
近年來,自動駕駛因其在減輕駕駛員負擔和提高駕駛安全方面的潛力而越來越受到關注。基於視覺的三維佔用預測是一種新興的感知任務,適用於具有成本效益且對自動駕駛安全全面調查的任務。儘管許多研究已經證明,與基於物體為中心的感知任務相比,3D佔用預測工具具有更大的優勢,但仍存在專門針對這一快速發展領域的綜述。本文首先介紹了基於視覺的3D佔用預測的背景,並討論了這項任務中遇到的挑戰。接下來,我們從特徵增強、部署友善性和標籤效率三個面向全面探討了目前3D佔用預測方法的現況和發展趨勢。最後,總結了目前研究的趨勢,並提出了一些鼓舞人心的未來展望。
開源連結:https://github.com/zya3d/Awesome-3D-Occupancy-Prediction
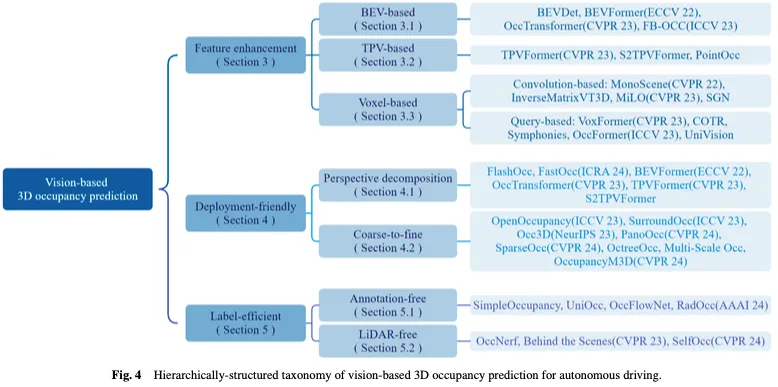
總結來說,本文的主要貢獻如下:
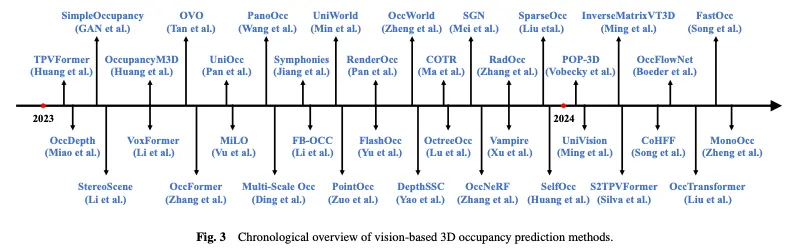
圖3顯示了基於視覺的3D佔用預測方法的時序概述,圖4顯示了相應的分層結構分類法。
#產生GT標籤是3D佔用預測的一種挑戰。儘管許多3D感知資料集,如nuScenes和Waymo,提供了雷射雷達點雲分割標籤,但這些標籤是稀疏的,難以監督密集的3D佔用預測任務。 Wei等人已經證明了使用密集佔用作為GT標籤的重要性。最近的一些研究集中在使用稀疏雷射雷達點雲分割註釋產生密集佔用標籤,為3D佔用預測任務提供一些有用的資料集和基準。
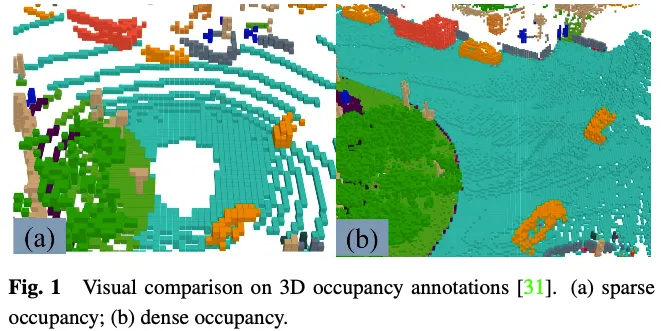
在3D佔用預測任務中的GT標籤表示3D空間中的每個元素是否被佔用以及被佔用元素的語意標籤。由於三維空間中有大量的元素,因此很難手動標記每個元素。常見的做法是對現有的3D點雲分割任務的地面實況進行體素化,然後根據體素中點的語義標籤透過投票產生3D佔用預測的GT。然而,透過這種方式產生的地面實況實際上是簡化的。如圖1所示,在道路等未標記為已佔用的地方,仍存在許多已佔用的元素。監督工具有這種簡化地形實況的模型將導致模型性能下降。因此,一些工作如何自動或半自動產生高品質的密集3D佔用註解。
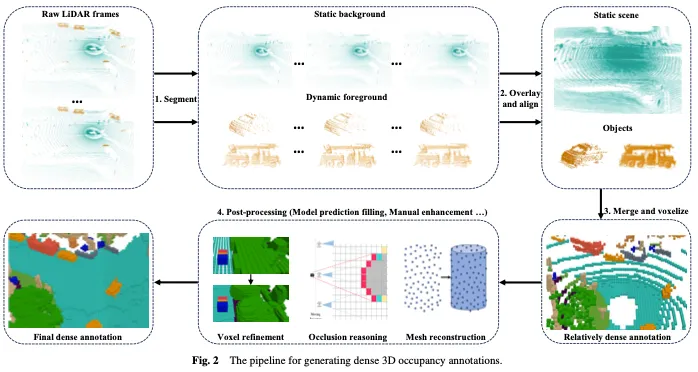
如圖2所示,產生密集的三維佔用註解通常包括以下四個步驟:
在本小節中,我們介紹了一些常用於3D佔用預測的開源、大規模資料集,表1給出了它們之間的比較。
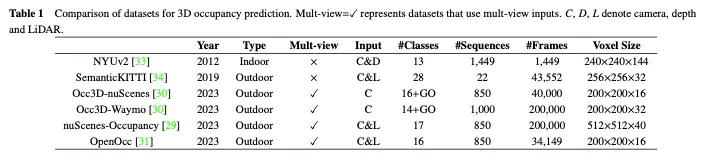
NUYv2資料集由來自各種室內場景的影片序列組成,由Microsoft Kinect的RGB和Depth相機拍攝。它包含1449對密集標記的對齊RGB和深度圖像,以及來自3個城市的407024個未標記幀。雖然主要用於室內使用,不適合自動駕駛場景,但一些研究已將該資料集用於3D佔用預測。
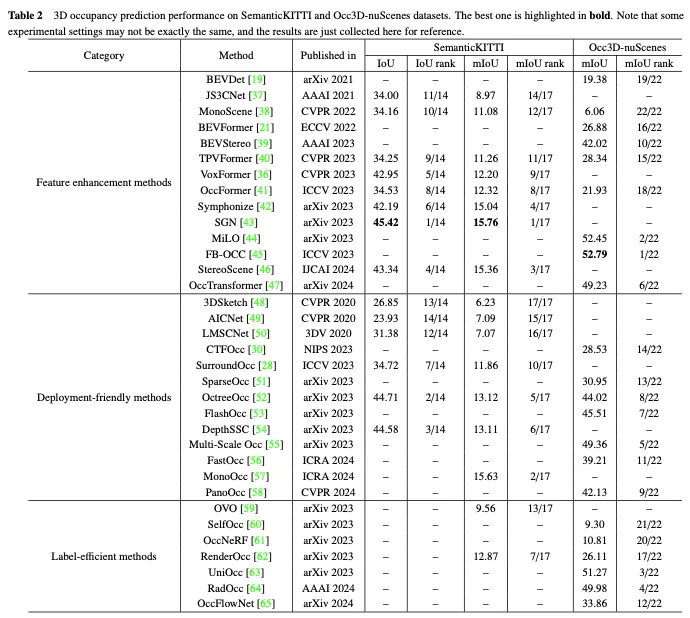
SemanticKITTI是一個廣泛用於3D佔用預測的資料集,包括來自KITTI資料集的22個序列和43000多個幀。它透過覆蓋未來的幀、分割體素和透過點投票分配標籤來創建密集的3D佔用註釋。此外,它透過追蹤光線來檢查汽車的每個位姿,感測器可以看到哪些體素,並在訓練和評估過程中忽略不可見的體素。然而,由於它是基於KITTI資料集的,因此它只使用來自前置相機的影像作為輸入,而後續資料集通常使用多視圖影像。如表2所示,我們在SemanticKITTI資料集上收集了現有方法的評估結果。
NuScenes佔用率是基於戶外環境的大規模自動駕駛資料集NuScenes建構的3D佔用率預測資料集。它包含850個序列、200000個幀和17個語義類別。資料集最初使用增強和淨化(AAP)管道產生粗略的3D佔用標籤,然後透過手動增強來細化標籤。此外,它還引入了OpenOccupancy,這是周圍語義佔用感知的第一個基準,以評估先進的3D佔用預測方法。
隨後,Tian等人在nuScenes和Waymo自動駕駛資料集的基礎上,進一步建構了用於3D佔用預測的Occ3D nuScene斯和Occ3D Waymo資料集。他們引入了一種半自動標籤生成管道,該管道利用現有的標記3D感知資料集,並根據其可見性識別體素類型。此外,他們還建立了大規模3D佔用預測的Occ3d基準,以加強不同方法的評估和比較。如表2所示,我們在Occ3D nuScenes資料集上收集了現有方法的評估結果。
此外,與Occ3D裸體和裸體佔用類似,OpenOcc也是基於裸體資料集為3D佔用預測所建構的資料集。它包含850個序列、34149個幀和16個類別。請注意,該資料集提供了八個前景目標的額外註釋,這有助於下游任務,例如運動規劃。
儘管近年來基於視覺的三維佔用預測取得了重大進展,但它仍然面臨著來自特徵表示、實際應用和註釋成本的限制。對於這項任務,有三個關鍵挑戰:(1)從2D視覺輸入中獲得完美的3D特徵是困難的。基於視覺的3D佔有率預測的目標是僅從影像輸入實現對3D場景的詳細感知和理解,然而影像中固有的深度和幾何資訊的缺失對直接從中學習3D特徵表示提出了重大挑戰。 (2)三維空間中繁重的計算負載。 3D佔用預測通常需要使用3D體素特徵來表示環境空間,這不可避免地涉及用於特徵提取的3D卷積等操作,這大大增加了計算和記憶體開銷,並阻礙了實際部署。 (3)昂貴的細粒度註釋。 3D佔用預測涉及預測高分辨率體素的佔用狀態和語義類別,但實現這一點通常需要對每個體素進行細粒度的語義註釋,這既耗時又昂貴,給這項任務帶來了瓶頸。
針對這些關鍵挑戰,基於視覺的自動駕駛三維佔用預測研究工作逐步形成了特徵增強、部署友好和標籤高效三條主線。特徵增強方法透過優化網路的特徵表示能力來緩解3D空間輸出和2D空間輸入之間的差異。部署友善的方法旨在透過設計簡潔高效的網路架構,大幅降低資源消耗,同時確保效能。即使在註釋不足或完全不存在的情況下,高效標籤方法也有望實現令人滿意的性能。接下來,我們將圍繞這三個分支全面概述目前的方法。
基於視覺的3D佔用預測的任務涉及從2D圖像空間預測3D體素空間的佔用狀態和語義訊息,這對從2D視覺輸入獲得完美的3D特徵提出了關鍵挑戰。為了解決這個問題,一些方法從特徵增強的角度改進了佔用預測,包括從鳥瞰圖(BEV)、三視角圖(TPV)和三維體素表示中學習。
一種有效的學習佔用率的方法是基於鳥瞰圖(BEV),它提供了對遮蔽不敏感的特徵,並包含一定的深度幾何資訊。透過學習強BEV表示,可以實現穩健的3D佔用場景重建。首先使用2D骨幹網路從視覺輸入中擷取影像特徵,然後透過視點變換獲得BEV特徵,並最終基於BEV特徵表示完成3D佔用預測。基於BEV的方法如圖5所示。
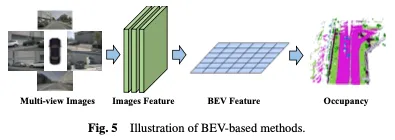
一種直接的方法是利用來自其他任務的BEV學習,例如在3D物件偵測中使用BEVDet和BEVFormer等方法。為了擴展這些佔用學習方法,可以在訓練過程中加入或更換佔用頭,以獲得最終結果。這種自適應允許將佔用估計整合到現有的基於BEV的框架中,從而能夠同時偵測和重建場景中的3D佔用。基於強大的基線BEVFormer,OccTransformer採用資料增強來增加訓練資料的多樣性,以提高模型泛化能力,並利用強大的影像主幹從輸入資料中提取更多資訊特徵。它還引入了3D Unet Head,以更好地捕捉場景的空間訊息,並引入了額外的損失函數來改進模型最佳化。
#雖然與影像相比,基於BEV的表示具有某些優勢,因為它們本質上提供了3D空間的自上而下的投影,但它們固有地缺乏僅使用單一平面來描述場景的細粒度3D結構的能力。基於三個視角(TPV)的方法利用三個正交投影平面對3D環境進行建模,進一步增強了視覺特徵對佔用預測的表示能力。首先,使用2D骨幹網路從視覺輸入中擷取影像特徵。隨後,將這些影像特徵提升到三視圖空間,最終基於三個投影視點的特徵表示實現3D佔用預測。基於BEV的方法如圖7所示。
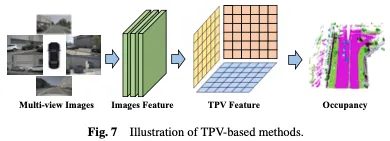
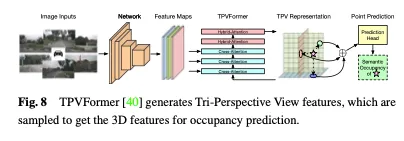
除了BEV功能外,TPVFormer還以相同的方式產生前視圖和側視圖中的功能。每個平面從不同的視角對3D環境進行建模,並且它們的組合提供了整個3D結構的全面描述。具體來說,為了獲得三維空間中一個點的特徵,我們首先將其投影到三個平面中的每一個平面上,並使用雙線性插值來獲得每個投影點的特徵。然後,我們將三個投影特徵總結為三維點的合成特徵。因此,TPV表示可以以任意解析度描述3D場景,並為3D空間中的不同點產生不同的特徵。它進一步提出了一種基於變換器的編碼器(TPVFormer),以有效地從2D圖像中獲得TPV特徵,並在TPV網格查詢和相應的2D圖像特徵之間執行圖像交叉關注,從而將2D信息提升到3D空間。最後,TPV特徵之間的交叉視圖混合注意力實現了三個平面之間的交互作用。 TPVFormer的整體架構如圖8所示。
除了將3D空間轉換為投影透視(如BEV或TPV)之外,還存在直接對3D體素表示進行操作的方法。這些方法的關鍵優勢是能夠直接從原始3D空間學習,最大限度地減少資訊損失。透過利用原始三維體素數據,這些方法可以有效地捕捉和利用完整的空間訊息,從而更準確、更全面地了解佔用情況。首先,使用2D骨幹網路擷取影像特徵,然後,使用專門設計的基於卷積的機制來橋接2D和3D表示,或使用基於查詢的方法來直接獲得3D表示。最後,基於所學習的3D表示,使用3D佔用頭來完成最終預測。基於體素的方法如圖9所示。
Convolution-based methods
#一種方法是利用專門設計的捲積架構來彌合從2D到3D的差距,並學習3D佔用表示。這種方法的一個突出例子是採用U-Net架構作為特徵橋接的載體。 U-Net架構採用編碼器-解碼器結構,在上採樣和下採樣路徑之間具有跳躍連接,保留低級別和高級別特徵資訊以減輕資訊損失。透過不同深度的捲積層,U-Net結構可以提取不同尺度的特徵,幫助模型捕捉影像中的局部細節和全局上下文訊息,從而增強模型對複雜場景的理解,從而進行有效的佔用預測。
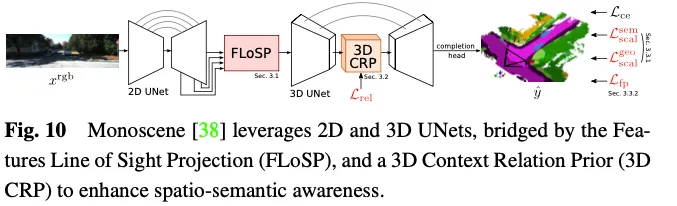
Monoscene利用U-net進行基於視覺的3D佔用預測。它引入了一種稱為二維特徵視線投影(FLoSP)的機制,該機制利用特徵透視投影將二維特徵投影到三維空間上,並根據成像原理和相機參數計算二維特徵上三維特徵空間中每個點的座標,以對三維特徵空間的特徵進行取樣。這種方法將2D特徵提升到統一的3D特徵圖中,並作為連接2D和3D U-net的關鍵元件。 Monoscene也提出了一個插入在3D UNet瓶頸處的3D上下文關係先驗(3D CRP)層,該層學習n向體素到體素的語義場景關係圖。這為網絡提供了一個全局感受場,並由於關係發現機製而提高了空間語義意識。 Monoscene的整體架構如圖10所示。
Query-based methods
從3D空間學習的另一種方式涉及產生一組查詢以捕捉場景的表示。在該方法中,使用基於查詢的技術來產生查詢建議,然後將其用於學習3D場景的綜合表示。隨後,應用影像上的交叉注意和自註意機制來細化和增強所學習的表徵。這種方法不僅增強了對場景的理解,而且能夠在3D空間中進行準確的重建和佔用預測。此外,基於查詢的方法提供了更大的靈活性來基於不同的資料來源和查詢策略進行調整和最佳化,從而能夠更好地捕獲本地和全局上下文信息,從而促進3D佔用預測表示。
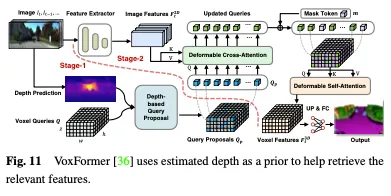
深度可以作為選擇佔用查詢的有價值的先驗,在Voxformer中,估計的深度被用作預測佔用和選擇相關查詢的先驗。只有佔用的查詢用於使用可變形注意力從圖像中收集資訊。更新後的查詢提議和掩蔽的令牌然後被組合以重建體素特徵。 Voxformer從RGB影像中提取2D特徵,然後利用一組稀疏的3D體素查詢來索引這些2D特徵,使用相機投影矩陣將3D位置連結到影像流。具體而言,體素查詢是3D網格形狀的可學習參數,旨在使用注意力機制將影像中的特徵查詢到3D體積中。整個框架是由類不可知的提議和特定於類別的分段組成的兩階段級聯。階段1產生類不可知的查詢建議,而階段2採用類似MAE的架構將資訊傳播到所有體素。最後,對體素特徵進行上採樣以進行語義分割。 VoxFormer的整體架構如圖11所示。
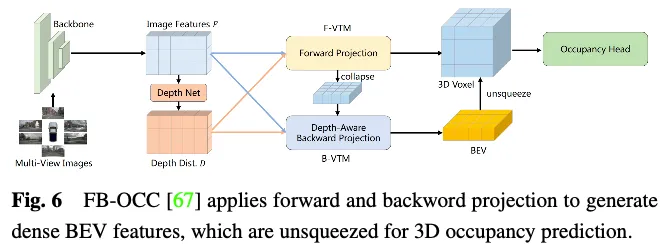
Occ3D nuScenes資料集上特徵增強方法的效能比較如表3所示。結果表明,直接處理體素表示的方法通常能夠實現強大的性能,因為它們在計算過程中不會遭受顯著的資訊損失。此外,儘管基於BEV的方法只有一個投影視點用於特徵表示,但由於鳥瞰圖中包含的豐富資訊以及它們對遮蔽和比例變化的不敏感性,它們仍然可以實現可比較的性能。此外,透過從多個互補視圖重建3D訊息,基於三視角視圖(TPV)的方法能夠減輕潛在的幾何模糊性,並捕捉更全面的場景背景,從而實現有效的3D佔用預測。值得注意的是,FB-OCC同時利用了前向和後向視圖轉換模組,使它們能夠相互增強,以獲得更高品質的純電動車表示,並取得了優異的性能。這表明,透過有效的特徵增強,基於BEV的方法在改善3D佔用預測方面也有很大的潛力。
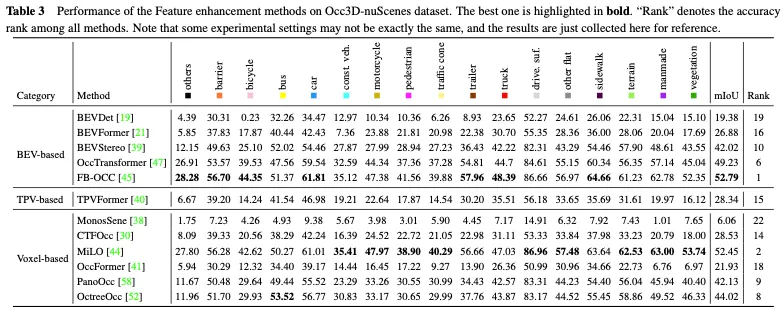
由於其廣泛的範圍和複雜的資料性質,直接從3D空間學習佔用表示是極具挑戰性的。與3D體素表示相關的高維度和密集的計算使得學習過程對資源的要求很高,這不利於實際部署應用。因此,設計部署友善的3D表示的方法旨在降低計算成本並提高學習效率。本節介紹了解決3D場景佔用估計中計算挑戰的方法,重點是開發準確且高效的方法,而不是直接處理整個3D空間。所討論的技術包括透視分解和從粗到細的細化,這些技術已在最近的工作中得到證明,以提高3D佔用預測的計算效率。
透過將視點資訊從3D場景特徵中分離出來或將其投影到統一的表示空間中,可以有效地降低計算複雜度,使模型更加穩健和可推廣。這種方法的核心思想是將三維場景的表示與視點資訊解耦,從而減少特徵學習過程中需要考慮的變數數量,並降低計算複雜度。解耦視點資訊使模型能夠更好地泛化,適應不同的視點變換,而無需重新學習整個模型。
為了解決從整個3D空間學習的計算負擔,一個常見的方法是使用鳥瞰圖(BEV)和三視角圖(TPV)表示。透過將3D空間分解為這些單獨的視圖表示,計算複雜度顯著降低,同時仍可擷取用於佔用預測的基本資訊。關鍵思想是先從BEV和TPV的角度學習,然後透過結合從這些不同視圖中獲得的見解來恢復完整的3D佔用資訊。與直接從整個3D空間學習相比,這種透視分解策略允許更有效率和有效的佔用估計。
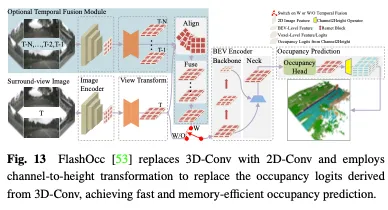
直接從大規模3D空間學習高解析度細粒度全域體素特徵是耗時且具有挑戰性的。因此,一些方法已經開始探索採用從粗到細的特徵學習範式。具體而言,網路最初從圖像中學習粗略的表示,然後細化和恢復整個場景的細粒度表示。這兩步驟過程有助於實現對場景佔用率的更準確和有效的預測。
OpenOccupancy採用兩步驟方法來學習3D空間中的佔用表示。如圖14所示。
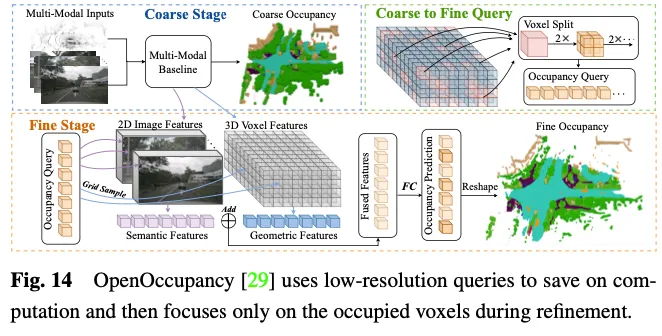
預測3D佔用率需要詳細的幾何表示,並且利用所有3D體素標記與多視圖影像中的ROI進行互動將產生顯著的計算和記憶體成本。如圖15所示,Occ3D提出了一種增量令牌選擇策略,在交叉注意力計算過程中選擇性地選擇前景和不確定的體素令牌,從而在不犧牲精度的情況下實現自適應高效計算。具體地,在每個金字塔層的開始,每個體素標記被輸入到二進制分類器中,以預測體素是否為空,由二進制地面實況佔用圖來監督以訓練分類器。 PanoOcc提出在聯合學習框架內無縫整合物件偵測和語意分割,促進對3D環境的更全面理解。此方法利用體素查詢來聚合來自多幀和多視圖影像的時空訊息,將特徵學習和場景表示合併為統一的佔用表示。此外,它透過引入佔用稀疏性模組來探索3D空間的稀疏性,該模組在從粗到細的上採樣過程中逐漸稀疏佔用,顯著提高了儲存效率。
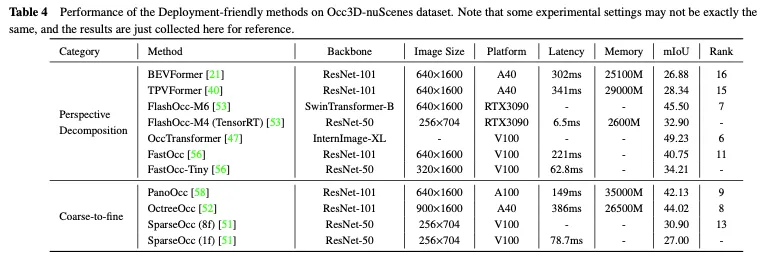
Occ3D nuScenes資料集上部署友善方法的效能比較如表4所示。由於結果是從不同的論文中收集的,在主幹、圖像大小和計算平台方面存在差異,因此只能得出一些初步結論。通常,在類似的實驗設定下,由於資訊遺失較少,從粗到細的方法在性能方面優於透視分解方法,而透視分解通常表現出更好的即時性能和更低的記憶體使用率。此外,採用較重主幹和處理較大影像的模型可以獲得更好的精度,但也會削弱即時效能。儘管FlashOcc和FastOcc等方法的輕量級版本已經接近實際部署的要求,但它們的準確性仍需要進一步提高。對於部署友善的方法,透視分解策略和從粗到細策略都致力於在保持3D佔用預測準確性的同時,不斷減少計算負載。
在现有的创建精确占用标签的方法中,有两个基本步骤。第一个是收集与多视图图像相对应的激光雷达点云,并进行语义分割注释。另一种是利用动态物体的跟踪信息,通过复杂的算法融合多帧点云。这两个步骤都相当昂贵,这限制了占用网络利用自动驾驶场景中大量多视图图像的能力。近年来,神经辐射场(Nerf)在二维图像绘制中得到了广泛的应用。有几种方法以类似Nerf的方式将预测的三维占用绘制成二维地图,并在没有细粒度标注或激光雷达点云参与的情况下训练占用网络,这显著降低了数据标注的成本。
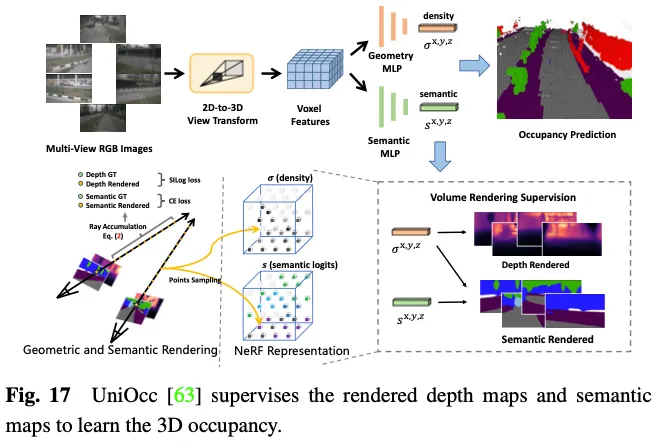
SimpleOccupancy首先通过视图变换从图像特征中生成场景的显式3D体素特征,然后按照Nerf风格的方式将其渲染为2D深度图。二维深度图由激光雷达点云生成的稀疏深度图监督。深度图还用于合成用于自我监督的环绕图像。UniOcc使用两个单独的MLP将3D体素logits转换为体素的密度和体素的语义logits。之后,UniOCC按照一般的体积渲染来获得多视图深度图和语义图,如图17所示。这些2D地图由分割的LiDAR点云生成的标签进行监督。RenderOcc从多视图图像中构建类似于NeRF的3D体积表示,并使用先进的体积渲染技术来生成2D渲染,该技术可以仅使用2D语义和深度标签来提供直接的3D监督。通过这种2D渲染监督,该模型通过分析来自各种相机截头体的光线交点来学习多视图一致性,从而更深入地了解3D空间中的几何关系。此外,它引入了辅助光线的概念,以利用来自相邻帧的光线来增强当前帧的多视图一致性约束,并开发了一种动态采样训练策略来过滤未对准的光线。为了解决动态和静态类别之间的不平衡问题,OccFlowNet进一步引入了占用流,基于3D边界框预测每个动态体素的场景流。使用体素流,可以将动态体素移动到时间帧中的正确位置,从而无需在渲染过程中进行动态对象过滤。在训练过程中,使用流对正确预测的体素和边界框内的体素进行转换,以与时间帧中目标位置对齐,然后使用基于距离的加权插值进行网格对齐。
上述方法消除了对显式3D占用注释的需要,大大减少了手动注释的负担。然而,他们仍然依赖激光雷达点云来提供深度或语义标签来监督渲染的地图,这还不能实现3D占用预测的完全自监督框架。
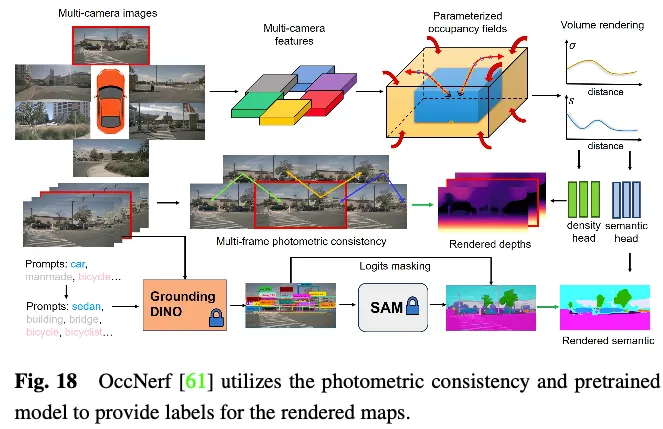
OccNerf不利用激光雷达点云来提供深度和语义标签。相反,如图18所示,它使用参数化占用字段来处理无边界的室外场景,重新组织采样策略,并使用体积渲染将占用字段转换为多相机深度图,最终通过多帧光度一致性进行监督。此外,该方法利用预先训练的开放词汇语义分割模型来生成2D语义标签,监督该模型将语义信息传递给占用字段。幕后使用单一视图图像序列来重建驾驶场景。它将输入图像的截头体特征视为密度场,并渲染其他视图的合成。通过专门设计的图像重建损失来训练整个模型。SelfOcc预测BEV或TPV特征的带符号距离场值,以渲染2D深度图。此外,原始颜色和语义图也由多视图图像序列生成的标签进行渲染和监督。
这些方法避开了对来自激光雷达点云的深度或语义标签的必要性。相反,他们利用图像数据或预训练的模型来获得这些标签,从而实现3D占用预测的真正的自监督框架。尽管这些方法可以实现最符合实际应用经验的训练模式,但仍需进一步探索才能获得令人满意的性能。
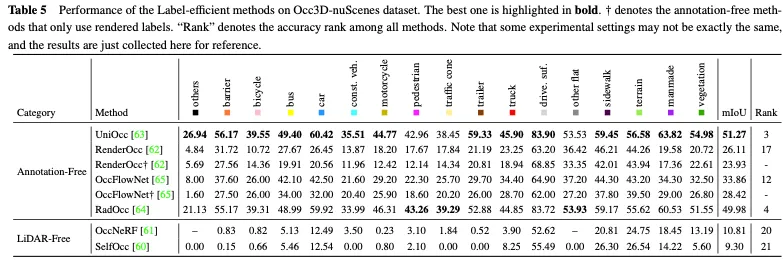
表5显示了Occ3D nuScenes数据集上标签高效方法的性能比较。大多数无注释方法使用2D渲染监督作为显式3D占用监督的补充,并获得了一定的性能改进。其中,UniOcc和RadOcc甚至在所有方法中分别获得了3和4的优异排名,充分证明了无注释机制可以促进额外有价值信息的提取。当仅采用2D渲染监督时,它们仍然可以实现相当的精度,说明了节省显式3D占用注释成本的可行性。无激光雷达的方法为3D占用预测建立了一个全面的自我监督框架,进一步消除了对标签和激光雷达数据的需求。然而,由于点云本身缺乏精确的深度和几何信息,其性能受到极大限制。
在上述方法的推动下,我们总结了当前的趋势,并提出了几个重要的研究方向,这些方向有可能从数据、方法和任务的角度显著推进基于视觉的自动驾驶3D占用预测领域。
获取充足的真实驾驶数据对于提高自动驾驶感知系统的整体能力至关重要。数据生成是一种很有前途的途径,因为它不会产生任何获取成本,并提供了根据需要操纵数据多样性的灵活性。虽然一些方法利用文本等提示来控制生成的驾驶数据的内容,但它们不能保证空间信息的准确性。相比之下,3D Occupancy提供了场景的细粒度和可操作的表示,与点云、多视图图像和BEV布局相比,有助于可控的数据生成和空间信息显示。WoVoGen提出了体积感知扩散,可以将3D占用映射到逼真的多视图图像。在对3D占用进行修改后,例如添加一棵树或更换一辆汽车,扩散模型将合成相应的新驾驶场景。修改后的三维占用记录了三维位置信息,保证了合成数据的真实性。
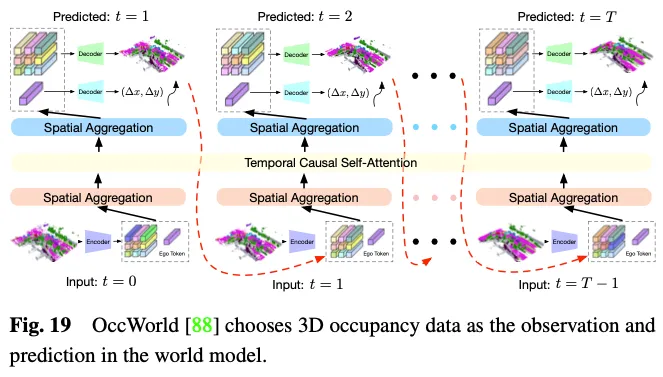
自动驾驶的世界模型越来越突出,它提供了一个简单而优雅的框架,增强了模型基于环境输入观测来理解整个场景并直接输出合适的动态场景演化数据的能力。鉴于其能够熟练地详细表示整个驾驶场景数据,利用3D占用率作为世界模型中的环境观测具有明显的优势。如图19所示,OccWorld选择3D占用率作为世界模型的输入,并使用类似GPT的模块来预测未来的3D占用率数据应该是什么样子。UniWorld利用了现成的基于BEV的3D occ-pancy模型,但通过处理过去的多视图图像来预测未来的3D占用数据,这也构建了一个世界模型。然而,无论机制如何,生成的数据和真实数据之间不可避免地存在领域差距。为了解决这个问题,一种可行的方法是将3D占用预测与新兴的3D人工智能生成内容(3D AIGC)方法相结合,以生成更真实的场景数据,而另一种方法是将领域自适应方法相结合以缩小领域差距。
当涉及到3D占用预测方法时,在我们之前概述的类别中,存在着需要进一步关注的持续挑战:功能增强方法、部署友好方法和标签高效方法。特征增强方法需要朝着显著提高性能的方向发展,同时保持可控的计算资源消耗。部署友好的方法应该记住,减少内存使用和延迟,同时确保将性能下降降至最低。标签高效的方法应该朝着减少昂贵的注释需求的方向发展,同时实现令人满意的性能。最终目标可能是实现一个统一的框架,该框架结合了功能增强、部署友好性和标签效率,以满足实际自动驾驶应用的期望。
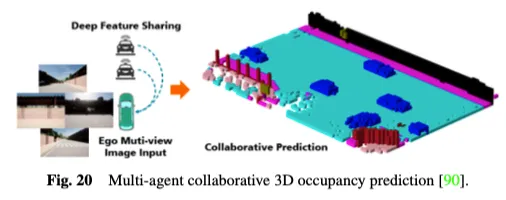
此外,现有的单智能体自动驾驶感知系统天生无法解决关键问题,如对遮挡的敏感性、远程感知能力不足和视野有限,这使得实现全面的环境意识具有挑战性。为了克服单智能体的瓶颈,多智能体协同感知方法开辟了一个新的维度,允许车辆与其他交通元素共享互补信息,以获得对周围环境的整体感知。如图20所示,多智能体协同3D占用预测方法利用协同感知和学习的力量进行3D占用预测,通过在连接的自动化车辆之间共享特征,能够更深入地了解3D道路环境。CoHFF是第一个基于视觉的协作语义占用预测框架,它通过语义和occupancy任务特征的混合融合,以及车辆之间共享的压缩正交注意力特征,改进了局部3D语义占用预测,在性能上显著优于单车系统。然而,这种方法往往需要同时与多个代理进行通信,面临准确性和带宽之间的矛盾。因此,确定哪些代理最需要协调,以及确定最有价值的协作领域,以实现准确性和速度之间的最佳平衡,是一个有趣的研究方向。
在当前的3D占用基准中,某些类别具有明确的语义,如“汽车”、“行人”和“卡车”。相反,“人造”和“植被”等其他类别的语义往往是模糊和笼统的。这些类别包含了广泛的未定义语义,应该细分为更细粒度的类别,以提供驾驶场景的详细描述。此外,对于以前从未见过的未知类别,它们通常被视为一般障碍,无法根据人类提示灵活扩展新的类别感知。对于这个问题,开放词汇任务在2D图像感知方面表现出了强大的性能,并且可以扩展到改进3D占用预测任务。OVO提出了一个支持开放词汇表3D占用预测的框架。它利用冻结的2D分割器和文本编码器来获得开放词汇的语义参考。然后,采用三个不同级别的比对来提取3D占用模型,使其能够进行开放词汇预测。POP-3D设计了一个自监督框架,在强大的预训练视觉语言模型的帮助下,结合了三种模式。它方便了诸如零样本占用分割和基于文本的3D检索之类的开放式词汇任务。
感知周围环境的动态变化对于自动驾驶中下游任务的安全可靠执行至关重要。虽然3D占用预测可以基于当前观测提供大规模场景的密集占用表示,但它们大多局限于表示当前3D空间,并且不考虑周围物体沿时间轴的未来状态。最近,人们提出了几种方法来进一步考虑时间信息,并引入4D占用预测任务,这在真实的自动驾驶场景中更实用。Cam4Occ首次使用广泛使用的nuScenes数据集为4D占用率预测建立了一个新的基准。该基准包括不同的指标,用于分别评估一般可移动物体(GMO)和一般静态物体(GSO)的占用预测。此外,它还提供了几个基线模型来说明4D占用预测框架的构建。尽管开放词汇3D占用预测任务和4D占用预测任务旨在从不同角度增强开放动态环境中自动驾驶的感知能力,但它们仍然被视为独立的任务进行优化。模块化的基于任务的范式,其中多个模块具有不一致的优化目标,可能导致信息丢失和累积错误。将开集动态占用预测与端到端自动驾驶任务相结合,将原始传感器数据直接映射到控制信号是一个很有前途的研究方向。
以上是一覽Occ與自動駕駛的前世今生!首篇綜述全面總結特徵增強/量產部署/高效標註三大主題的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















