

單卡跑Llama 70B快過雙卡,微軟硬生把FP6搞到A100哩 | 開源

FP8和更低的浮點數量化精度,不再是H100的「專利」了!
老黃想讓大家用INT8/INT4,微軟DeepSpeed團隊在沒有英偉達官方支援的條件下,硬生生在A100上跑起FP6#。
測試結果表明,新方法TC-FPx在A100上的FP6量化,速度接近甚至偶爾超過INT4,而且擁有比後者更高的精度。
在此基礎之上,還有端到端的大模型支援#,目前已經開源並整合到了DeepSpeed等深度學習推理框架中。
這成果對大模型的加速效果也是立竿見影-在這種框架下用單卡跑Llama,吞吐量比雙倍還要高2.65倍。
一名機器學習研究人員看了後表示,微軟的這項研究簡直可以用crazy來形容。
表情包也第一時間上線,be like:
英偉達:只有H100支援FP8。
微軟:Fine,我自己搞定。

那麼,這個框架到底能實現什麼樣的效果,背後又採用了什麼樣的技術呢?
用FP6跑Llama,單卡比雙卡還快
在A100上使用FP6精度,帶來的是核心級的效能提升#。
研究人員選取了不同大小的Llama模型和OPT模型之中的線性層,在NVIDIA A100-40GB GPU平台上,使用CUDA 11.8進行了測試。
結果比英威達官方的cuBLAS(W16A16)與TensorRT-LLM(W8A16),TC-FPx(W6A16)速度提升的最大值分別是2.6倍和1.9倍。
比起於4bit的BitsandBytes(W4A16)方法,TC-FPx的最大速度提升則是達到了8.9倍。
(W和A分別代表權重量化位寬和激活量化位寬)
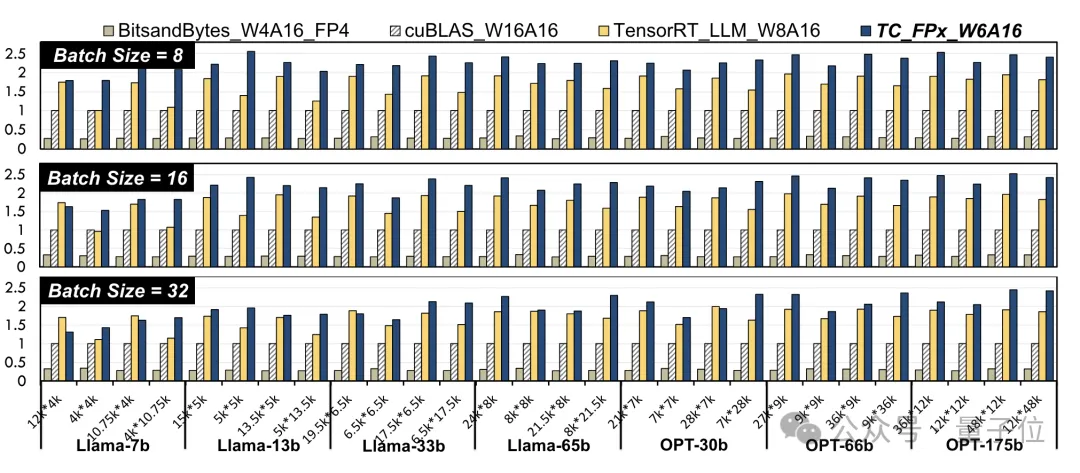
#△歸一化數據,以cuBLAS結果為1
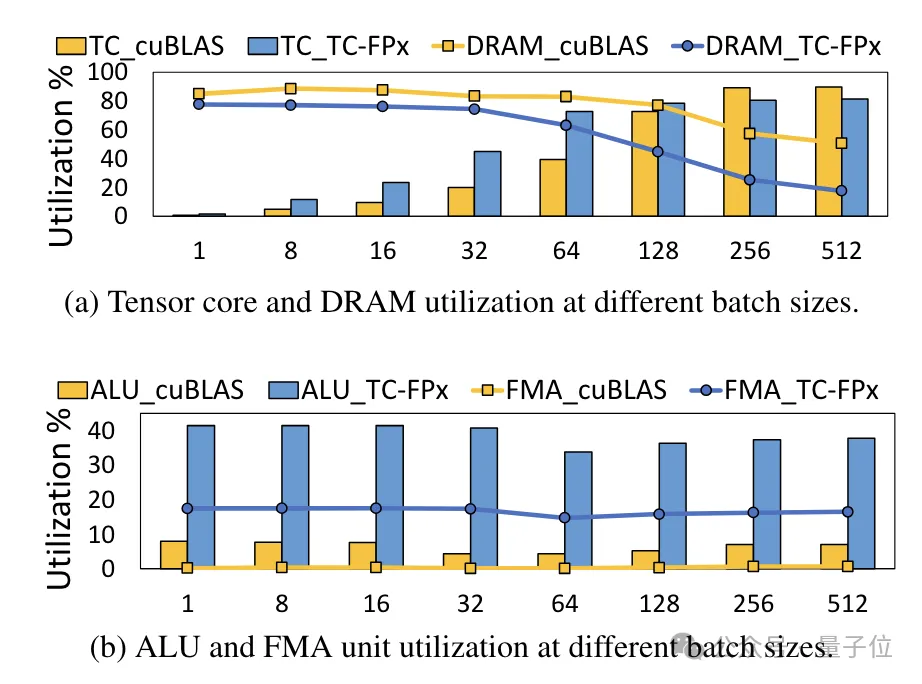
同時,TC-FPx核心也減少了對DRAM記憶體的訪問,並提高了DRAM頻寬利用率和Tensor Cores利用率,以及ALU和FMA單元的利用率。
在TC-FPx基礎之上設計的端對端推理框架FP6-LLM,也給大模型帶來了顯著的性能提高。
以Llama-70B為例,用FP6-LLM在單卡上的運行吞吐量,比FP16在雙卡上還要高出2.65倍,在16以下的批大小中的延遲也低於FP16。
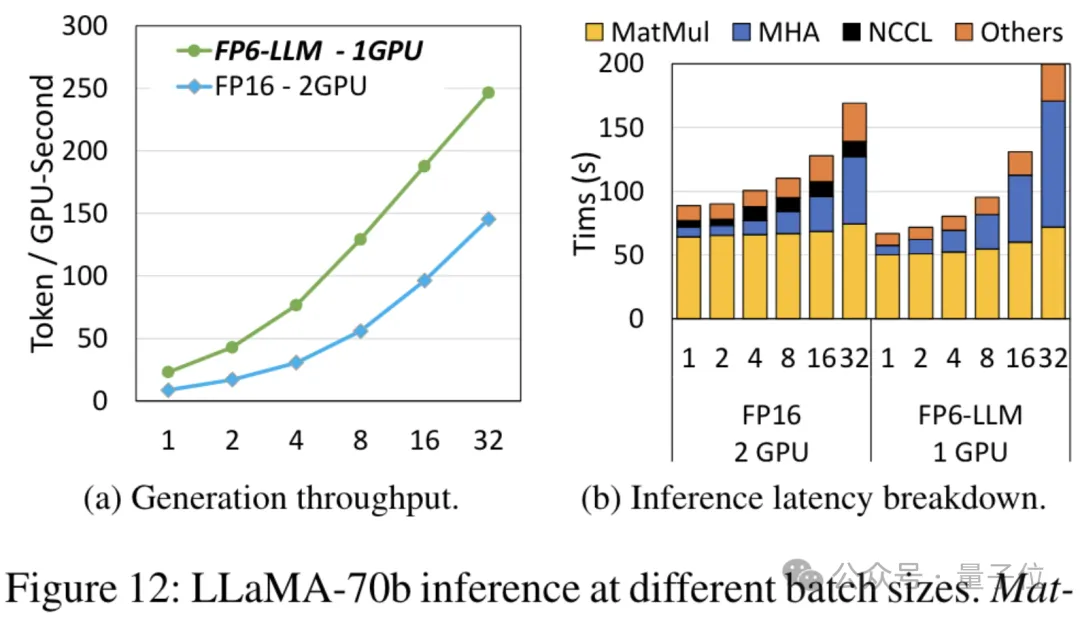
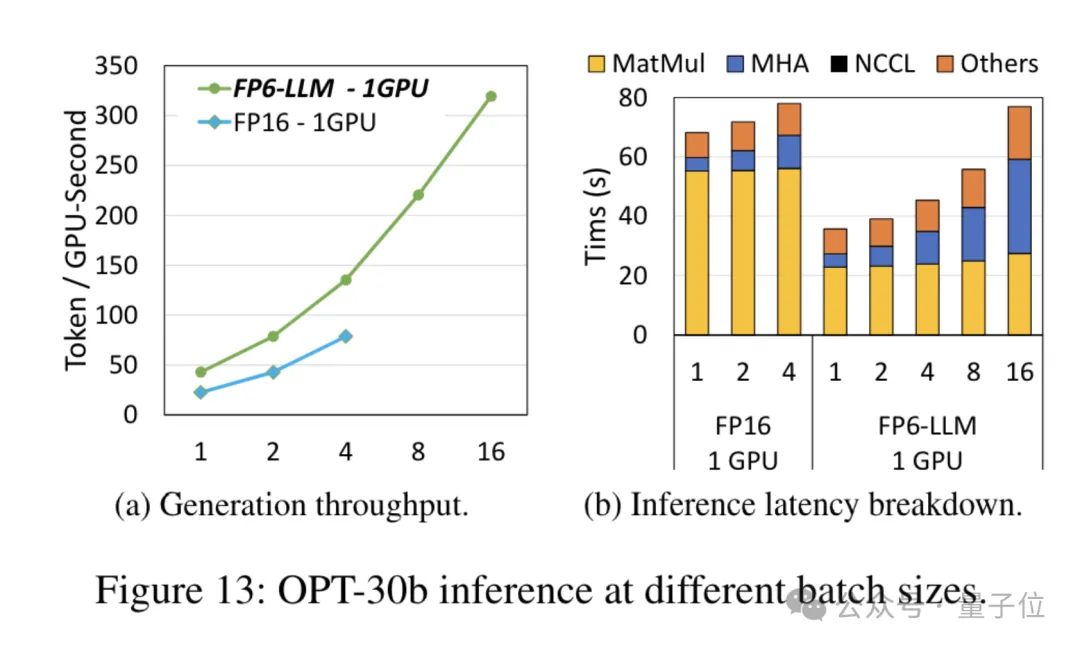
而對於參數量小一些的模型OPT-30B(FP16也使用單卡),FP6-LLM同樣帶來了明顯的吞吐量提升和延遲降低。
而且單卡FP16在這種條件下最多支援的批次大小只有4,FP6-LLM卻可以在批次大小為16的情況下正常運作。
那麼,微軟團隊是怎麼實現在A100上運行FP16量化的呢?
重新設計核心方案
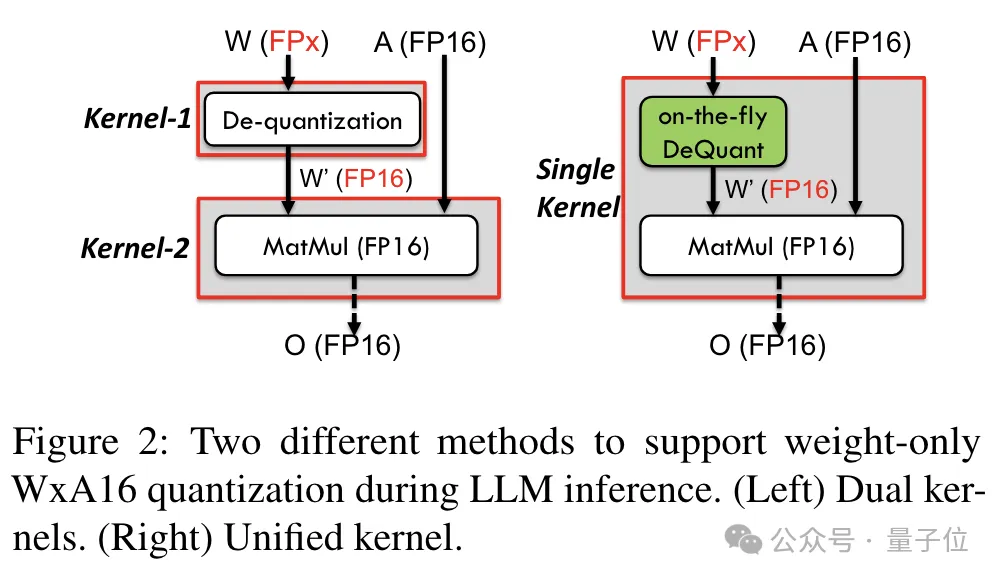
為了實現對包括6bit在內精度的支持,TC-FPx團隊設計了一個統一的核心方案,可以支援不同位寬的量化權重。
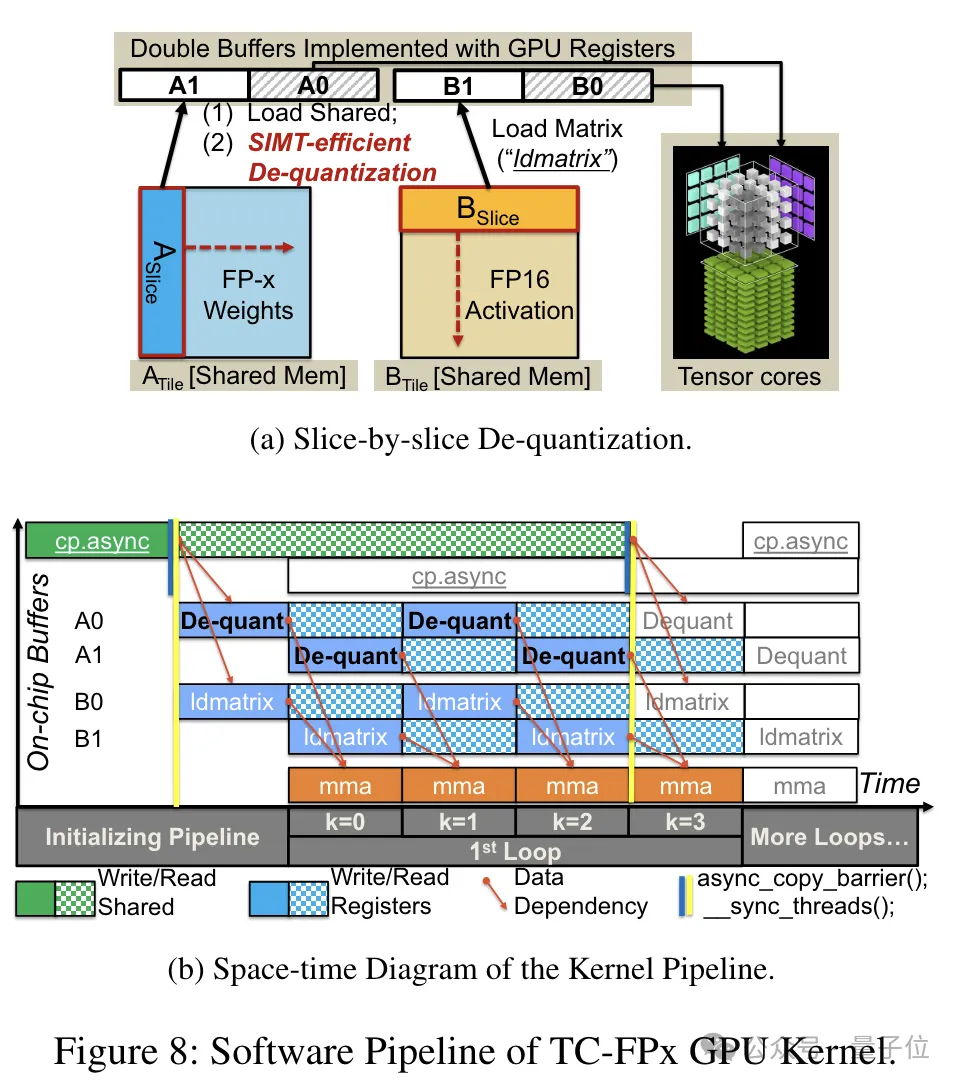
相比於傳統的雙核心方法,TC-FPx透過將去量化和矩陣乘法融合在單一核心中,減少了記憶體存取次數,提高了效能。
實現低精度量化的核心奧義則是通過去量化方式,將FP6精度的數據「偽裝」成FP16,然後按照FP16的格式交給GPU進行運算。
同時團隊也利用了位元級預打包技術,解決GPU記憶體系統對非2的冪次位寬(如6 -bit)不友善的問題。
具體來說,位元級預打包是在模型推理之前對權重資料進行重新組織,包括將6-bit量化的權重重新排列,以便它們能夠以GPU記憶體系統友好的方式進行存取。
此外,由於GPU記憶體系統通常以32位元或64位元的區塊進行資料訪問,位元級預打包技術將還會以6-bit權重打包,使得它們能夠以這些對齊的區塊的形式存儲和訪問。

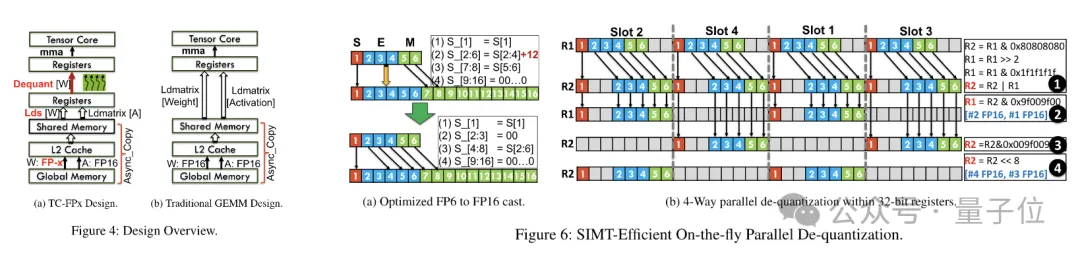
預先打包完成後,研究團隊使用SIMT核心的平行處理能力,對暫存器中的FP6權重執行並行去量化,產生FP16格式的權重。
去量化後的FP16權重在暫存器中被重構,然後送入Tensor Core,並使用重構後的FP16權重執行矩陣乘法運算,完成線性層的計算。
在這個過程中,團隊利用了SMIT核心的位元級並行性,提高了整個去量化過程的效率。
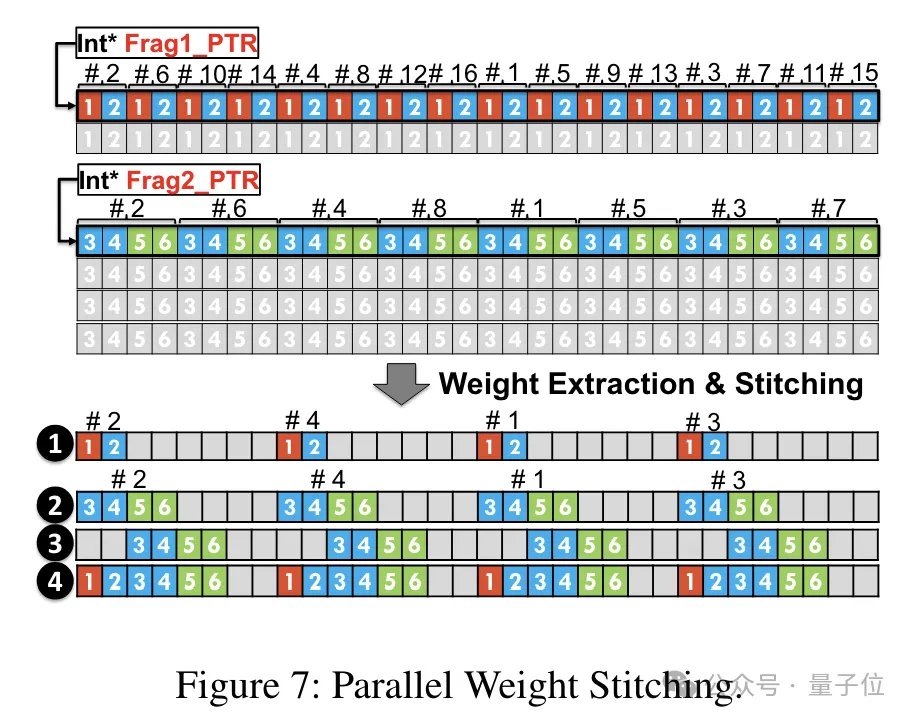
而為了權重構任務能夠並行運行,團隊也使用了一種並行權重拼接技術。
具體來說,每個權重被分割成幾個部分,每個部分的位寬是2的冪次(如把6分割成2 4或4 2)。
在去量化之前,權重首先從共享記憶體載入到暫存器中。由於每個權重被分割成多個部分,需要在運行時在暫存器層級重構完整的權重。
為了減少運行時的開銷,TC-FPx提出了一種平行提取和拼接權重的方法。這種方法使用兩組暫存器來儲存32個FP6權重的片段,並行地重建這些權重。
同時,為了並行提取和拼接權重,需要確保初始資料佈局滿足特定的順序要求,因此TC-FPx透過在運行前對權重片段進行重排。
此外,TC-FPx也設計了一個軟體管線,將去量化步驟與Tensor Core的矩陣乘法運算融合在一起,透過指令層級並行性提高了整體的執行效率。
論文網址:https://arxiv.org/abs/2401.14112
以上是單卡跑Llama 70B快過雙卡,微軟硬生把FP6搞到A100哩 | 開源的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 mysql 和 mariadb 可以共存嗎
Apr 08, 2025 pm 02:27 PM
mysql 和 mariadb 可以共存嗎
Apr 08, 2025 pm 02:27 PM
MySQL 和 MariaDB 可以共存,但需要謹慎配置。關鍵在於為每個數據庫分配不同的端口號和數據目錄,並調整內存分配和緩存大小等參數。連接池、應用程序配置和版本差異也需要考慮,需要仔細測試和規劃以避免陷阱。在資源有限的情況下,同時運行兩個數據庫可能會導致性能問題。
 Bootstrap圖片居中需要用到flexbox嗎
Apr 07, 2025 am 09:06 AM
Bootstrap圖片居中需要用到flexbox嗎
Apr 07, 2025 am 09:06 AM
Bootstrap 圖片居中方法多樣,不一定要用 Flexbox。如果僅需水平居中,text-center 類即可;若需垂直或多元素居中,Flexbox 或 Grid 更合適。 Flexbox 兼容性較差且可能增加複雜度,Grid 則更強大且學習成本較高。選擇方法時應權衡利弊,並根據需求和偏好選擇最適合的方法。
 c上標3下標5怎麼算 c上標3下標5算法教程
Apr 03, 2025 pm 10:33 PM
c上標3下標5怎麼算 c上標3下標5算法教程
Apr 03, 2025 pm 10:33 PM
C35 的計算本質上是組合數學,代表從 5 個元素中選擇 3 個的組合數,其計算公式為 C53 = 5! / (3! * 2!),可通過循環避免直接計算階乘以提高效率和避免溢出。另外,理解組合的本質和掌握高效的計算方法對於解決概率統計、密碼學、算法設計等領域的許多問題至關重要。
 網頁批註如何實現Y軸位置的自適應佈局?
Apr 04, 2025 pm 11:30 PM
網頁批註如何實現Y軸位置的自適應佈局?
Apr 04, 2025 pm 11:30 PM
網頁批註功能的Y軸位置自適應算法本文將探討如何實現類似Word文檔的批註功能,特別是如何處理批註之間的間�...
 wordpress文章列表怎麼調
Apr 20, 2025 am 10:48 AM
wordpress文章列表怎麼調
Apr 20, 2025 am 10:48 AM
有四種方法可以調整 WordPress 文章列表:使用主題選項、使用插件(如 Post Types Order、WP Post List、Boxy Stuff)、使用代碼(在 functions.php 文件中添加設置)或直接修改 WordPress 數據庫。
 Bootstrap如何讓圖片在容器中居中
Apr 07, 2025 am 09:12 AM
Bootstrap如何讓圖片在容器中居中
Apr 07, 2025 am 09:12 AM
綜述:使用 Bootstrap 居中圖片有多種方法。基本方法:使用 mx-auto 類水平居中。使用 img-fluid 類自適應父容器。使用 d-block 類將圖片設置為塊級元素(垂直居中)。高級方法:Flexbox 佈局:使用 justify-content-center 和 align-items-center 屬性。 Grid 佈局:使用 place-items: center 屬性。最佳實踐:避免不必要的嵌套和样式。選擇適合項目的最佳方法。注重代碼的可維護性,避免犧牲代碼質量來追求炫技

 如何讓Element UI中同一行相鄰列的高度自動適應內容?
Apr 05, 2025 am 06:12 AM
如何讓Element UI中同一行相鄰列的高度自動適應內容?
Apr 05, 2025 am 06:12 AM
如何讓同一行相鄰列的高度自動適應內容?在網頁設計中,我們經常會遇到這樣的問題:當一個表格或行內的多...
