
人類獲取的信息83%來自視覺,圖文多模態大模型能感知更豐富和精確的真實世界信息,構建更全面的認知智能,從而向AGI(通用人工智能)邁出更大步伐。
元象今日發布多模態大模型 XVERSE-V,支援任意寬高比影像輸入,在主流評測中效果領先。 此模式全開源,無條件免費商用 ,持續推動大量中小企業、研究者和開發者的研發和應用創新。  XVERSE-V表現優異,在多項權威多模態評測中超過零一萬物Yi-VL-34B、面壁智能OmniLMM-12B及深度求索DeepSeek-VL-7B等開源模型,在綜合能力測評MMBench中超過了GoogleGeminiProVision、阿里Qwen-VL-Plus和Claude-3V Sonnet等知名封閉源模型。
XVERSE-V表現優異,在多項權威多模態評測中超過零一萬物Yi-VL-34B、面壁智能OmniLMM-12B及深度求索DeepSeek-VL-7B等開源模型,在綜合能力測評MMBench中超過了GoogleGeminiProVision、阿里Qwen-VL-Plus和Claude-3V Sonnet等知名封閉源模型。 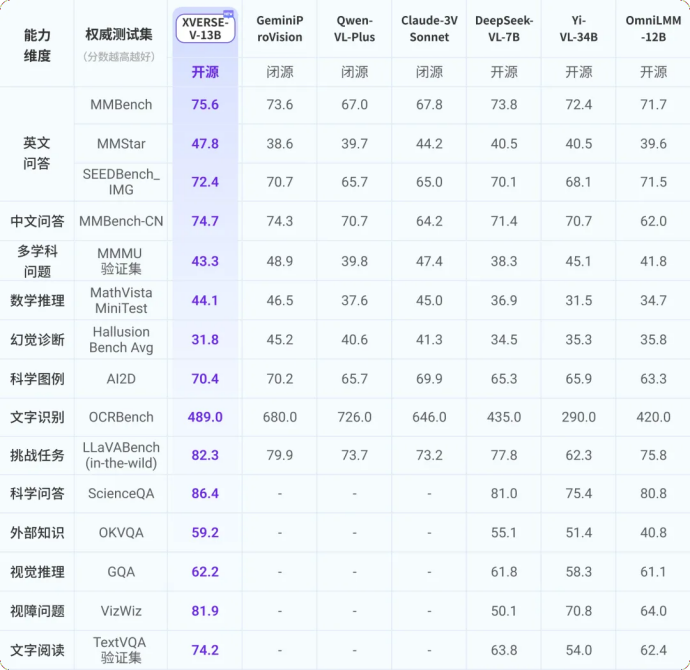 圖. 多模態大模型綜合評測
圖. 多模態大模型綜合評測
融合整體和局部的高清影像表示
傳統的多模態模型的影像表示只有整體, XVERSE-V 創新地採用了融合整體和局部的策略,支援輸入任意寬高比的影像。兼顧全局的概覽資訊和局部的細節訊息,能夠識別和分析圖像中的細微特徵,看的更清楚,理解的更準確。 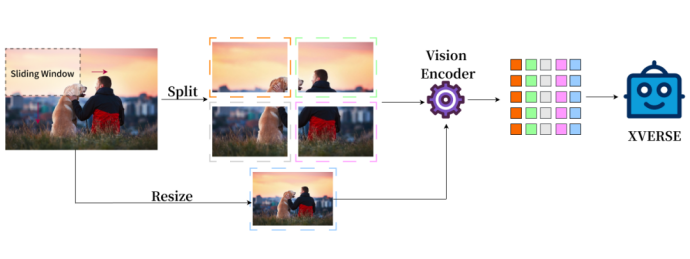
 注意:Concate* 表示依列進行拼接+
注意:Concate* 表示依列進行拼接+


#免費下載大模型##•Hugging Face:https ://huggingface.co/xverse/XVERSE-V-13B
•ModelScope魔搭:https://modelscope.cn/models/xverse/XVERSE-V-13B
•Github :https://github.com/xverse-ai/XVERSE-V-13B
•詢問發送:opensource@xverse.cn
元象持續打造國內開源標桿,在
國內最早開源最大參數65B、 全球最早開源最長上下文256K 以及國際前線的MoE模式 ,並在SuperCLUE評估全國領先 。此次推出MoE模型, 填補 國產開源空白,更將其 推向了國際領先水 平。 商業應用上,元像大模型是
廣東最早獲得國家備案的模式之一,可提供全社會服務。元像大模型去年起已及多個騰訊產品,包括QQ音樂 、虎牙直播、全民K歌、騰訊雲等,進行深度合作與應用探索,為文化、娛樂、旅遊、金融領域打造創新領先的使用者體驗。 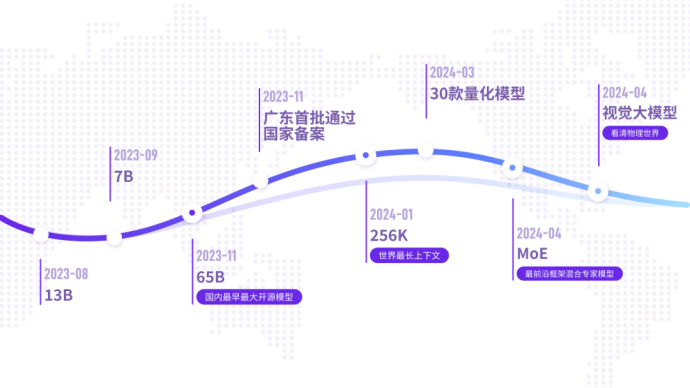
模型不僅在基礎能力上表現出色,在實際的應用場景中也有著出色的表現。具備不同場景下的理解能力,能夠處理資訊圖表、文獻、現實場景、數理題目、科學文獻、程式碼轉換等不同需求。
•
圖表理解不論是複雜圖文結合的資訊圖理解,還是單一圖表的分析與計算,模型都能夠自如應對。 •視障真實場景 在真實視障場景測試集VizWiz中,XVERSE-V表現出色,超過了InternVL-Chat -V1.5、DeepSeek-VL-7B 等幾乎所有主流的開源多模態大模型。測試集包含了來自真實視障用戶提出的超過31,000個視覺問答,能準確反映用戶的真實需求與瑣碎細小的問題,幫助視障人群克服他們日常真實的視覺挑戰。 VizWiz測驗範例 •看圖內容創作##10#XVER • 112#XVER#V2#XVER#V2#XVER#V2#XVER#V>2#XVER#V>2#XVER#V0.同時保持強大的文字生成能力,能夠很好地勝任理解圖像後創意文字生成的任務。 教育解題 模型具備了廣泛的知識儲備和邏輯推理能力,能夠辨識圖像解答不同學科的問題。 百科全書解決 模型儲備了歷史、文化、科技、安全等各類主題的知識。 #•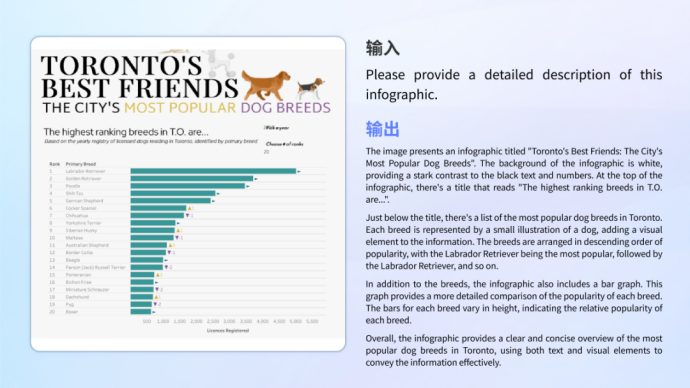
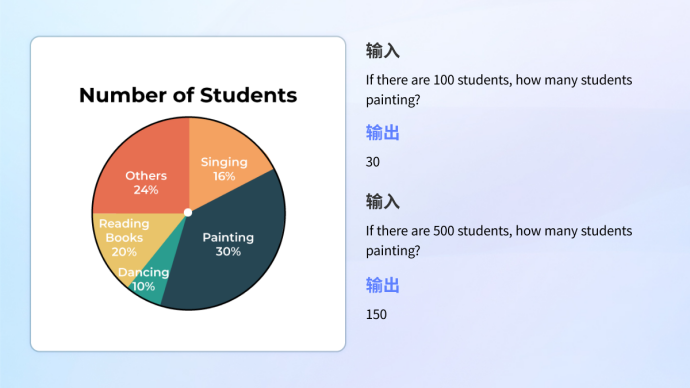

 看圖內容創作
看圖內容創作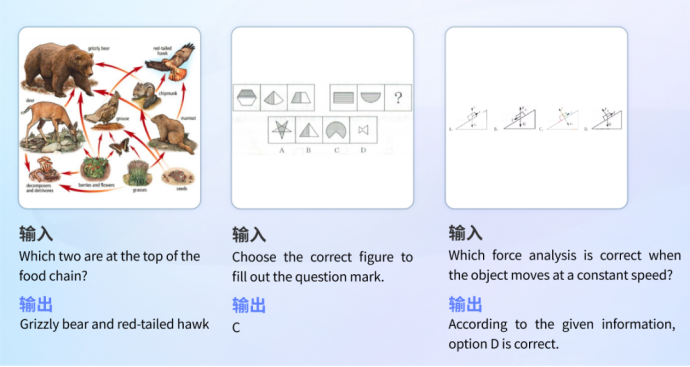

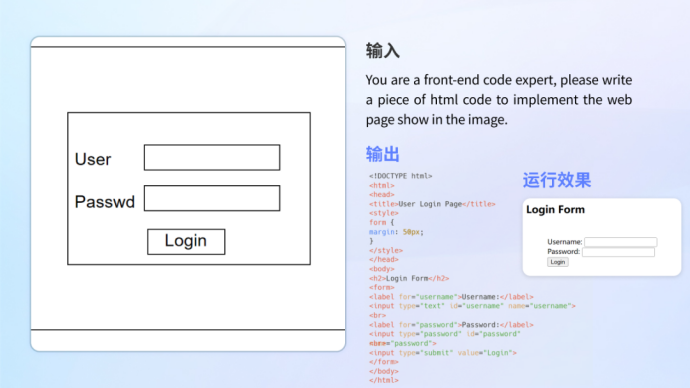 •
• •
•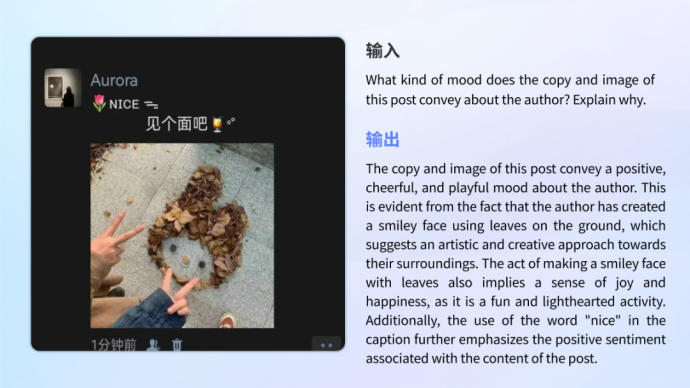 #情感理解與識別
#情感理解與識別
以上是元象首個多模態大模型XVERSE-V開源,刷新權威大模型榜單,支援任意寬高比輸入的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















