

LeCun上月球?南開、位元組開源StoryDiffusion讓多圖漫畫和長影片更連貫

兩天前,圖靈獎得主 Yann LeCun 轉載了「自己登上月球去探索」的長篇漫畫,引起了網友的熱議。

在《Story Diffusion:Consistent Self-Attention for long-range image and video generation》論文中,研究團隊提出了一種名為Story Diffusion的新方法,用於產生一致的圖像和影片描述複雜情景。這些漫畫的研究來自南開大學、位元組跳動等機構。

- #論文網址:https://arxiv.org/pdf/2405.01434v1
- 專案首頁:https://storydiffusion.github.io/
相關專案已經在GitHub 上獲得了1k 的Star 量。
GitHub 網址:https://github.com/HVision-NKU/StoryDiffusion
根據專案演示,StoryDiffusion 可以產生各種風格的漫畫,在講述連貫故事的同時,保持了角色風格和服裝的一致性。

StoryDiffusion 可以同時保持多個角色的身份,並在一系列影像中產生一致的角色。

此外,StoryDiffusion 也能夠以產生的一致影像或使用者輸入的影像為條件,產生高品質的影片。


我們知道,對於基於擴散的生成模型來說,如何在一系列生成的圖像中保持內容一致性,尤其是那些包含複雜主題和細節的圖像,是一個重大挑戰。
因此,該研究團隊提出了一種新的自註意力計算方法,稱為一致性自註意力(Consistent Self-Attention),透過在生成圖像時建立批內圖像之間的聯繫,以保持人物的一致性,無需訓練即可產生主題一致的圖像。
為了將這種方法擴展到長視頻生成,該研究團隊引入了語義運動預測器(Semantic Motion Predictor),將圖像編碼到語義空間,預測語義空間中的運動,以產生視頻。這比僅基於潛在空間的運動預測更穩定。
然後進行框架整合,將一致性自註意力和語義運動預測器結合,可以產生一致的視頻,講述複雜的故事。相較於現有方法,StoryDiffusion 可以產生更流暢、連貫的影片。

圖1: 透過團隊StroyDiffusion 產生的圖像和影片
##方法概覽
##該研究團隊的方法可以分為兩個階段,如圖2 和圖3 所示。
#########在第一階段,StoryDiffusion 使用一致性自註意力(Consistent Self-Attention)以無訓練的方式產生主題一致的影像。這些一致的圖像可以直接用於講故事,也可以作為第二階段的輸入。在第二階段,StoryDiffusion 基於這些一致的影像創建一致的過渡影片。 ######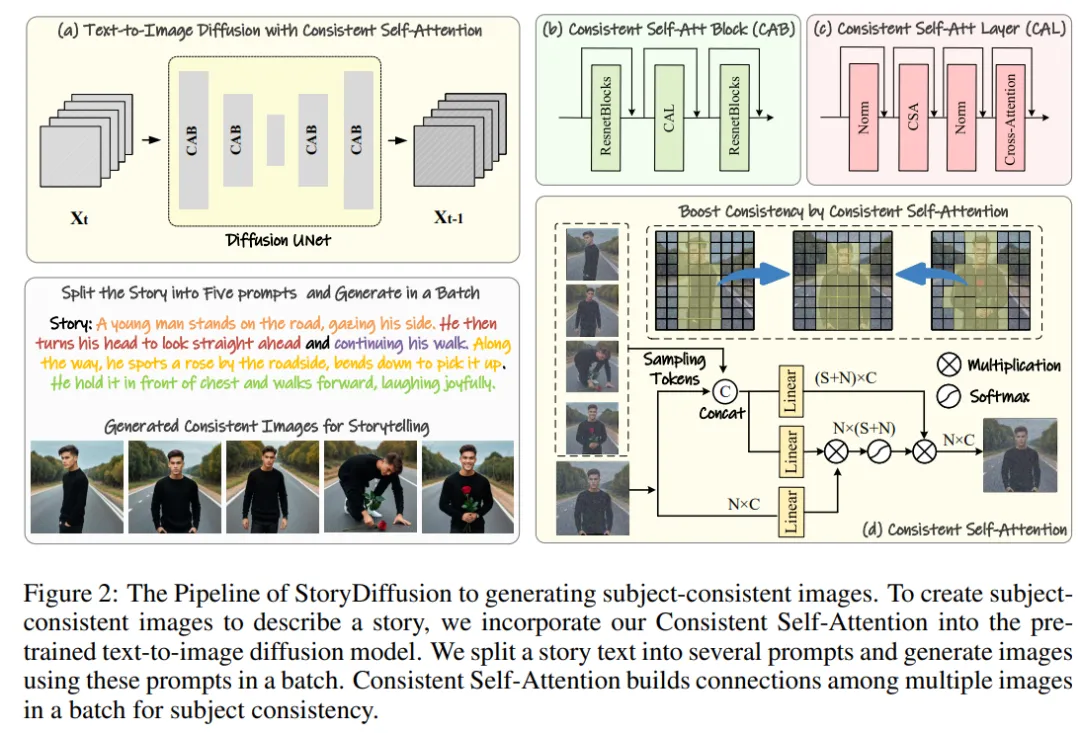
圖2:StoryDiffusion 產生主題一致影像的流程概述
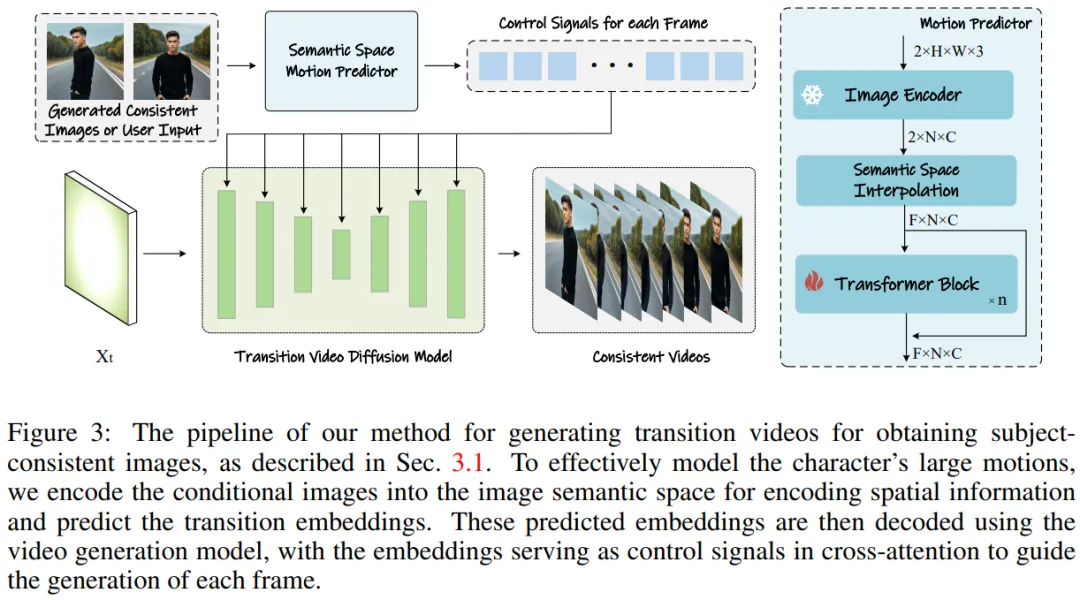 圖3:產生轉場影片以獲得主題一致圖像的方法。
圖3:產生轉場影片以獲得主題一致圖像的方法。
無訓練的一致圖像生成
研究團隊介紹了「如何以無訓練的方式產生主題一致的圖像」的方法。解決上述問題的關鍵在於如何保持一批影像中角色的一致性。這意味著在生成過程中,他們需要建立一批影像之間的連結。
在重新審視了擴散模型中不同註意力機制的作用之後,他們受到啟發,探索利用自註意力來保持一批影像內影像的一致性,並提出了一致性自註意力(Consistent Self-Attention)。
研究團隊將一致性自註意力插入現有影像產生模型的U-Net 架構中原有自註意力的位置,並重複使用原有的自註意力權重,以保持無需訓練和即插即用的特性。
鑑於配對 tokens,研究團隊的方法在一批圖像上執行自註意力,促進不同圖像特徵之間的交互作用。這種類型的互動促使模型在生成過程中對角色、臉部和服裝的收斂性。儘管一致性自註意力方法簡單且無需訓練,但它可以有效地產生主題一致的圖像。
為了更清楚地說明,研究團隊在演算法 1 中展示了偽代碼。

用於影片產生的語意運動預測器
研究團隊提出了語義運動預測器(Semantic Motion Predictor),它將圖像編碼到圖像語義空間中以捕獲空間訊息,從而實現從一個給定的起始幀和結束幀中進行更準確的運動預測。
更具體地說,在該團隊所提出的語義運動預測器中,他們首先使用一個函數E 來建立從RGB 圖像到圖像語義空間向量的映射,對空間資訊進行編碼。
該團隊並沒有直接使用線性層作為函數E,與之代替的是利用一個預先訓練的CLIP 影像編碼器作為函數E,以利用其零樣本(zero- shot)能力來提升效能。
使用函數 E,給定的起始幀 F_s 和結束幀 F_e 被壓縮成圖像語義空間向量 K_s 和 K_e。

實驗結果
#在產生主題一致圖像方面,由於該團隊的方法是無需訓練且可即插即用的,所以他們在Stable Diffusion XL 和Stable Diffusion 1.5 兩個版本上都實作了這個方法。為了與對比模型保持一致,他們在 Stable-XL 模型上使用相同的預訓練權重進行比較。
針對生成一致性視頻,研究者基於 Stable Diffusion 1.5 特化模型實現了他們的研究方法,並整合了一個預訓練的時間模組以支援視頻生成。所有的比較模型都採用了 7.5 classifier-free 指導分數和 50-step DDIM 採樣。
一致性圖像產生比較
#該團隊透過與兩種最新的ID 保存方法-IP- Adapter 和Photo Maker— 進行比較,評估了他們產生主題一致影像的方法。
為了測試效能,他們使用 GPT-4 產生了二十個角色指令和一百個活動指令,以描述特定的活動。
定性結果如圖4 所示:「StoryDiffusion 能夠產生高度一致的圖像。而其他方法,如IP-Adapter 和PhotoMaker,可能會產生服飾不一致或文字可控性降低的圖像。 图4: 与目前方法在一致性图像生成上的对比结果图 研究者们在表 1 中展示了定量比较的结果。该结果显示:「该团队的 StoryDiffusion 在两个定量指标上都取得了最佳性能,这表明该方法在保持角色特性的同时,还能够很好地符合提示描述,并显示出其稳健性。」 转场视频生成的对比 在转场视频生成方面,研究团队与两种最先进的方法 ——SparseCtrl 和 SEINE—— 进行了比较,以评估性能。 他们进行了转场视频生成的定性对比,并将结果展示在图 5 中。结果显示:「该团队的 StoryDiffusion 显著优于 SEINE 和 SparseCtrl,并且生成的转场视频既平滑又符合物理原理。」 图 5: 目前使用各种最先进方法的转场视频生成对比 他们还将该方法与 SEINE 和 SparseCtrl 进行了比较,并使用了包括 LPIPSfirst、LPIPS-frames、CLIPSIM-first 和 CLIPSIM-frames 在内的四个定量指标,如表 2 所示。 更多技术和实验细节请参阅原论文。
 表 1: 一致性图像生成的定量对比结果
表 1: 一致性图像生成的定量对比结果
 表 2: 与目前最先进转场视频生成模型的定量对比
表 2: 与目前最先进转场视频生成模型的定量对比
以上是LeCun上月球?南開、位元組開源StoryDiffusion讓多圖漫畫和長影片更連貫的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 給MySQL表添加和刪除字段的操作步驟
Apr 29, 2025 pm 04:15 PM
給MySQL表添加和刪除字段的操作步驟
Apr 29, 2025 pm 04:15 PM
在MySQL中,添加字段使用ALTERTABLEtable_nameADDCOLUMNnew_columnVARCHAR(255)AFTERexisting_column,刪除字段使用ALTERTABLEtable_nameDROPCOLUMNcolumn_to_drop。添加字段時,需指定位置以優化查詢性能和數據結構;刪除字段前需確認操作不可逆;使用在線DDL、備份數據、測試環境和低負載時間段修改表結構是性能優化和最佳實踐。
 數字虛擬幣交易平台top10 安全可靠的十大數字貨幣交易所
Apr 30, 2025 pm 04:30 PM
數字虛擬幣交易平台top10 安全可靠的十大數字貨幣交易所
Apr 30, 2025 pm 04:30 PM
數字虛擬幣交易平台top10分別是:1. Binance,2. OKX,3. Coinbase,4. Kraken,5. Huobi Global,6. Bitfinex,7. KuCoin,8. Gemini,9. Bitstamp,10. Bittrex,這些平台均提供高安全性和多種交易選項,適用於不同用戶需求。
 量化交易所排行榜2025 數字貨幣量化交易APP前十名推薦
Apr 30, 2025 pm 07:24 PM
量化交易所排行榜2025 數字貨幣量化交易APP前十名推薦
Apr 30, 2025 pm 07:24 PM
交易所內置量化工具包括:1. Binance(幣安):提供Binance Futures量化模塊,低手續費,支持AI輔助交易。 2. OKX(歐易):支持多賬戶管理和智能訂單路由,提供機構級風控。獨立量化策略平台有:3. 3Commas:拖拽式策略生成器,適用於多平台對沖套利。 4. Quadency:專業級算法策略庫,支持自定義風險閾值。 5. Pionex:內置16 預設策略,低交易手續費。垂直領域工具包括:6. Cryptohopper:雲端量化平台,支持150 技術指標。 7. Bitsgap:
 deepseek官網是如何實現鼠標滾動事件穿透效果的?
Apr 30, 2025 pm 03:21 PM
deepseek官網是如何實現鼠標滾動事件穿透效果的?
Apr 30, 2025 pm 03:21 PM
如何實現鼠標滾動事件穿透效果?在我們瀏覽網頁時,經常會遇到一些特別的交互設計。比如在deepseek官網上,�...
 Laravel 最佳擴展包推薦:2024 年必備工具
Apr 30, 2025 pm 02:18 PM
Laravel 最佳擴展包推薦:2024 年必備工具
Apr 30, 2025 pm 02:18 PM
2024年必備的Laravel擴展包包括:1.LaravelDebugbar,用於監控和調試代碼;2.LaravelTelescope,提供詳細的應用監控;3.LaravelHorizon,管理Redis隊列任務。這些擴展包能提升開發效率和應用性能。
 MySQL批量插入數據的高效方法
Apr 29, 2025 pm 04:18 PM
MySQL批量插入數據的高效方法
Apr 29, 2025 pm 04:18 PM
MySQL批量插入数据的高效方法包括:1.使用INSERTINTO...VALUES语法,2.利用LOADDATAINFILE命令,3.使用事务处理,4.调整批量大小,5.禁用索引,6.使用INSERTIGNORE或INSERT...ONDUPLICATEKEYUPDATE,这些方法能显著提升数据库操作效率。
 如何使用MySQL的函數進行數據處理和計算
Apr 29, 2025 pm 04:21 PM
如何使用MySQL的函數進行數據處理和計算
Apr 29, 2025 pm 04:21 PM
MySQL函數可用於數據處理和計算。 1.基本用法包括字符串處理、日期計算和數學運算。 2.高級用法涉及結合多個函數實現複雜操作。 3.性能優化需避免在WHERE子句中使用函數,並使用GROUPBY和臨時表。
 輕鬆協議(Easeprotocol.com)將ISO 20022消息標准直接實現為區塊鏈智能合約
Apr 30, 2025 pm 05:06 PM
輕鬆協議(Easeprotocol.com)將ISO 20022消息標准直接實現為區塊鏈智能合約
Apr 30, 2025 pm 05:06 PM
這種開創性的開發將使金融機構能夠利用全球認可的ISO20022標準來自動化不同區塊鏈生態系統的銀行業務流程。 Ease協議是一個企業級區塊鏈平台,旨在通過易用的方式促進廣泛採用,今日宣布已成功集成ISO20022消息傳遞標準,直接將其納入區塊鏈智能合約。這一開發將使金融機構能夠使用全球認可的ISO20022標準,輕鬆自動化不同區塊鏈生態系統的銀行業務流程,該標準正在取代Swift消息傳遞系統。這些功能將很快在“EaseTestnet”上進行試用。 EaseProtocolArchitectDou
