


Python爬蟲獲取資料的方法
Python爬蟲可以透過請求庫發送HTTP請求、解析庫解析HTML、正規表示式提取數據,或使用數據抓取框架來獲取數據。更多關於Python爬蟲相關知識。詳情請閱讀本專題下面的文章。 php中文網歡迎大家前來學習。
 165
165
 12
12
Python爬蟲獲取資料的方法

Python爬蟲獲取資料的方法
Python爬蟲可以透過請求庫發送HTTP請求、解析庫解析HTML、正規表示式提取數據,或使用數據抓取框架來獲取數據。詳細介紹:1、請求庫發送HTTP請求,如Requests、urllib等;2、解析庫解析HTML,如BeautifulSoup、lxml等;3、正規表達式提取數據,正則表達式是一種用來描述字串模式的工具,可以透過匹配模式來提取出符合要求的資料等等。
Nov 13, 2023 am 10:44 AM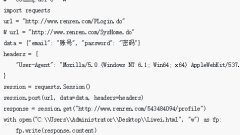
requests函式庫的基本使用
1. response.content和response.text的區別response.content是編碼後的byte類型(「str」資料類型),response.text是unicode類型。這兩種方法的使用要視情況而定。注意:unicode -> str 是編碼過程(encode()); str -> unicode 是解碼過程(decode())。範例如下:# --codin...
Jun 11, 2018 pm 10:55 PM
Python網路爬蟲requests函式庫怎麼使用
1.什麼是網路爬蟲簡單來說,就是建立一個程序,以自動化的方式從網路上下載、解析和組織資料。就像我們瀏覽網頁的時候,對於我們感興趣的內容我們會複製粘貼到自己的筆記本中,方便下次閱讀瀏覽——網絡爬蟲幫我們自動完成這些內容當然如果遇到一些無法複製粘貼的網站— —網路爬蟲就更能顯示它的力量了為什麼需要網絡爬蟲當我們需要做一些數據分析的時候——而很多時候這些數據存儲在網頁中,手動下載需要花
May 15, 2023 am 10:34 AM
一篇文章帶你去搞定Python中urllib函式庫(操作網址)
使用Python語言,能夠幫助大家更好的學習Python。 urllib提供的功能就是利用程式去執行各種HTTP請求。如果要模擬瀏覽器完成特定功能,需要把請求偽裝成瀏覽器。偽裝的方法是先監控瀏j覽器發出的請求,再根據瀏覽器的請求頭來偽裝,User-Agent頭就是用來識別瀏覽器的。
Jul 25, 2023 pm 02:08 PM
python3.6想用urllib2套件怎麼辦
Pyhton2中的urllib2工具包,在Python3中分拆成了urllib.request和urllib.error兩個包。就導致找不到包包,同時也沒辦法安裝。所以安裝這兩個包,導入時即可使用方法。
Jul 01, 2019 pm 02:18 PM
Python 2.x 中如何使用urllib.urlopen()函數發送GET請求
Python是一種流行的程式語言,廣泛用於Web開發、資料分析和自動化任務等領域。在Python2.x版本中,使用urllib函式庫的urlopen()函數可以方便地傳送GET請求和取得回應資料。本文將詳細介紹在Python2.x中如何使用urlopen()函數傳送GET請求,並提供對應的程式碼範例。在使用urlopen()函數發送GET請求之前,我們首先需要
Jul 29, 2023 am 08:48 AM
詳解Python之urllib爬蟲、request模組和parse模組
urllib是Python中用來處理URL的工具包,本文利用該工具包進行爬蟲開發講解,畢竟爬蟲應用開發在Web互聯網數據採集中十分重要。文章目錄urllibrequest模組存取URLRequest類別其他類別parse模組解析URL轉義URLrobots.txt文件
Mar 21, 2021 pm 03:15 PM
python beautifulsoup4模組怎麼用
一、BeautifulSoup4基礎知識補充BeautifulSoup4是一款python解析庫,主要用於解析HTML和XML,在爬蟲知識體系中解析HTML會比較多一些,該庫安裝指令如下:pipinstallbeautifulsoup4BeautifulSoup在解析資料時,需依賴第三方解析器,常用解析器與優點如下所示:python標準函式庫html.parser:python內建標準函式庫,容錯能力強;lxml解析器:速度快,容錯能力強;html5lib:容錯性最強,解析方式與瀏覽器一致。接下來用一段
May 11, 2023 pm 10:31 PM
一文搞懂Python爬蟲解析器BeautifulSoup4
這篇文章為大家帶來了關於Python的相關知識,其中主要整理了爬蟲解析器BeautifulSoup4的相關問題,Beautiful Soup是一個可以從HTML或XML檔案中提取資料的Python庫,它能夠透過你喜歡的轉換器實現慣用的文件導航、尋找、修改文件的方式,下面一起來看一下,希望對大家有幫助。
Jul 12, 2022 pm 04:56 PM
Python爬蟲怎麼使用BeautifulSoup和Requests抓取網頁數據
一、簡介網路爬蟲的實現原理可以歸納為以下幾個步驟:發送HTTP請求:網路爬蟲透過向目標網站發送HTTP請求(通常為GET請求)來取得網頁內容。在Python中,可以使用requests庫發送HTTP請求。解析HTML:收到目標網站的回應後,爬蟲需要解析HTML內容以擷取有用資訊。 HTML是一種用於描述網頁結構的標記語言,它由一系列嵌套的標籤組成。爬蟲可以根據這些標籤和屬性定位和提取所需的資料。在Python中,可以使用BeautifulSoup、lxml等函式庫解析HTML。資料擷取:解析HTML後,
Apr 29, 2023 pm 12:52 PM
Python正規表示式 - 檢查輸入是否為浮點數
浮點數在從數學計算到數據分析的各種程式設計任務中發揮著至關重要的作用。然而,當處理使用者輸入或來自外部來源的資料時,驗證輸入是否是有效的浮點數變得至關重要。 Python提供了強大的工具來應對這項挑戰,其中一個工具就是正規表示式。在本文中,我們將探討如何在Python中使用正規表示式來檢查輸入是否為浮點數。正規表示式(通常稱為regex)提供了一種簡潔且靈活的方式來定義模式並在文字中搜尋匹配項。透過利用正規表示式,我們可以建立一個與浮點數格式精確匹配的模式,並相應地驗證輸入。在本文中,我們將探討如何在Pyt
Sep 15, 2023 pm 04:09 PM

熱門文章

熱工具
Kits AI
用人工智慧藝術家的聲音改變你的聲音。創建並訓練您自己的人工智慧語音模型。
SOUNDRAW - AI Music Generator
使用 SOUNDRAW 的 AI 音樂產生器輕鬆為影片、電影等創作音樂。
Web ChatGPT.ai
使用OpenAI聊天機器人免費的Chrome Extension,以進行有效的瀏覽。
Resume Yay
真正免費的AI簡歷構建器
bestcoloringpages
所有年齡和場合的免費可打印的AI著色頁。

