

CVPR 2024 | 借助神經結構光,浙大實現動態三維現象的即時擷取重建


AIxiv專欄是本站發布學術、技術內容的欄位。過去數年,本站AIxiv專欄接收通報了2,000多篇內容,涵蓋全球各大專院校與企業的頂尖實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或聯絡報道。投稿信箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com。
煙霧等動態三維物理現象的高效高品質重建是相關科學研究中的重要議題,在空氣動力學設計驗證中,氣像三維觀測等領域有著廣泛的應用前景。透過集重建隨時間變化的三維密度序列,可以幫助科學家更好地理解與驗證實際世界中的各類複雜物理現象。

圖1展示了觀測動態三維物理現象對科學研究的重要性。圖為全球最大風洞NFAC對商用卡車實體進行空氣動力學實驗。
然而,在現實世界中快速取得並高品質重建動態三維密度場相當困難。首先,三維資訊難以透過常見的二維影像感測器(如相機)直接測量。此外,高速變化的動態現象對物理採集能力提出了很高的要求:需要在很短的時間內完整截取單一三維密度場的完整取樣,否則三維密度場本身將會改變。這裡的根本挑戰是如何解決測量樣本本身和動態三維密度場重建結果之間的資訊量差距。
目前主流研究工作透過先驗知識彌補測量樣本資訊量不足,計算代價高,且當先驗條件不滿足時重建品質不佳。與主流研究思路不同,浙江大學電腦輔助設計與圖形系統全國重點實驗室的研究團隊認為解決難題的關鍵在於提高單元測量樣本的資訊量。
該研究團隊不僅利用AI優化重建演算法,還透過AI幫助設計物理採集方式,實現同一目標驅動的全自動軟硬體聯合優化,從本質上提高單元測量樣本關於目標對象的信息量。透過對真實世界中的物理光學現象進行仿真,讓人工智慧自己決定如何投射結構光,如何擷取對應的影像,以及如何從取樣本中重建出動態三維密度場。最終,研究團隊僅使用包含單投影機和少量相機(1或3台)的輕量級硬體原型,把建模單一三維密度場(空間解析度128x128x128)的結構光圖案數量降到6張,實現每秒40個三維密度場的高效採集集。
團隊在重建演算法中創新地提出輕量級一維解碼器,將局部輸入光作為解碼器輸入的一部分,在不同相機所拍攝的不同素材下共用了解碼器參數,大幅降低網路的複雜程度,提高運算速度。為融合不同相機的解碼結果,又設計了結構簡單的3D U-Net融合網路。最終重建單一三維密度場僅需9.2毫秒,相對於SOTA研究工作,重建速度提升了2-3個數量級,實現了三維密度場的即時高品質重建。相關研究論文《Real-time Acquisition and Reconstruction of Dynamic Volumes with Neural Structured Illumination》已被電腦視覺領域頂尖國際學術會議CVPR 2024接收。

論文連結:https://svbrdf.github.io/publications/realtimedynamic/realtimedynamic.pdf
#研究首頁:https://svbrdf.github.io/publications/realtimedynamic/project.html


第一類基於非可控光照的工作不需要專門的光源,在採集過程中不控制光照,因此對採集條件要求較寬鬆 [2,3]。由於單視角相機拍攝到的是三維結構的二維投影,因此難以高品質區分不同的三維結構。對此,一種想法是增加擷取視角取樣數,例如使用密集相機陣列或光場相機,這會導致高昂的硬體成本。另一種想法仍然在視角域稀疏採樣,透過各類先驗資訊來填補資訊量缺口,如啟發式先驗、物理規則或從現有資料中學習的先驗知識。一旦先驗條件在實際中不滿足,這類方法的重建結果會品質下降。此外,其計算開銷過於昂貴,無法支援即時重建。
第二類工作採用可控光照,在採集過程中對光照條件進行主動控制 [4,5]。此類工作對光照進行編碼以更主動地探測物理世界,也減少對先驗的依賴,從而獲得更高的重建品質。根據同時使用單燈或多燈,相關工作可以進一步分類為掃描方法和光照多重化方法。對於動態的實體對象,前者必須透過使用昂貴的硬體來達到高掃描速度,或犧牲結果的完整性來減少擷取負擔。後者透過同時對多個光源進行編程,顯著提高了採集效率。但是對於高品質的快速即時密度場,已有方法的取樣效率仍然不足 [5]。
浙大團隊的工作屬於第二類。和大多數現有工作不同的是,本研究工作利用人工智慧來聯合優化物理採集(即神經結構光)與計算重建,從而實現高效高品質動態三維密度場建模。
硬體原型
研究團隊建造由單一商用投影機(BenQ X3000:解析度1920×1080, 速度240fps)和三個工業相機(Basler acA1440- 220umQGR:由解析度1440×1080, 速度240fps)組成的簡單硬體原型(如圖3 所示)。透過投影機循環投射 6 個預先訓練得到的結構光圖案,三個相機同步進行拍攝,並基於相機所擷取的影像進行動態三維密度場重建。四個設備相對於採集物件的角度是由不同模擬實驗模擬後所選出的最優排布。
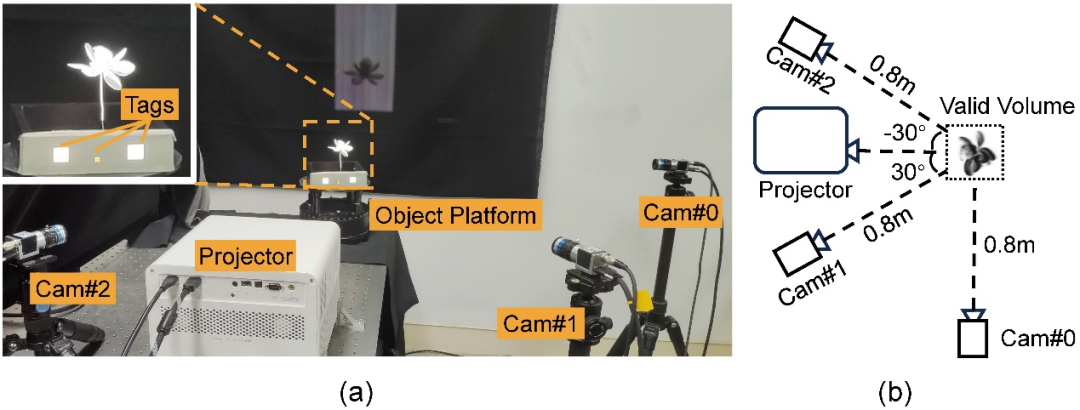
圖 3:擷取硬體原型。 (a)硬體原型實拍圖,其中載物台上的三個白色標記(tags)用於同步相機和投影機。 (b)相機、投影機與拍攝對象之間幾何關係的示意圖(頂部視角)。
軟體處理
研發團隊設計由編碼器、解碼器和聚合模組組成的深度神經網路。其編碼器中的權重直接對應採集期間的結構光照亮度分佈。解碼器以單像素上測量樣本為輸入,預測一維密度分佈並內插至三維密度場。聚合模組將每個相機所對應解碼器預測的多個三維密度場組合成最終的結果。透過使用可訓練結構光以及和輕量級一維解碼器,本研究更容易學習到結構光圖案,二維拍攝照片和三維密度場三者之間的本質聯繫,不容易過度擬合到訓練數據中。以下圖 4 顯示整體管線,圖 5 顯示相關網路結構。

圖4:整體採集重建管線(a),以及從結構光圖案到一維局部入射光(b) 和從預測的一維密度分佈回到三維密度場(c) 的重採樣過程。研究從模擬 / 真實的三維密度場開始,首先將預先最佳化的結構光圖案(即編碼器中的權重)投影到該密度場。對於每個相機視圖中的每個有效像素,將其所有測量值以及重採樣的局部入射光送給解碼器,以預測對應相機光線上的一維密度分佈。然後收集一台相機的所有密度分佈並將其重採樣到單一三維密度場中。在多相機情況下,研究融合每台相機的預測密度場以獲得最終結果。
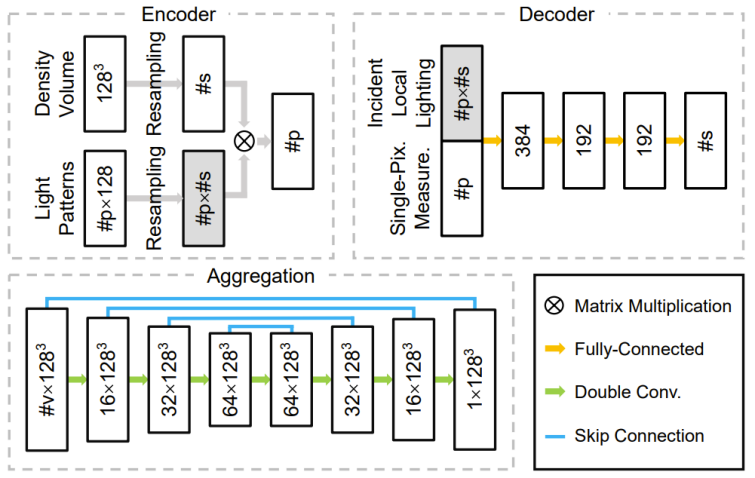
圖 上中:網路 3 個主要元件中的程式設計工具、解碼器和模組解碼器。
結果展示
圖 6 展示本方法對四個不同動態場景的部分重建結果。為產生動態水霧,研究人員將乾冰添加到裝有液態水的瓶子中製造水霧,並透過閥門控制流量,並使用橡膠管將其進一步引導至採集裝置。
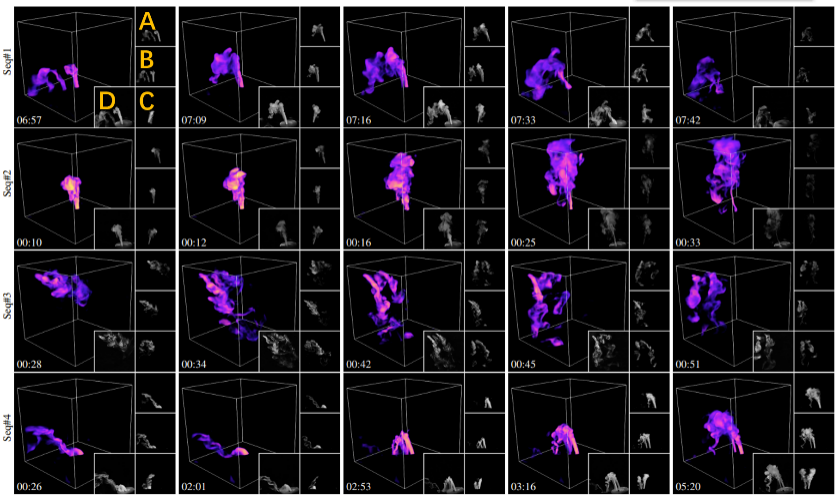
圖 6:不同動態場景的重建結果。每一行是某水霧序列中選取部分重建影格的視覺化結果,從上到下場景水霧源數分別為:1,1,3 和 2。如左上方的橘色標註所示,A,B,C 分別對應三個輸入相機所擷取的影像,D 為和重建結果渲染視角類似的實拍參考影像。時間戳在左下角展示。詳細的動態重建結果請參考論文影片。
為了驗證本研究的正確性和質量,研究團隊在真實靜態物體上把本方法和相關 SOTA 方法進行對比(如圖 7 所示)。圖 7 也同時對不同相機數量下的重建品質進行比較。所有重建結果在相同的未採集過的新視角下繪製,並由三個評估指標進行定量評估。由圖 7 可知,得益於對採集效率的優化,本方法的重建品質優於 SOTA 方法。

圖 7:不同技巧在真實靜態物件上的比較。從左到右是光學層切方法[4],本方法(三相機),本方法(雙相機),本方法(單相機),單相機下使用手工設計的結構光[5],SOTA 的PINF [3] 和GlobalTrans [2] 方法的重建結果視覺化。以光學層切結果為基準,對於所有其他結果,其定量誤差列在對應影像的右下角,以三種指標 SSIM/PSNR/RMSE (×0.01) 來評估。所有重建密度場均使用非輸入視圖進行渲染,#v 表示採集的視圖數量,#p 表示所用結構光圖案的數量。
研究團隊也在動態模擬資料上對不同方法的重建品質進行定量比較。圖 8 展示模擬菸霧序列的重建品質比較。詳細的逐幀重建結果請參考論文影片。

圖 8:不同方法在模擬煙霧序列上的比較。由左至右依序為真實值,本方法,PINF [3] 和 GlobalTrans [2] 重建結果。輸入視圖和新視圖的渲染結果分別顯示在第一行和第二行。定量誤差 SSIM/PSNR/RMSE (×0.01) 顯示在對應影像的右下角。整個重建序列的誤差平均值請參考論文補充資料。另外,整個序列的動態重建結果請參考論文影片。
未來展望
研究團隊計畫在更先進的採集設備(如光場投影機[6])上應用本方法開展動態採集重建。團隊也期望透過採集更豐富的光學資訊(如偏振狀態),從而進一步減少採集所需的結構光圖案數量和相機數量。除此之外,將本方法與神經表現(如 NeRF)結合也是團隊感興趣的未來發展方向之一。最後,讓AI 更主動參與對物理採集與計算重建的設計,不局限於後期軟體處理,這可能能為進一步提升物理感知能力提供新的思路,最終實現不同複雜物理現象的高效高品質建模。
參考資料:
#[1]. Inside the World's Largest Wind Tunnel https://youtu.be /ubyxYHFv2qw?si=KK994cXtARP3Atwn
[2]. Erik Franz, Barbara Solenthaler, and Nils Thuerey. Global transport for fluid reconstruction with learned haler, and Nils Thuerey. Global transport for fluid reconstruction with learned haler, and Nils Thuerey. Global transport for fluid reconstruction with learned haler, and Nils Thuerey. Global transport for fluid reconstruction with learned haler, and Nils Thuerey. Global transport for fluid pages 1632–1642, 2021.
[3]. Mengyu Chu, Lingjie Liu, Quan Zheng, Erik Franz, HansPeter Seidel, Christian Theobalt, and Rhaleb Zayer . Physics informed neural fields for smoke reconstruction with sparse data. ACM Transactions on Graphics, 41 (4):1–14, 2022.
[4]. Tim Hawkins, Per Einarsson, and Paul Debevec. Acquisition of time-varying participating media. ACM Transactions on Graphics, 24 (3):812–815, 2005.
[5]. Jinwei Gu, Shree K. Nayar, Eitan Grinspun, Peter N. Belhumeur,and Ravi Ramamoorthi. Compressive structured light for recovering inhomogeneous participating media.IEEE Transactions on Pattern Analysis and Machine Intelligencegeneous participating media.IEEE Transactions on Pattern Analysis and Machine Intelligence,35 (3):1 –1, 2013.
[6]. Xianmin Xu, Yuxin Lin, Haoyang Zhou, Chong Zeng, Yaxin Yu, Kun Zhou, and Hongzhi Wu. A unified spatial-angular structured light for single-view acquisition of shape and reflectance. In CVPR, pages 206–215, 2023.
#以上是CVPR 2024 | 借助神經結構光,浙大實現動態三維現象的即時擷取重建的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 git怎麼下載項目到本地
Apr 17, 2025 pm 04:36 PM
git怎麼下載項目到本地
Apr 17, 2025 pm 04:36 PM
要通過 Git 下載項目到本地,請按以下步驟操作:安裝 Git。導航到項目目錄。使用以下命令克隆遠程存儲庫:git clone https://github.com/username/repository-name.git
 git怎麼更新代碼
Apr 17, 2025 pm 04:45 PM
git怎麼更新代碼
Apr 17, 2025 pm 04:45 PM
更新 git 代碼的步驟:檢出代碼:git clone https://github.com/username/repo.git獲取最新更改:git fetch合併更改:git merge origin/master推送更改(可選):git push origin master
 git怎麼刪除倉庫
Apr 17, 2025 pm 04:03 PM
git怎麼刪除倉庫
Apr 17, 2025 pm 04:03 PM
要刪除 Git 倉庫,請執行以下步驟:確認要刪除的倉庫。本地刪除倉庫:使用 rm -rf 命令刪除其文件夾。遠程刪除倉庫:導航到倉庫設置,找到“刪除倉庫”選項,確認操作。
 git下載不動怎麼辦
Apr 17, 2025 pm 04:54 PM
git下載不動怎麼辦
Apr 17, 2025 pm 04:54 PM
解決 Git 下載速度慢時可採取以下步驟:檢查網絡連接,嘗試切換連接方式。優化 Git 配置:增加 POST 緩衝區大小(git config --global http.postBuffer 524288000)、降低低速限制(git config --global http.lowSpeedLimit 1000)。使用 Git 代理(如 git-proxy 或 git-lfs-proxy)。嘗試使用不同的 Git 客戶端(如 Sourcetree 或 Github Desktop)。檢查防火
 如何解決PHP項目中的高效搜索問題? Typesense助你實現!
Apr 17, 2025 pm 08:15 PM
如何解決PHP項目中的高效搜索問題? Typesense助你實現!
Apr 17, 2025 pm 08:15 PM
在開發一個電商網站時,我遇到了一個棘手的問題:如何在大量商品數據中實現高效的搜索功能?傳統的數據庫搜索效率低下,用戶體驗不佳。經過一番研究,我發現了Typesense這個搜索引擎,並通過其官方PHP客戶端typesense/typesense-php解決了這個問題,大大提升了搜索性能。
 git怎麼合併代碼
Apr 17, 2025 pm 04:39 PM
git怎麼合併代碼
Apr 17, 2025 pm 04:39 PM
Git 代碼合併過程:拉取最新更改以避免衝突。切換到要合併的分支。發起合併,指定要合併的分支。解決合併衝突(如有)。暫存和提交合併,提供提交消息。
 git commit怎麼用
Apr 17, 2025 pm 03:57 PM
git commit怎麼用
Apr 17, 2025 pm 03:57 PM
Git Commit 是一種命令,將文件變更記錄到 Git 存儲庫中,以保存項目當前狀態的快照。使用方法如下:添加變更到暫存區域編寫簡潔且信息豐富的提交消息保存並退出提交消息以完成提交可選:為提交添加簽名使用 git log 查看提交內容
 git怎麼更新本地代碼
Apr 17, 2025 pm 04:48 PM
git怎麼更新本地代碼
Apr 17, 2025 pm 04:48 PM
如何更新本地 Git 代碼?用 git fetch 從遠程倉庫拉取最新更改。用 git merge origin/<遠程分支名稱> 將遠程變更合併到本地分支。解決因合併產生的衝突。用 git commit -m "Merge branch <遠程分支名稱>" 提交合併更改,應用更新。
