

有什么好的办法解决爬虫中很容易遇到的用 javascript 编写的网页的问题?

用的语言是python。目前想要爬的同花顺股票行情(http://q.10jqka.com.cn/stock/fl/#refCountId=db_5093800d_645,db_509381c1_860),又一次被javascript卡住。因为一页中只显示52条信息,想要看全部的股票数据必须点击下面的页码,是用javascript写的,无法直接用urllib2之类的库处理。试过用webkit(ghost.py)来模拟点击,代码如下:
page, resources = ghost.open('http://q.10jqka.com.cn/stock/fl/#refCountId=db_5093800d_645,db_509381c1_860')
page, resources = ghost.evaluate("document.getElementById('hd').nextSibling.getElementsByTagName('div')[13].getElementsByTagName('a')[7].click();", expect_loading = True)
提示Unable to load requested page, 或是返回的page是None。不知道无法解决。求教是代码哪里错了,应该如何解决?(在百度和google找了很久解决方法,不过有关ghost.py的资料不是太多,没能解决。)
以及,求问是否有更好的办法解决爬动态网页的问题?用webkit模拟好像会减慢爬的速度,不是上策。
回复内容:
Headless Webkit,开源的有 PhantomJS 等。能够解析并运行页面上的脚本以索引动态内容是现代爬虫的重要功能之一。
Google's Crawler Now Understands JavaScript: What Does This Mean For You?
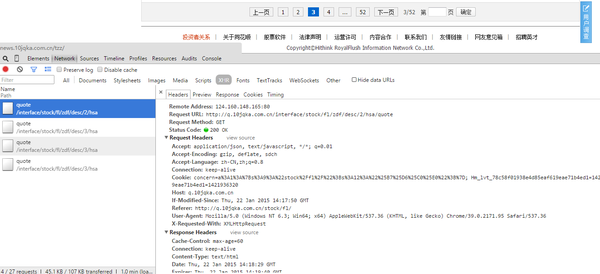

你这个爬虫跟JS关系不大,直接看Network,看发出的网络请求,分析每个URL,找出规律,然后用程序来模拟这样的请求,首先要善于用Chrome的Network功能,我们点几页,看Network如下:
第一页数据URL:
http://q.10jqka.com.cn/interface/stock/fl/zdf/desc/1/hsa/quote
需求:爬取爱漫画上的漫画。
问题:图片的名字命名不规则,通过复杂的js代码生成图片的文件名和url,动态加载图片。js代码的模式多样,没有统一的模式。
解决:Py8v库。读取下js代码,加一个全局变量追踪图片的文件名和url,然后Python和这个变量交互,取得某话图片的文件名和url。
全文在此
【原创】最近写的一个比较hack的小爬虫 能说 berserkJS 么……
不过这种玩意可抗不了量啊
╭(╯ε╰)╮ 嫌麻烦的话直接上selenium吧,几乎百分百地模拟用户在浏览器上的操作。也可以用来爬数据,不过速度较慢。 打开Chrome的开发人员控制台或者火狐的FireBug,转到Network那一栏,直接分析ajax访问的url到底是哪些。
对于特定网站的爬虫就不要想着模拟javascript运行了,太费力而且效果还不好。把网站的url结构弄明白了直接构造表单就好。 Selenium with Python 插一句题外话,同花顺好像可以自定义函数,写脚本计算数据,还是挺方便的,一定要自己把数据全部爬下来吗? phantomjs api比较吐血,建议基于之上封装的casperjs吧,写起来比较爽 一个好的爬虫需要解决两个问题:
1、能够解析动态网页,比如瀑布式网站
2、能够规避网站的封锁

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 ghost win10哪個最好?最好用的win10 ghost版本下載
Feb 12, 2024 pm 11:40 PM
ghost win10哪個最好?最好用的win10 ghost版本下載
Feb 12, 2024 pm 11:40 PM
哪個Win10Ghost純淨版最好相信是很多用戶都在詢問的一個問題,Win10Ghost系統是一款非常實用的系統備份和還原工具,用戶們要是想重裝系統又不想丟失自己的資料和軟體的話就可以使用到Ghost系統,以下就讓本站來為用戶們來仔細的介紹一下Ghostwin10最好用的系統版本下載位址分享吧。 Ghostwin10最好用的系統版本下載在使用Windows作業系統的過程中,有時候我們需要對系統進行重裝或升級,但是又不想遺失自己的資料和軟體,這時候就需要使用Ghost系統了。 Ghost系統可以幫
 ghost安裝器怎麼用 小編教你安裝ghost系統步驟
Jan 11, 2024 pm 07:39 PM
ghost安裝器怎麼用 小編教你安裝ghost系統步驟
Jan 11, 2024 pm 07:39 PM
ghost系統是一種免費的安裝系統,之所以受歡迎,是因為ghost系統安裝後會自動激活,而且自動安裝對應的硬體驅動,不僅節省時間,還給小白用戶提供了便利,不過很多人不知道ghost系統鏡像怎麼安裝,其實安裝步驟很簡單,下面,小編跟大家分享安裝ghost系統步驟。 U盤裝系統越來越流行,現在的啟動盤功能非常強大,既可以自動安裝ghost系統,也可以手動ghost安裝系統,不過由於手動ghost方法比較複雜,很多人都不懂怎麼安裝,讓用戶鬱悶不已,下面,小編為大家帶來了安裝ghost系統步驟。最近小編在
 如何使用WebSocket和JavaScript實現線上語音辨識系統
Dec 17, 2023 pm 02:54 PM
如何使用WebSocket和JavaScript實現線上語音辨識系統
Dec 17, 2023 pm 02:54 PM
如何使用WebSocket和JavaScript實現線上語音辨識系統引言:隨著科技的不斷發展,語音辨識技術已成為了人工智慧領域的重要組成部分。而基於WebSocket和JavaScript實現的線上語音辨識系統,具備了低延遲、即時性和跨平台的特點,成為了廣泛應用的解決方案。本文將介紹如何使用WebSocket和JavaScript來實現線上語音辨識系
 WebSocket與JavaScript:實現即時監控系統的關鍵技術
Dec 17, 2023 pm 05:30 PM
WebSocket與JavaScript:實現即時監控系統的關鍵技術
Dec 17, 2023 pm 05:30 PM
WebSocket與JavaScript:實現即時監控系統的關鍵技術引言:隨著互聯網技術的快速發展,即時監控系統在各個領域中得到了廣泛的應用。而實現即時監控的關鍵技術之一就是WebSocket與JavaScript的結合使用。本文將介紹WebSocket與JavaScript在即時監控系統中的應用,並給出程式碼範例,詳細解釋其實作原理。一、WebSocket技
 如何利用JavaScript和WebSocket實現即時線上點餐系統
Dec 17, 2023 pm 12:09 PM
如何利用JavaScript和WebSocket實現即時線上點餐系統
Dec 17, 2023 pm 12:09 PM
如何利用JavaScript和WebSocket實現即時線上點餐系統介紹:隨著網路的普及和技術的進步,越來越多的餐廳開始提供線上點餐服務。為了實現即時線上點餐系統,我們可以利用JavaScript和WebSocket技術。 WebSocket是一種基於TCP協定的全雙工通訊協議,可實現客戶端與伺服器的即時雙向通訊。在即時線上點餐系統中,當使用者選擇菜餚並下訂單
 如何使用WebSocket和JavaScript實現線上預約系統
Dec 17, 2023 am 09:39 AM
如何使用WebSocket和JavaScript實現線上預約系統
Dec 17, 2023 am 09:39 AM
如何使用WebSocket和JavaScript實現線上預約系統在當今數位化的時代,越來越多的業務和服務都需要提供線上預約功能。而實現一個高效、即時的線上預約系統是至關重要的。本文將介紹如何使用WebSocket和JavaScript來實作一個線上預約系統,並提供具體的程式碼範例。一、什麼是WebSocketWebSocket是一種在單一TCP連線上進行全雙工
 JavaScript與WebSocket:打造高效率的即時天氣預報系統
Dec 17, 2023 pm 05:13 PM
JavaScript與WebSocket:打造高效率的即時天氣預報系統
Dec 17, 2023 pm 05:13 PM
JavaScript和WebSocket:打造高效的即時天氣預報系統引言:如今,天氣預報的準確性對於日常生活以及決策制定具有重要意義。隨著技術的發展,我們可以透過即時獲取天氣數據來提供更準確可靠的天氣預報。在本文中,我們將學習如何使用JavaScript和WebSocket技術,來建立一個高效的即時天氣預報系統。本文將透過具體的程式碼範例來展示實現的過程。 We
 簡易JavaScript教學:取得HTTP狀態碼的方法
Jan 05, 2024 pm 06:08 PM
簡易JavaScript教學:取得HTTP狀態碼的方法
Jan 05, 2024 pm 06:08 PM
JavaScript教學:如何取得HTTP狀態碼,需要具體程式碼範例前言:在Web開發中,經常會涉及到與伺服器進行資料互動的場景。在與伺服器進行通訊時,我們經常需要取得傳回的HTTP狀態碼來判斷操作是否成功,並根據不同的狀態碼來進行對應的處理。本篇文章將教你如何使用JavaScript來取得HTTP狀態碼,並提供一些實用的程式碼範例。使用XMLHttpRequest
