

58行程式碼把Llama 3擴展到100萬上下文,任何微調版都適用

堂堂開源之王Llama 3,原版上下文視窗居然只有…8k,讓到嘴邊的一句「真香」又吞回去了。
在32k起步,100k尋常的今天,這是故意要給開源社群留有貢獻的空間嗎?
開源社群當然不會放過這個機會:
現在只需58行程式碼,任何Llama 3 70b的微調版本都能自動擴展到1048k(一百萬)上下文。
背後是一個LoRA,從擴展好上下文的Llama 3 70B Instruct微調版本中提取出來,檔案只有800mb 。
接下來使用Mergekit,就可以與其他同架構模型一起運作或直接合併到模型中。
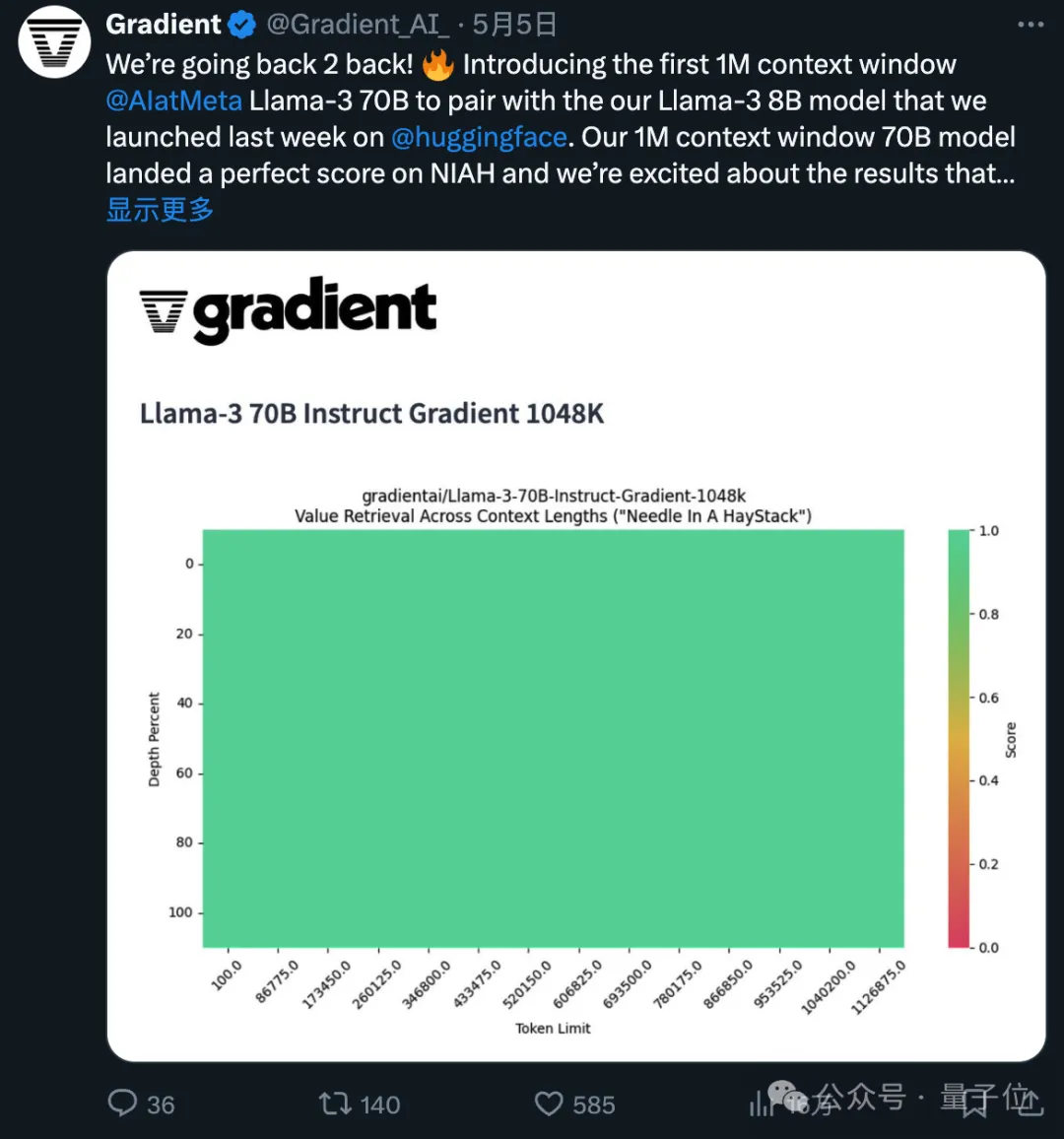
所使用的1048k上下文微調版本,剛剛在流行的大海撈針測試中達到全綠(100%準確率)的成績。
不得不說,開源的進步速度是指數級的。
1048k上下文LoRA怎麼煉成的
首先1048k上下文版Llama 3微調模型來自Gradient AI #,一家企業AI解決方案新創公司。

而對應的LoRA來自開發者Eric Hartford,透過比較微調模型與原版的差異,提取出參數的變化。
他先製作了524k上下文版,隨後又更新了1048k版本。
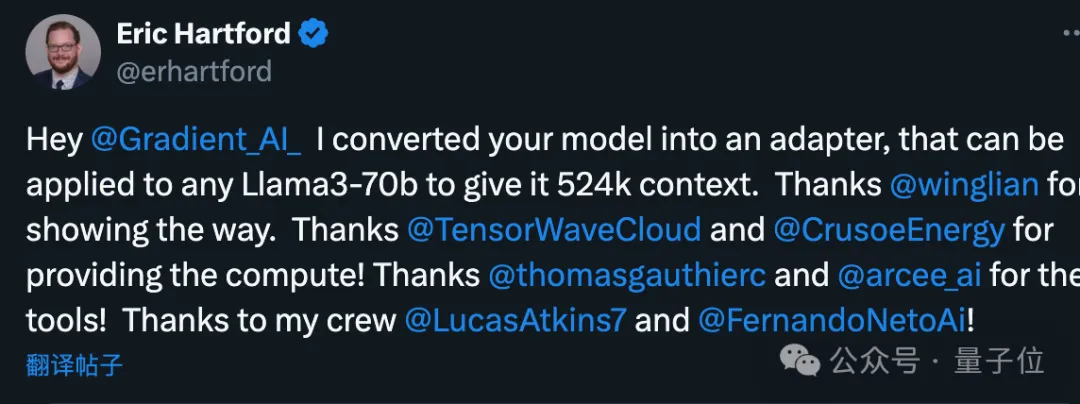
首先,Gradient團隊先在原版Llama 3 70B Instruct的基礎上繼續訓練,得到Llama-3-70B-Instruct-Gradient-1048k。
具體方法如下:
- 調整位置編碼:用NTK-aware內插初始化RoPE theta的最佳調度,進行最佳化,防止擴展長度後丟失高頻資訊
- 漸進式訓練:使用UC伯克利Pieter Abbeel團隊提出的Blockwise RingAttention方法擴展模型的上下文長度
值得注意的是,團隊透過自訂網路拓撲在Ring Attention之上分層並行化,更好地利用大型GPU叢集來應對設備之間傳遞許多KV blocks帶來的網路瓶頸。
最終讓模型的訓練速度提高了33倍。
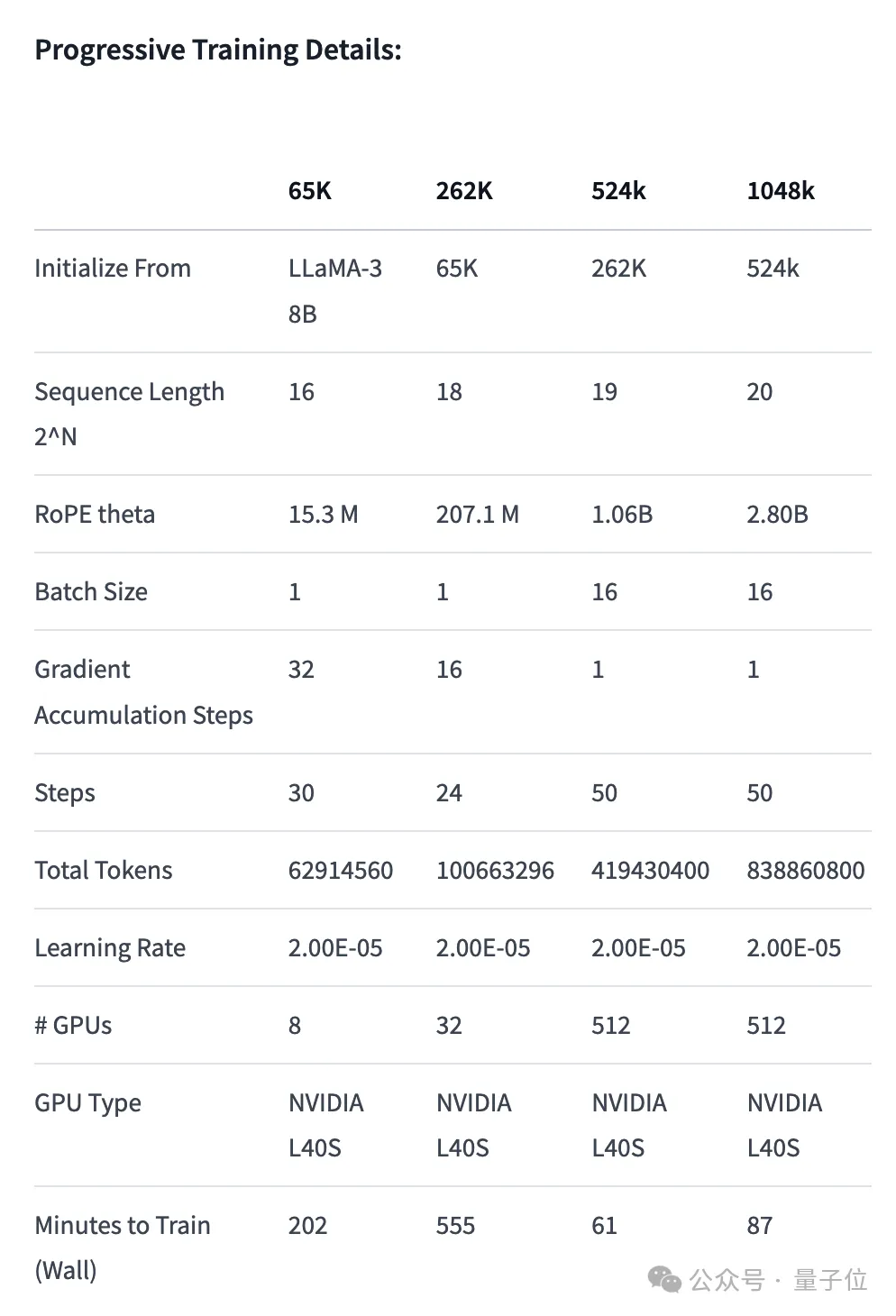
長文本檢索效能評估中,只在最難的版本中,當「針」藏在文字中間部分時容易出錯。

有了擴展好上下文的微調模型之後,使用開源工具Mergekit比較微調模型和基礎模型,提取參數的差異成為LoRA。
同樣使用Mergekit,就可以把提取好的LoRA合併到其他同架構模型中了。
合併程式碼也由Eric Hartford開源在GitHub上,只有58行。
目前尚不清楚這種LoRA合併是否適用於在中文上微調的Llama 3。
不過可以看到,中文開發者社群已經關注到了這項進展。
524k版本LoRA:https://huggingface.co/cognitivecomputations/Llama-3-70B-Gradient-524k-adapter
1048k版本LoRA:https://huggingface.co/cognitivecomputations/Llama-3-70B-Gradient-1048k-adapter
#合併程式碼:https://gist.github.com/ehartford/731e3f7079db234fa1b79a01e09859ac
以上是58行程式碼把Llama 3擴展到100萬上下文,任何微調版都適用的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 無需OpenAI數據,躋身程式碼大模型榜單! UIUC發表StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
無需OpenAI數據,躋身程式碼大模型榜單! UIUC發表StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
無需OpenAI數據,躋身程式碼大模型榜單! UIUC發表StarCoder-15B-Instruct

 70B模型秒出1000token,程式碼重寫超越GPT-4o,來自OpenAI投資的程式碼神器Cursor團隊
Jun 13, 2024 pm 03:47 PM
70B模型秒出1000token,程式碼重寫超越GPT-4o,來自OpenAI投資的程式碼神器Cursor團隊
Jun 13, 2024 pm 03:47 PM
70B模型秒出1000token,程式碼重寫超越GPT-4o,來自OpenAI投資的程式碼神器Cursor團隊



 GoogleGemini 1.5技術報告:輕鬆證明奧數題,Flash版比GPT-4 Turbo快5倍
Jun 13, 2024 pm 01:52 PM
GoogleGemini 1.5技術報告:輕鬆證明奧數題,Flash版比GPT-4 Turbo快5倍
Jun 13, 2024 pm 01:52 PM
GoogleGemini 1.5技術報告:輕鬆證明奧數題,Flash版比GPT-4 Turbo快5倍

