和視訊的具體時序特性。
步驟三:輸出端面向指令呼叫的指令微調。上述第二階段的訓練賦予了LLM和前端編碼器在像素層級理解視覺的能力。這最後一步,以指令呼叫為導向的指令微調,旨在讓系統具備精確執行指令的能力,讓LLM產生適當且正確的呼叫文字。由於不同的終端視覺任務可能需要不同的呼叫命令,為了統一這一點,研究人員提出將LLM的回應輸出標準化為結構化文字格式,其中包括:
1)使用者回應輸出,直接回覆使用者的輸入
2)模組名稱,指示將要執行的功能或任務。
3)呼叫指令,觸發任務模組的元指令。
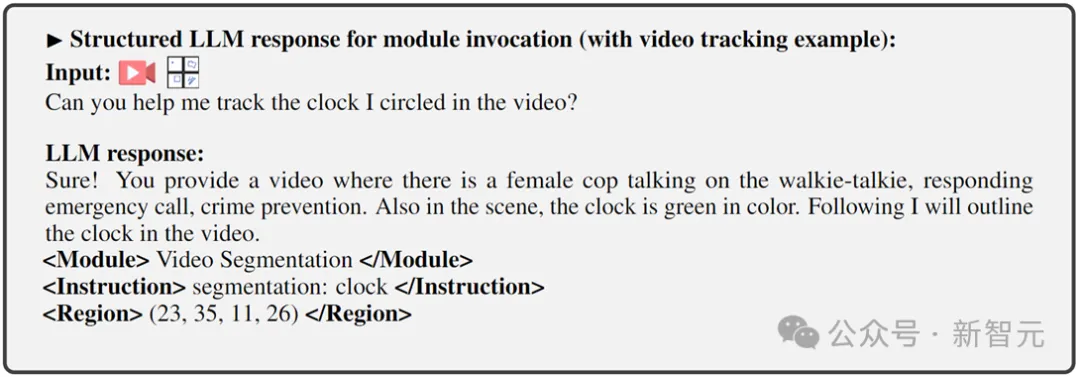
4)區域(可選輸出),指定某些任務所需的細粒度視覺特徵,例如在視訊追蹤或視覺編輯中,後端模組需要這些資訊。對於區域,基於LLM的像素級理解,將輸出由座標描述的邊界框。
評估實驗
研究人員基於Vitron在22個常見的基準資料集、12個影像/影片視覺任務上進行了廣泛的實驗評估。 Vitron展現出在四大主要視覺任務群組(分割、理解、內容生成和編輯)中的強大能力,同時其具備靈活的人機互動能力。以下代表性地展示了一些定性比較結果:
Vision Segmentation
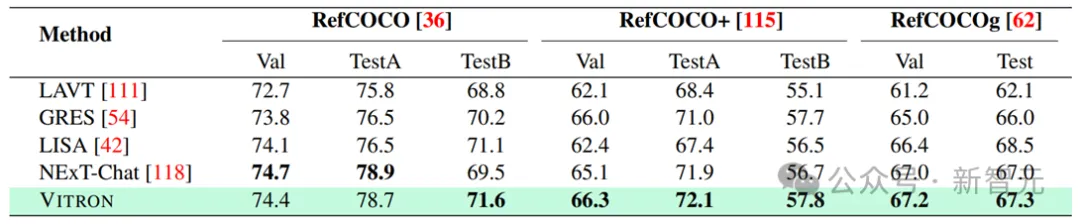
Results of image referring image segmentation
#Fine-grained Vision Understanding

#Results of image referring expression comprehension.
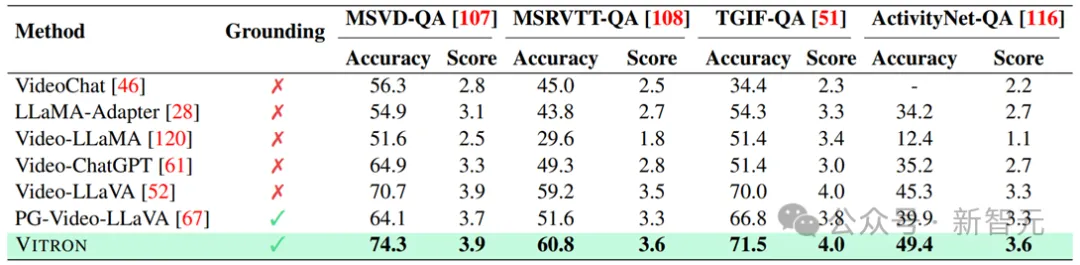
#Results on video QA.
Vision Generation
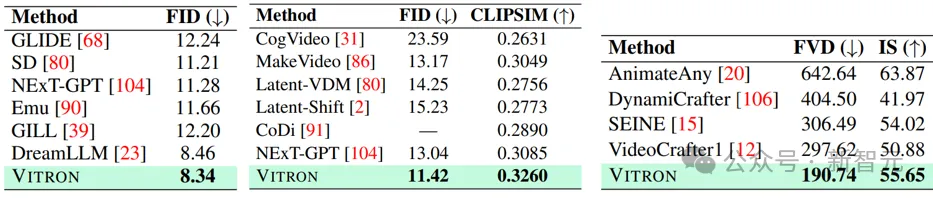
Text-to-Image Generation/Text-to-Video generation/Image-to-Video generation
Vision Editing
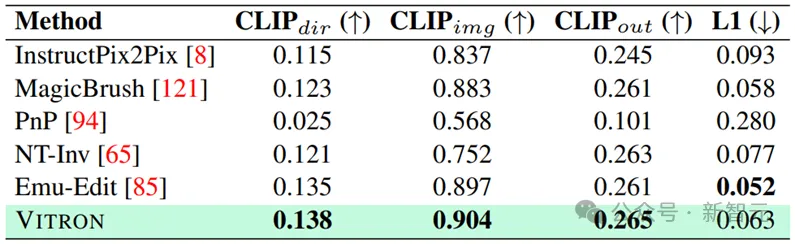
#Image editing results
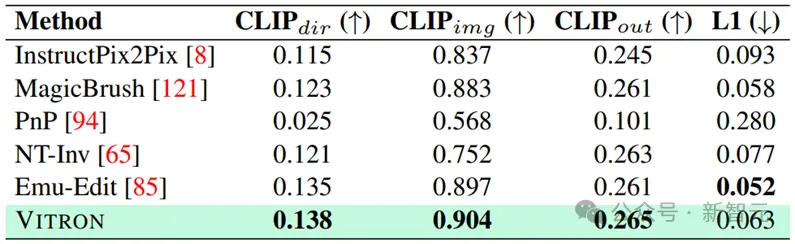
#具體更多詳細實驗內容和細節請移步論文。
未來方向展望
總體上,這項工作展示了研發大一統的視覺多模態通用大模型的巨大潛力,為下一代視覺大模型的研究奠定了一個新的形態,踏出了這個方向的第一步。儘管團隊所提出的Vitron系統表現出強大的通用能力,但仍存在自身的限制。以下研究人員列出一些未來可進一步探索的方向。
系統架構
#Vitron系統仍採用半聯合、半代理的方式來呼叫外部工具。雖然這種基於呼叫的方法便於擴展和替換潛在模組,但這也意味著這種管線結構的後端模組不參與到前端與LLM核心模組的聯合學習。
此限制不利於系統的整體學習,這意味著不同視覺任務的效能上限將受到後端模組的限制。未來的工作應將各種視覺任務模組整合成一個統一的單元。實現對影像和視訊的統一理解和輸出,同時透過單一生成範式支援生成和編輯能力,仍然是一個挑戰。目前一個有希望的方式是結合modality-persistent的tokenization, 提升系統在不同輸入和輸出以及各種任務上的統一化。
使用者互動性
#與先前專注於單一視覺任務的模型(例如,Stable Diffusion和SEEM)不同,Vitron旨在促進LLM和用戶之間的深度交互,類似於行業內的OpenAI的DALL-E系列,Midjourney等。實現最佳的使用者互動性是本項工作的核心目標之一。
Vitron利用現有的基於語言的LLM,結合適當的指令調整,以實現一定程度的互動。例如,系統可以靈活地回應使用者輸入的任何預期訊息,產生相應的視覺操作結果,而不要求使用者輸入精確匹配後端模組條件。然而,該工作在增強互動性方面仍有很大的提升空間。例如,從閉源的Midjourney系統汲取靈感,不論LLM在每一步做出何種決定,系統都應積極向用戶提供回饋,以確保其行動和決策與用戶意圖一致。
模態能力
#目前,Vitron整合了一個7B的Vicuna模型,其可能對其理解語言、圖像和視訊的能力會產生某些限制。未來的探索方向可以發展一個全面的端到端系統,例如擴大模型的規模,以實現對視覺的更徹底和全面的理解。此外,應該努力使LLM能夠完全統一影像和視訊模態的理解。
以上是顏水成掛帥,奠定「通用視覺多模態大模型」終極型態!一統理解/生成/分割/編輯的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 git怎麼更新代碼
Apr 17, 2025 pm 04:45 PM
git怎麼更新代碼
Apr 17, 2025 pm 04:45 PM
更新 git 代碼的步驟:檢出代碼:git clone https://github.com/username/repo.git獲取最新更改:git fetch合併更改:git merge origin/master推送更改(可選):git push origin master
 git怎麼下載項目到本地
Apr 17, 2025 pm 04:36 PM
git怎麼下載項目到本地
Apr 17, 2025 pm 04:36 PM
要通過 Git 下載項目到本地,請按以下步驟操作:安裝 Git。導航到項目目錄。使用以下命令克隆遠程存儲庫:git clone https://github.com/username/repository-name.git
 git怎麼合併代碼
Apr 17, 2025 pm 04:39 PM
git怎麼合併代碼
Apr 17, 2025 pm 04:39 PM
Git 代碼合併過程:拉取最新更改以避免衝突。切換到要合併的分支。發起合併,指定要合併的分支。解決合併衝突(如有)。暫存和提交合併,提供提交消息。
 git下載不動怎麼辦
Apr 17, 2025 pm 04:54 PM
git下載不動怎麼辦
Apr 17, 2025 pm 04:54 PM
解決 Git 下載速度慢時可採取以下步驟:檢查網絡連接,嘗試切換連接方式。優化 Git 配置:增加 POST 緩衝區大小(git config --global http.postBuffer 524288000)、降低低速限制(git config --global http.lowSpeedLimit 1000)。使用 Git 代理(如 git-proxy 或 git-lfs-proxy)。嘗試使用不同的 Git 客戶端(如 Sourcetree 或 Github Desktop)。檢查防火
 git commit怎麼用
Apr 17, 2025 pm 03:57 PM
git commit怎麼用
Apr 17, 2025 pm 03:57 PM
Git Commit 是一種命令,將文件變更記錄到 Git 存儲庫中,以保存項目當前狀態的快照。使用方法如下:添加變更到暫存區域編寫簡潔且信息豐富的提交消息保存並退出提交消息以完成提交可選:為提交添加簽名使用 git log 查看提交內容
 如何解決PHP項目中的高效搜索問題? Typesense助你實現!
Apr 17, 2025 pm 08:15 PM
如何解決PHP項目中的高效搜索問題? Typesense助你實現!
Apr 17, 2025 pm 08:15 PM
在開發一個電商網站時,我遇到了一個棘手的問題:如何在大量商品數據中實現高效的搜索功能?傳統的數據庫搜索效率低下,用戶體驗不佳。經過一番研究,我發現了Typesense這個搜索引擎,並通過其官方PHP客戶端typesense/typesense-php解決了這個問題,大大提升了搜索性能。
 git怎麼更新本地代碼
Apr 17, 2025 pm 04:48 PM
git怎麼更新本地代碼
Apr 17, 2025 pm 04:48 PM
如何更新本地 Git 代碼?用 git fetch 從遠程倉庫拉取最新更改。用 git merge origin/<遠程分支名稱> 將遠程變更合併到本地分支。解決因合併產生的衝突。用 git commit -m "Merge branch <遠程分支名稱>" 提交合併更改,應用更新。
 git怎麼刪除倉庫
Apr 17, 2025 pm 04:03 PM
git怎麼刪除倉庫
Apr 17, 2025 pm 04:03 PM
要刪除 Git 倉庫,請執行以下步驟:確認要刪除的倉庫。本地刪除倉庫:使用 rm -rf 命令刪除其文件夾。遠程刪除倉庫:導航到倉庫設置,找到“刪除倉庫”選項,確認操作。
