
課程 中級 11382
課程介紹:《自學IT網Linux負載平衡影片教學》主要透過對web,lvs以及在nagin下對Linux進行腳本操作來實現Linux負載平衡。


解決問題2003(HY000):無法連接到MySQL伺服器' db_mysql:3306'(111)的方法
2023-09-05 11:18:47 0 1 884
2023-09-05 14:46:42 0 1 769
2023-09-05 15:18:28 0 1 650
2023-09-05 15:06:32 0 1 620

課程介紹:深度強化學習(DeepReinforcementLearning)是一種結合了深度學習和強化學習的先進技術,被廣泛應用於語音辨識、影像辨識、自然語言處理等領域。 Go語言作為一門快速、有效率、可靠的程式語言,可以為深度強化學習研究提供幫助。本文將介紹如何使用Go語言進行深度強化學習研究。一、安裝Go語言和相關函式庫在開始使用Go語言進行深度強化學習
2023-06-10 評論 0 1220
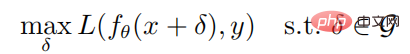
課程介紹:01 前言論文是關於深度強化學習對抗攻擊的工作。在該論文中,作者從穩健優化的角度研究了深度強化學習策略對抗攻擊的穩健性。在魯棒優化的框架下,透過最小化策略的預期回報來給出最優的對抗攻擊,相應地,透過提高策略應對最壞情況的性能來實現良好的防禦機制。考慮到攻擊者通常無法在訓練環境中攻擊,作者提出了一種貪婪攻擊演算法,該演算法試圖在不與環境互動的情況下最小化策略的預期回報;另外作者還提出一種防禦演算法,該演算法試圖在不與環境互動的情況下最小化策略的預期回報;另外作者還提出一種防禦演算法,該演算法以最大-最小的博弈來對深度強化學習演算法進行對抗訓練。在Atari遊戲環境中的實驗結果表明,作
2023-04-08 評論 0 1326
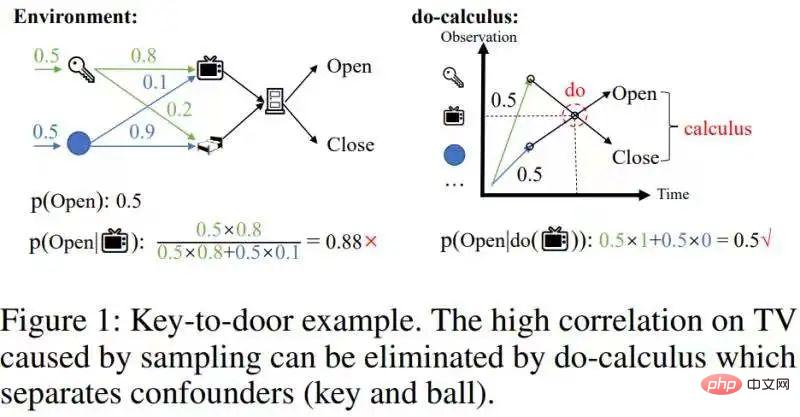
課程介紹:這篇《FastCounterfactualInferenceforHistory-BasedReinforcementLearning》提出一種快速因果推理演算法,使得因果推理的計算複雜度大幅降低──降低到可以和online強化學習結合的程度。本文理論貢獻主要有兩點:1、提出了時間平均因果效應的概念;2、將著名的後門準則從單變量幹預效應估計推廣到多變量幹預效應估計,稱之為步進後門準則。背景需要準備關於部分可觀測強化學習和因果推理的基礎知識。這裡不做太多介紹,給幾個傳送門:部分可觀測強化
2023-04-15 評論 0 1081

課程介紹:逆向強化學習(IRL)是一種機器學習技術,透過觀察到的行為來推斷背後的潛在動機。與傳統的強化學習不同,IRL無需明確的獎勵訊號,而是透過行為來推斷潛在獎勵函數。這種方法為理解和模擬人類行為提供了一個有效的途徑。 IRL的工作原理是基於馬可夫決策過程(MDP)的架構。在MDP中,智能體透過選擇不同的行動與環境互動。環境會根據智能體的行動給予一個獎勵訊號。 IRL的目標是從觀察到的智能體行為推斷出一個未知的獎勵函數,以解釋智能體的行為。透過分析智能體在不同狀態下選擇的行動,IRL可以建模智能體的
2024-01-22 評論 0 885

課程介紹:AB測試是一種在線上實驗中廣泛應用的技術。它的主要目的是比較兩個或多個版本的頁面或應用程序,以確定哪個版本能夠實現更好的業務目標。這些目標可以是點擊率、轉換率等。與此相反,強化學習是一種機器學習方法,透過試誤學習來優化決策策略。策略梯度強化學習是一種特殊的強化學習方法,旨在透過學習最佳策略來最大化累積獎勵。兩者在優化業務目標方面有著不同的應用。在AB測試中,我們將不同的頁面版本視為不同的行動,而業務目標可以被視為獎勵訊號的重要指標。為了實現最大化的業務目標,我們需要設計一個策略,該策略可以選
2024-01-24 評論 0 995
