
本站發布學術、技術內容的專欄。近年來,本站AIxiv專欄接收通報超過2000篇內容,涵蓋全球各大大學與企業的頂級實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或聯絡報道。投稿信箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com。
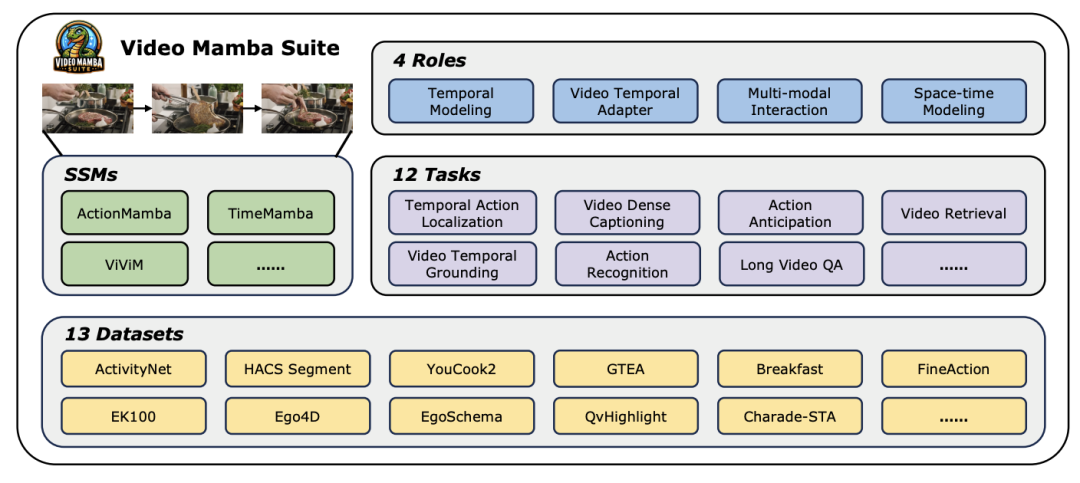
探索影片理解的新境界,Mamba 模型引領電腦視覺研究新潮流!傳統架構的限制已被打破,狀態空間模型 Mamba 以其在長序列處理上的獨特優勢,為視訊理解領域帶來了革命性的變革。 來自南京大學、上海人工智慧實驗室、復旦大學、浙江大學的研究團隊發布了一項開創性工作。他們全面審視了 Mamba 在視訊建模中的多重角色,提出了針對 14 種模型 / 模組的 Video Mamba Suite,在 12 項視訊理解任務中對其進行了深入評估。結果令人振奮:Mamba 在視訊專用和視訊 - 語言任務中都展現出強勁的潛力,實現了效率與性能的理想平衡。這不僅是技術上的飛躍,更是對未來視訊理解研究的強力推動。
- 論文標題:Video Mamba Suite: State Space Model as a Versatile Alternative for Video Understanding
- 論文連結:https://arxiv.org/abs/2403.09626
- 程式碼連結:https://github.com/OpenGVLab/video-mamba-suite
#在當今快速發展的電腦視覺領域,視訊理解技術已成為推動行業進步的關鍵驅動力之一。眾多研究者致力於探索並優化各種深度學習架構,以實現對影片內容的更深層解析。從早期的循環神經網路(RNN)和三維卷積神經網路(3D CNN),到目前廣受矚目的 Transformer 模型,每一次技術的飛躍都大大拓寬了我們對視訊資料的理解和應用。 特別是Transformer 模型,以其卓越的性能在視訊理解的多個領域—— 包括但不限於目標檢測、圖像分割、以及多模態問答等—— 取得了顯著成就。然而,面對視訊資料固有的超長序列特性,Transformer 模型也暴露出了其固有的限制:由於其計算複雜度呈平方增長,使得對超長視頻序列的直接建模變得異常困難。 在這樣的背景下,狀態空間模型架構- 以Mamba 為代表- 應運而生,以其線性運算複雜度的優勢,展現出處理長序列資料的強大潛力,為Transformer 模型的替代提供了可能。儘管如此,目前對於狀態空間模型架構在視訊理解領域的應用,仍有一些限制:一是主要集中在視訊全局理解任務,如分類和檢索;二是主要探索了直接進行時空建模的方式,而對於更多樣化的建模方法的探索尚顯不足。 為了克服這些限制,並全面評估 Mamba 模型在視訊理解領域的潛力,研究團隊精心打造了 video-mamba-suite(影片 Mamba 套件)。該套件旨在補充現有研究的不足,透過一系列深入的實驗和分析,探索 Mamba 在視訊理解中的多樣化角色和潛在優勢。 研究團隊將 Mamba 模型的應用劃分為四種不同的角色,並據此建立了一個包含 14 個模型 / 模組的影片 Mamba 套件。經過 12 個視訊理解任務上的全面評估,實驗結果不僅揭示了 Mamba 在處理視訊和視訊 - 語言任務上的巨大潛力,還展現了其在效率和性能之間取得的卓越平衡。論文作者們期待這項工作能為影片理解領域的未來研究提供可參考的資源和深刻的見解。
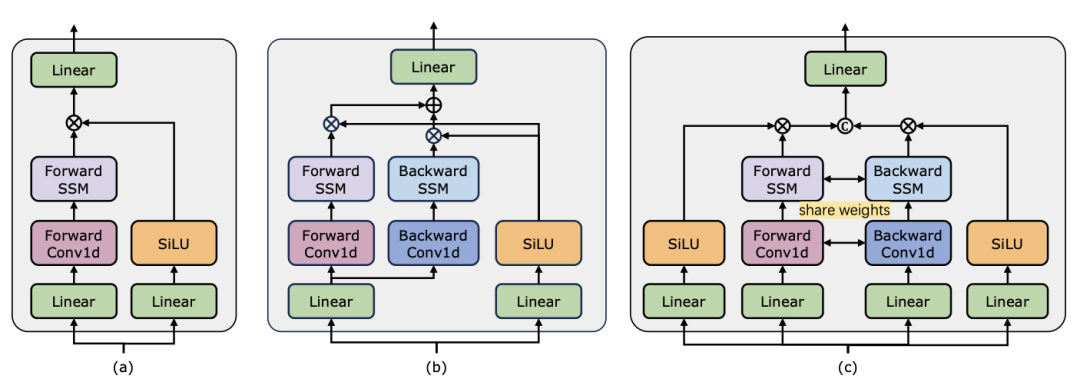
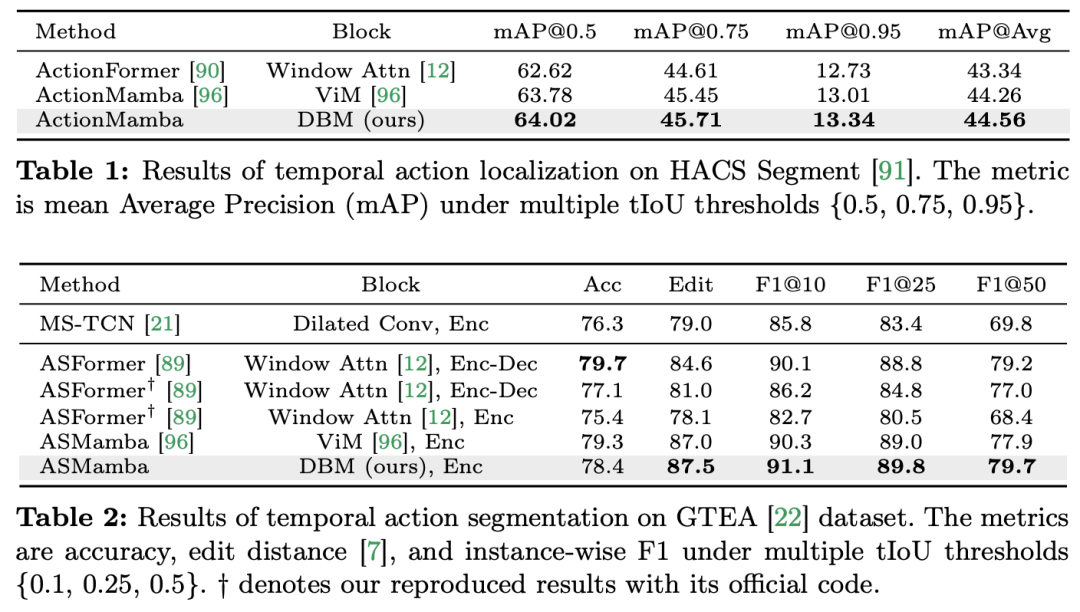
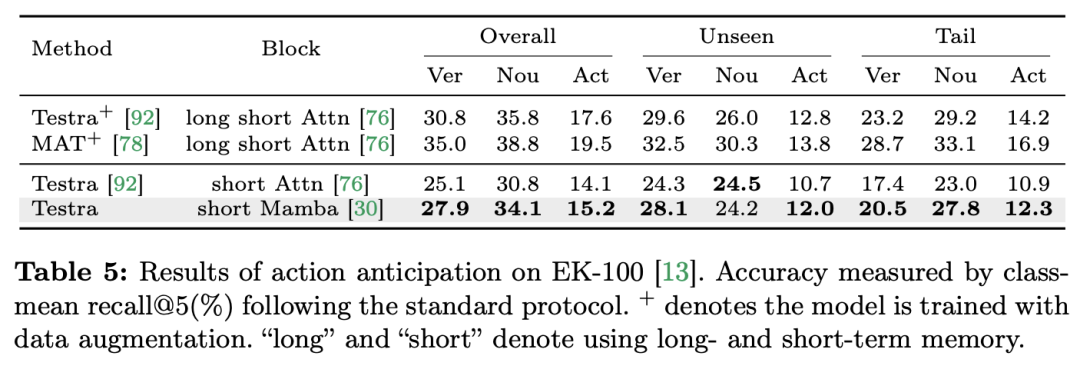
视频理解作为计算机视觉研究的基础问题,其核心在于捕捉视频中的时空动态,用一识别并推断活动的性质及其演变过程。目前,针对视频理解的架构探索主要分为三个方向。首先,基于帧的特征编码方法通过循环网络(如 GRU 和 LSTM)进行时间依赖性建模,但这种分割的时空建模方式难以捕获联合时空信息。其次,三维卷积核的使用在卷积神经网络中实现了对空间和时间相关性的同步考虑。随着语言和图像领域的 Transformer 模型取得巨大成功,视频 Transformer 模型也在视频理解领域取得了显著进展,展现出超越 RNNs 和 3D-CNNs 的能力。视频 Transformer 通过将视频封装在一系列 token 中,并利用注意力机制实现全局上下文交互和数据依赖的动态计算,从而在统一的方式下处理视频中的时间或时空信息。然而,由于视频 Transformer 在处理长视频时的计算效率有限,出现了一些变体模型,它们在速度和性能之间取得了平衡。最近,状态空间模型(SSMs)在自然语言处理(NLP)领域展现了其优势。现代 SSMs 在长序列建模中表现出强大的表征能力,同时保持线性时间复杂度。这是因为它们的选择机制消除了存储完整上下文的需要。特别是 Mamba 模型,将时变参数纳入 SSM,并提出了一种硬件感知算法,以实现高效的训练和推理。Mamba 的出色扩展性能表明,它有望成为 Transformer 的一个有前景的替代方案。同时,Mamba 的高性能和效率使其非常适合视频理解任务。尽管已有一些初步尝试探索 Mamba 在图像 / 视频建模中的应用,但其在视频理解中的有效性尚不明确。针对 Mamba 在视频理解中的潜力进行全面研究的缺失,限制了对其在多样化视频相关任务中能力的进一步探索。针对以上问题,研究团队对 Mamba 在视频理解领域的潜力进行了探索。他们的研究目标是评估 Mamba 是否可以成为该领域的 Transformer 的一个可行替代方案。为此,他们首先要解决的问题是如何看待 Mamba 在理解视频方面中的不同角色。基于此,他们进一步研究了 Mamba 在哪些任务中表现得更出色。论文将 Mamba 在视频建模中的作用分为以下四类:1) 时序模型,2) 时序模块,3) 多模态交互网络,4) 时空模型。针对每种角色,研究团队都在不同的视频理解任务上研究了其视频建模能力。为了公平地让 Manba 与 Transformer 一较高下,研究团队根据标准或改进的 Transformer 架构精心选择了用于对比的模型。在此基础上,他们得到了一个包含 14 个模型 / 模块的 Video Mamba Suite,适用于 12 个视频理解任务。研究团队希望 Video Mamba Suite 能成为未来探索基于 SSM 的视频理解模型的基础型资源。任务和数据:研究团队对 Mamba 在五个视频时间任务上的性能进行了评估:时间动作定位(HACS Segment),时间动作分割(GTEA),密集视频字幕(ActivityNet,YouCook),视频段落字幕(ActivityNet,YouCook)和动作预测(Epic-Kitchen-100)。基准线和挑战者:研究团队选择了基于 Transformer 的模型作为各项任务的基线。具体来说,这些基线模型包括 ActionFormer,ASFormer,Testra 和 PDVC。为了构建 Mamba 的挑战者,他们将基线模型中的 Transformer 模块替换为基于 Mamba 的模块,包括如上图三种模块,原始的 Mamba (a),ViM (b),以及研究团队原创设计的 DBM (c) 模块。值得注意的是,在涉及因果推断的动作预测任务中,论文中将基线模型与原始的 Mamba 模块进行了性能比较。结果和分析:论文中展示了不同模型在四项任务上的比较结果。总体而言,尽管一些基于 Transformer 的模型已经加入了注意力变体来提升性能。下表展示了 Mamba 系列相比现有 Transformer 系列方法,展示出了更加卓越的性能。
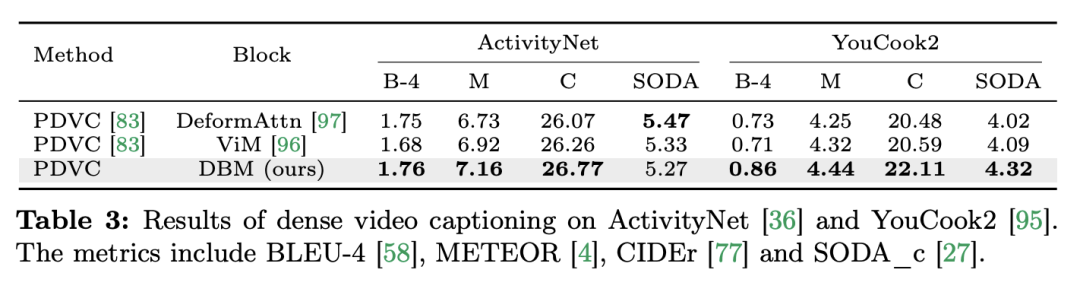
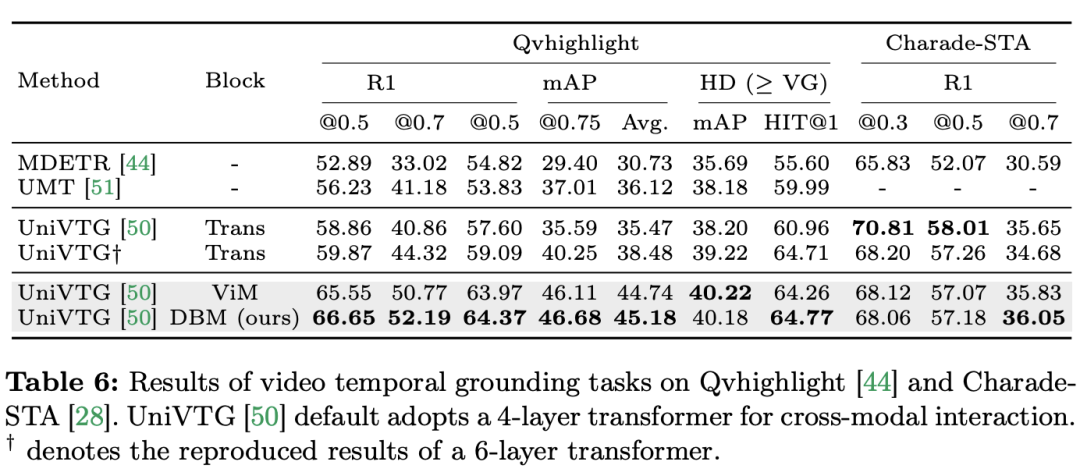
#研究團隊不僅關注了單模態任務,還評估了Mamba 在跨模態互動任務中的表現。論文中採用視訊時間定位(VTG)任務評估了 Mamba 的表現。所涉及的資料集包括 QvHighlight 和 Charade-STA。 任務與資料:研究團隊對Mamba 在五個視訊時間任務上的表現進行了評估:時間動作定位(HACS Segment),時間動作分割(GTEA),密集視訊字幕(ActivityNet,YouCook),影片段落字幕(ActivityNet,YouCook)和動作預測(Epic-Kitchen-100)。 基準與挑戰者:研究團隊使用 UniVTG 來建立基於 Mamba 的 VTG 模型。 UniVTG 採用 Transformer 作為多模態互動網路。給定視訊特徵和文字特徵,他們首先為每個模態添加可學習的位置嵌入和模態類型嵌入,以保留位置和模態資訊。然後,將文字和視訊標記連接起來,形成一個聯合輸入,進一步輸入到多模態 Transformer 編碼器中。最後,提取文字增強的影片特徵,並將其送入預測頭。為了創建跨模態的 Mamba 競爭者,研究團隊選擇了堆疊雙向 Mamba 區塊,形成一個多模態的 Mamda 編碼器,以取代 Transformer 基準。 結果與分析:論文透過 QvHighlight 測試了多個模型的表現。 Mamba 的平均 mAP 為 44.74,與 Transformer 相比有顯著提升。在 Charade-STA 上,基於 Mamba 的方法展示了和 Transformer 類似的競爭力。這表明 Mamba 具有有效整合多種模態的潛力。
考慮到Mamba 是基於線性掃描的模型,而Transformer 基於全域標記交互,研究團隊直觀地認為文字在標記序列中的位置可能會影響多模態聚合的效果。為了調查這一點,他們在表格中包括了不同的文本 - 視覺融合方法,並在圖中展示了四種不同的標記排列方式。結論是,當文字條件與視覺特徵的左側融合時,可以獲得最佳結果。 QvHighlight 對此融合的影響較小,而 Charade-STA 對文字的位置特別敏感,這可能歸因於資料集的特性。
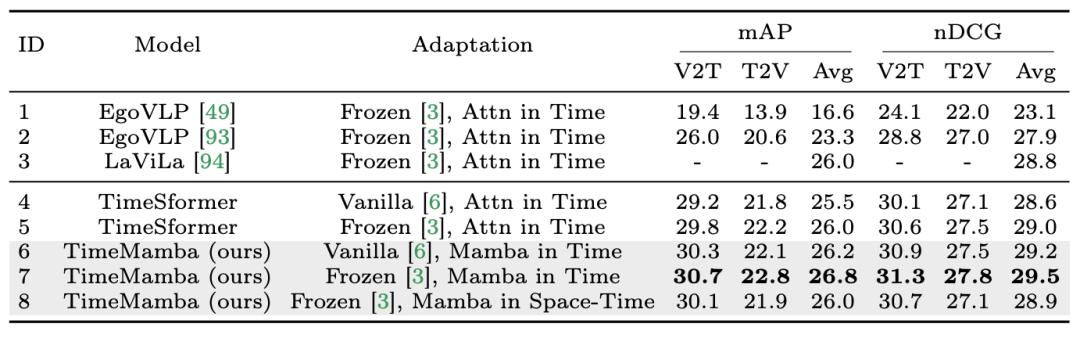
在評估Mamba 在時序後建模方面的表現之外,研究團隊也檢視了其作為視訊時間適配器的有效性。透過在以自我為中心的資料上執行視訊文字對比學習來預訓練雙塔模型,該資料包含 400 萬個帶有細粒度敘述的影片片段。 任務和資料:研究團隊對Mamba 在五個視訊時間任務上的表現進行了評估,其中包括:時序動作定位(HACS Segment),時序動作分割(GTEA),密集視訊字幕(ActivityNet,YouCook),視訊段落字幕(ActivityNet,YouCook)和動作預測(Epic-Kitchen-100)。 基準線和挑戰者:TimeSformer 採用了分開的時空注意力區塊來分別建模影片中的空間和時間關係。為此,研究團隊引入了雙向 Mamba 區塊作為時序適配器,以取代原始的時序自註意力,改善分開的時空互動。為了公平比較,TimeSformer 中的空間注意力層保持不變。在這裡,研究團隊使用了 ViM 區塊作為時序模組,並將結果模型稱為 TimeMamba。 值得注意的是,標準 ViM 區塊比自註意力區塊有更多的參數(略多於),其中 C 是特徵維度。因此,論文中將 ViM 區塊的擴展比率 E 設定為 1,將其參數量減少到,以進行公平比較。除了 TimeSformer 使用的普通殘差連結形式,研究團隊也探索了 Frozen 風格適配方式。以下是5 種適配器結構:
##1.零樣本多實例檢索。研究團隊首先在表中評估了具有分開時空互動操作的不同模型,發現文中復現的 Frozen 風格殘差連結與 LaViLa 的一致。當比較原始和 Frozen 風格時,不難觀察到 Frozen 風格始終產生更好的結果。此外,在相同的適配方法下,基於 ViM 的時間模組始終優於基於注意力的時間模組。
值得注意的是,論文中使用的ViM 時間區塊與時間自註意力區塊相比參數較少,突顯了Mamba 選擇性掃描的較好的參數利用率和資訊提取能力。
此外,研究團隊進一步驗證了時空 ViM 區塊。時空 ViM 區塊以整個視訊序列上的聯合時空建模取代了時序 ViM 區塊。令人驚訝的是,儘管引入了全域建模,但時空 ViM 區塊實際上導致了效能下降。為此,研究團隊推測基於掃描的時空可能會破壞預訓練空間注意力區塊產生空間特徵分佈。以下是實驗結果:
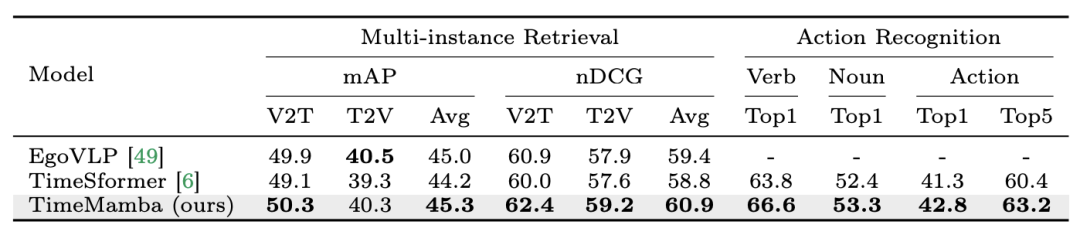
2.微調多實例檢索和動作辨識。研究團隊繼續在 Epic-Kitchens-100 資料集上使用 16 幀微調預訓練模型進行多實例檢索和動作識別。可以從實驗結果中國呢觀察到 TimeMamba 在動詞辨識的上下文中顯著優於 TimeSformer,超出了 2.8 個百分點,這說明 TimeMamba 能夠在細粒度時序方面有效地建模。
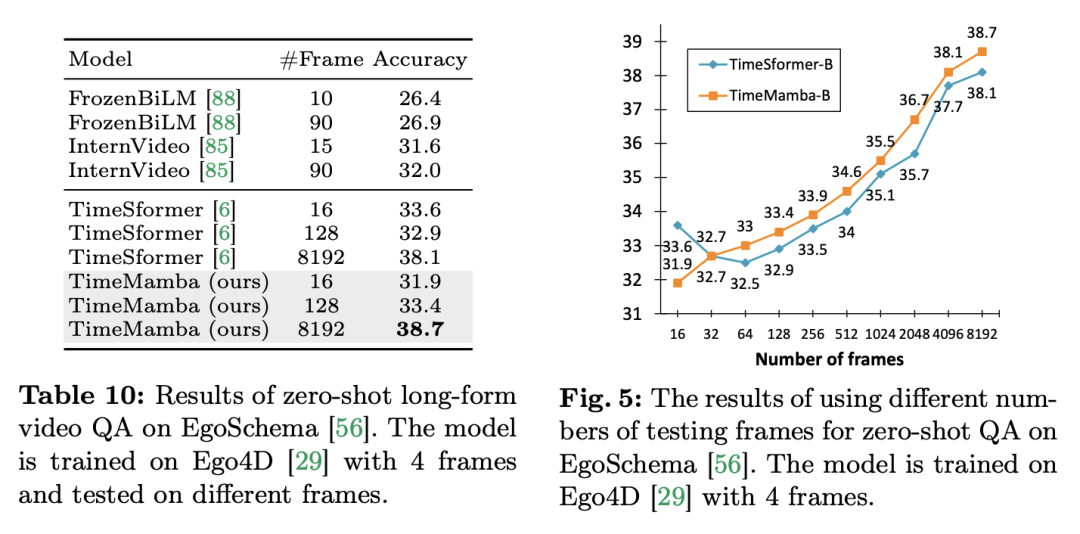
3.零樣本長影片問答。研究團隊在 EgoSchema 資料集上進一步評估了模型的長視訊問答性能。以下是實驗結果:
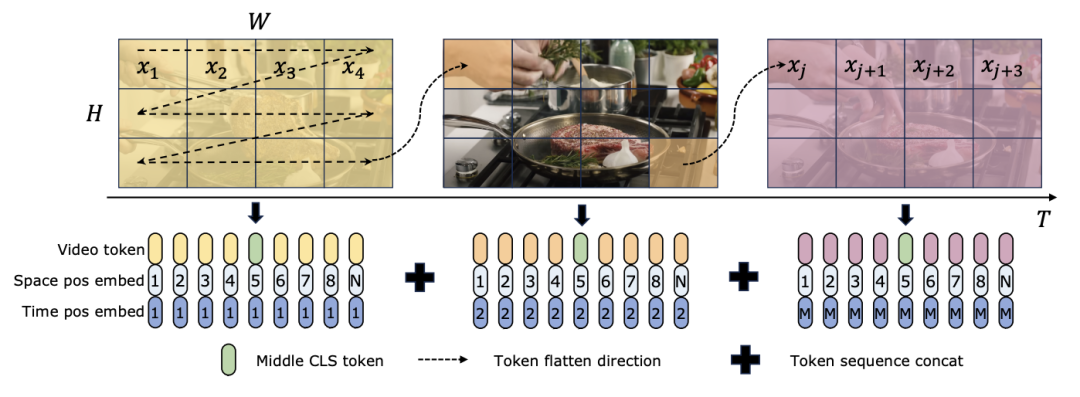
无论是 TimeSformer 还是 TimeMamba,在 Ego4D 上预训练后,都超过了大规模预训练模型(例如 InternVideo)的性能。此外,研究团队从视频开始以固定的 FPS 不断增加了测试帧的数量,以探索 ViM 块长视频时间建模能力的影响。尽管两个模型都是用 4 帧预训练的,但随着帧数的增加,TimeMamba 和 TimeSformer 的性能稳步提高。同时,当使用 8192 帧时,可以观察到显著的改进。当输入帧超过 32 时,TimeMamba 通常比 TimeSformer 从更多的帧数中受益,表明时间 ViM 块在时序自注意力方面具有优越性。任务和数据:此外,论文中还评估了 Mamba 在空间 - 时间建模方面的能力,具体在 Epic-Kitchens-100 数据集上评估了模型在零样本多实例检索方面的性能。基线和竞争者:ViViT 和 TimeSformer 研究了将具有空间注意力的 ViT 转化为具有空间 - 时间联合注意力的模型。基于此,研究团队进一步扩展了 ViM 模型的空间选择性扫描,以包含时空选择性扫描。命名这个扩展后的模型为 ViViM。研究团队使用在 ImageNet-1K 上预训练的 ViM 模型进行初始化。ViM 模型包含了一个 cls token,该 token 被插入到拍平的 token 序列的中间。下图中展示了将 ViM 模型转换为 ViViM的方法。对于给定的包含 M 帧的输入,在每帧对应的 token 序列的中间插入 cls token。此外,研究团队添加了时间位置嵌入,对每个帧初始化为零。然后将展平的视频序列输入到 ViViM 模型中。模型的输出是通过计算每帧的 cls token 的平均值来得到的。
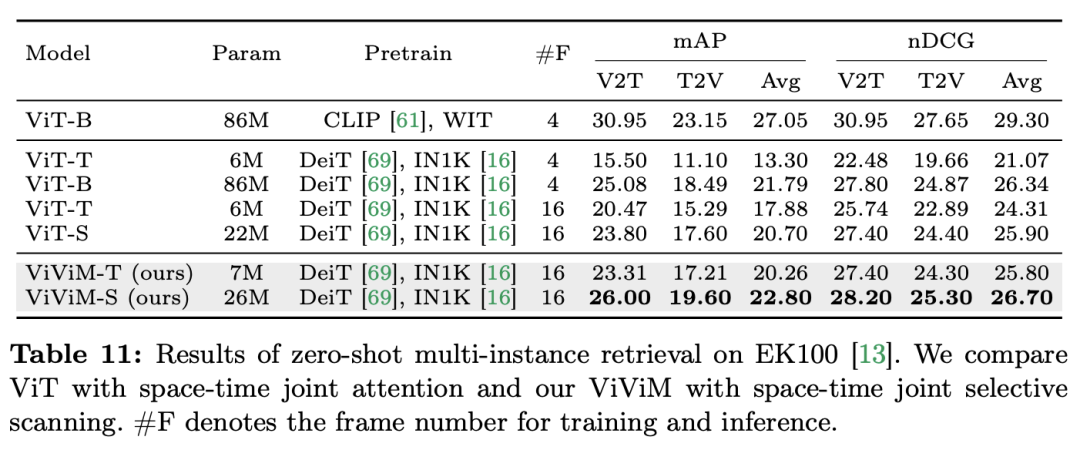
结果和分析:论文中进一步研究了 ViViM 在零样本多实例检索方面的结果,实验结果如下表所示:
结果展示了不同时空模型在零样本多实例检索上的性能。当比较 ViT 和 ViViM 时,两者都是在 ImageNet-1K 上预训练的,可以观察到 ViViM 的性能超过了 ViT。有趣的是,尽管在 ImageNet-1K 上 ViT-S 和 ViM-S 之间的性能差距很小(79.8 vs 80.5),但 ViViM-S 在零样本多实例检索上显示出显著的改进( 2.1 mAP@Avg),这表明 ViViM 在建模长序列方面非常有效,从而提高了性能。这篇论文通过全面评估 Mamba 视频理解领域的表现,展示了 Mamba 可以作为传统 Transformers 的可行替代方案的潜力。通过包含 12 个视频理解任务的 14 个模型 / 模块组成的 Video Mamba Suite,研究团队展示了 Mamba 高效处理复杂时空动态的能力。Mamba 不仅性能超群,还能够更好地实现效率 - 性能之间的平衡。这些发现不仅强调了 Mamba 适用于视频分析任务,而且还为其在计算机视觉领域的应用开辟了新的途径。未来的工作可以进一步探索 Mamba 的适应性,并将其效用扩展到更复杂的多模态视频理解挑战中。以上是在12個影片理解任務中,Mamba先打敗了Transformer的詳細內容。更多資訊請關注PHP中文網其他相關文章!






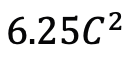 ),其中 C 是特徵維度。因此,論文中將 ViM 區塊的擴展比率 E 設定為 1,將其參數量減少到
),其中 C 是特徵維度。因此,論文中將 ViM 區塊的擴展比率 E 設定為 1,將其參數量減少到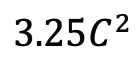 ,以進行公平比較。除了 TimeSformer 使用的普通殘差連結形式,研究團隊也探索了 Frozen 風格適配方式。以下是5 種適配器結構:
,以進行公平比較。除了 TimeSformer 使用的普通殘差連結形式,研究團隊也探索了 Frozen 風格適配方式。以下是5 種適配器結構: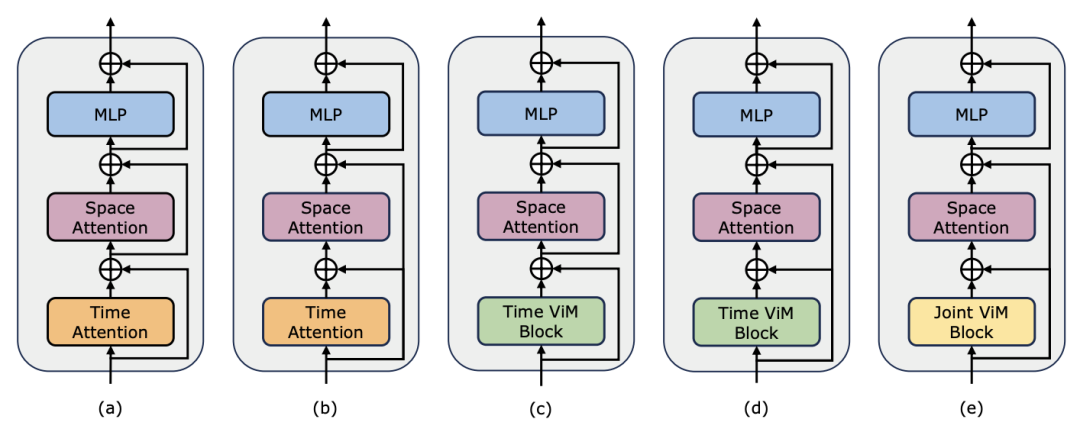















 vscode怎麼在終端運行程序
Apr 15, 2025 pm 06:42 PM
vscode怎麼在終端運行程序
Apr 15, 2025 pm 06:42 PM
 vscode是什麼 vscode是乾什麼用的
Apr 15, 2025 pm 06:45 PM
vscode是什麼 vscode是乾什麼用的
Apr 15, 2025 pm 06:45 PM
 vscode 可以在 mac 上嗎
Apr 15, 2025 pm 07:45 PM
vscode 可以在 mac 上嗎
Apr 15, 2025 pm 07:45 PM
 vscode開始怎麼設置
Apr 15, 2025 pm 10:45 PM
vscode開始怎麼設置
Apr 15, 2025 pm 10:45 PM
 vs code 可以在 Windows 8 中運行嗎
Apr 15, 2025 pm 07:24 PM
vs code 可以在 Windows 8 中運行嗎
Apr 15, 2025 pm 07:24 PM
 vscode 可以比較兩個文件嗎
Apr 15, 2025 pm 08:15 PM
vscode 可以比較兩個文件嗎
Apr 15, 2025 pm 08:15 PM
 vscode 無法重命名文件夾怎麼解決
Apr 15, 2025 pm 06:09 PM
vscode 無法重命名文件夾怎麼解決
Apr 15, 2025 pm 06:09 PM
 vscode 可以運行 jupyter notebook 嗎
Apr 15, 2025 pm 06:21 PM
vscode 可以運行 jupyter notebook 嗎
Apr 15, 2025 pm 06:21 PM
