
python3.5.2
執行以下程式碼
#!/bin/env python3
# coding:utf-8
"""
ljk 20161116(update 20170217)
This script should be put in crontab in every web server.Execute every n minutes.
Collect nginx access log, process it and insert the result into mysql.
"""
import os
import re
import subprocess
import time
import warnings
import pymysql
from sys import argv, exit
from socket import gethostname
from urllib.parse import unquote
from zlib import crc32
from multiprocessing import Pool
##### 自定义部分 #####
# 定义日志格式,利用非贪婪匹配和分组匹配,需要严格参照日志定义中的分隔符和引号
log_pattern = r'^(?P<remote_addr>.*?) - \[(?P<time_local>.*?)\] "(?P<request>.*?)"' \
r' (?P<status>.*?) (?P<body_bytes_sent>.*?) (?P<request_time>.*?)' \
r' "(?P<http_referer>.*?)" "(?P<http_user_agent>.*?)" - (?P<http_x_forwarded_for>.*)$'
# request的正则,其实是由 "request_method request_uri server_protocol"三部分组成
request_uri_pattern = r'^(?P<request_method>(GET|POST|HEAD|DELETE)?) (?P<request_uri>.*?) (?P<server_protocol>HTTP.*)$'
# 日志目录
log_dir = '/data/wwwlogs/'
# 要处理的站点(可随需要想list中添加)
todo = ['www']
# MySQL相关设置
mysql_host = '处理过'
mysql_user = '处理过'
mysql_passwd = '处理过'
mysql_port = 3306
mysql_database = '处理过'
# 表结构
creat_table = "CREATE TABLE IF NOT EXISTS {} (\
id bigint unsigned NOT NULL AUTO_INCREMENT PRIMARY KEY,\
server char(11) NOT NULL DEFAULT '',\
uri_abs varchar(200) NOT NULL DEFAULT '' COMMENT '对$uri做uridecode,然后做抽象化处理',\
uri_abs_crc32 bigint unsigned NOT NULL DEFAULT '0' COMMENT '对上面uri_abs字段计算crc32',\
args_abs varchar(200) NOT NULL DEFAULT '' COMMENT '对$args做uridecode,然后做抽象化处理',\
args_abs_crc32 bigint unsigned NOT NULL DEFAULT '0' COMMENT '对上面args字段计算crc32',\
time_local timestamp NOT NULL DEFAULT '0000-00-00 00:00:00',\
response_code smallint NOT NULL DEFAULT '0',\
bytes_sent int NOT NULL DEFAULT '0' COMMENT '发送给客户端的响应大小',\
request_time float(6,3) NOT NULL DEFAULT '0.000',\
user_ip varchar(40) NOT NULL DEFAULT '',\
cdn_ip varchar(15) NOT NULL DEFAULT '' COMMENT 'CDN最后节点的ip:空字串表示没经过CDN; - 表示没经过CDN和F5',\
request_method varchar(7) NOT NULL DEFAULT '',\
uri varchar(255) NOT NULL DEFAULT '' COMMENT '$uri,已做uridecode',\
args varchar(255) NOT NULL DEFAULT '' COMMENT '$args,已做uridecode',\
referer varchar(255) NOT NULL DEFAULT '' COMMENT '',\
KEY time_local (time_local),\
KEY uri_abs_crc32 (uri_abs_crc32),\
KEY args_abs_crc32 (args_abs_crc32)\
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 row_format=compressed"
##### 自定义部分结束 #####
# 主机名
global server
server = gethostname()
# 今天零点
global today_start
today_start = time.strftime('%Y-%m-%d', time.localtime()) + ' 00:00:00'
# 将pymysql对于操作中的警告信息转为可捕捉的异常
warnings.filterwarnings('error', category=pymysql.err.Warning)
def my_connect():
"""链接数据库"""
global connection, con_cur
try:
connection = pymysql.connect(host=mysql_host, user=mysql_user, password=mysql_passwd,
charset='utf8mb4', port=mysql_port, autocommit=True, database=mysql_database)
except pymysql.err.MySQLError as err:
print('Error: ' + str(err))
exit(20)
con_cur = connection.cursor()
def create_table(t_name):
"""创建各站点对应的表"""
my_connect()
try:
con_cur.execute(creat_table.format(t_name))
except pymysql.err.Warning:
pass
def process_line(line_str):
"""
处理每一行记录
line_str: 该行数据的字符串形式
"""
processed = log_pattern_obj.search(line_str)
if not processed:
'''如果正则根本就无法匹配该行记录时'''
print("Can't process this line: {}".format(line_str))
return server, '', 0, '', 0, '', '', '', '', '', ''
else:
# remote_addr (客户若不经过代理,则可认为用户的真实ip)
remote_addr = processed.group('remote_addr')
# time_local
time_local = processed.group('time_local')
# 转换时间为mysql date类型
ori_time = time.strptime(time_local.split()[0], '%d/%b/%Y:%H:%M:%S')
new_time = time.strftime('%Y-%m-%d %H:%M:%S', ori_time)
# 处理uri和args
request = processed.group('request')
request_further = request_uri_pattern_obj.search(request)
if request_further:
request_method = request_further.group('request_method')
request_uri = request_further.group('request_uri')
uri_args = request_uri.split('?', 1)
# 对uri和args进行urldecode
uri = unquote(uri_args[0])
args = '' if len(uri_args) == 1 else unquote(uri_args[1])
# 对uri和args进行抽象化
uri_abs = text_abstract(uri, 'uri')
args_abs = text_abstract(args, 'args')
# 对库里的uri_abs和args_abs字段进行crc32校验
uri_abs_crc32 = crc32(uri_abs.encode())
args_abs_crc32 = 0 if args_abs == '' else crc32(args_abs.encode())
else:
print('$request abnormal: {}'.format(line_str))
request_method = ''
uri = request
uri_abs = ''
uri_abs_crc32 = 0
args = ''
args_abs = ''
args_abs_crc32 = 0
# 状态码,字节数,响应时间
response_code = processed.group('status')
bytes_sent = processed.group('body_bytes_sent')
request_time = processed.group('request_time')
# user_ip,cdn最后节点ip,以及是否经过F5
http_x_forwarded_for = processed.group('http_x_forwarded_for')
ips = http_x_forwarded_for.split()
# user_ip:用户真实ip
# cdn_ip: CDN最后节点的ip,''表示没经过CDN;'-'表示没经过CDN和F5
if http_x_forwarded_for == '-':
'''没经过CDN和F5'''
user_ip = remote_addr
cdn_ip = '-'
elif ips[0] == remote_addr:
'''没经过CDN,经过F5'''
user_ip = remote_addr
cdn_ip = ''
else:
'''经过CDN和F5'''
user_ip = ips[0].rstrip(',')
cdn_ip = ips[-1]
return (server, uri_abs, uri_abs_crc32, args_abs, args_abs_crc32, new_time, response_code, bytes_sent,
request_time, user_ip, cdn_ip, request_method, uri, args)
def text_abstract(text, what):
"""进一步处理uri和args,将其做抽象化,方便对其进行归类
如uri: /article/10.html 抽象为 /article/?.html
如args: s=你好&type=0 抽象为 s=?&type=?
规则:待处理部分由[a-zA-Z\-_]组成的,则保留,其他情况值转为'?'
"""
tmp_abs = ''
if what == 'uri':
uri_list = [tmp for tmp in text.split('/') if tmp != '']
if len(uri_list) == 0:
'''uri为"/"的情况'''
tmp_abs = '/'
else:
for i in range(len(uri_list)):
if not re.match(r'[a-zA-Z\-_]+?(\..*)?$', uri_list[i]):
'''uri不符合规则时,进行转换'''
if '.' in uri_list[i]:
if not re.match(r'[a-zA-Z\-_]+$', uri_list[i].split('.')[0]):
uri_list[i] = '?.' + uri_list[i].split('.')[1]
else:
uri_list[i] = '?'
for v in uri_list:
tmp_abs += '/{}'.format(v)
if text.endswith('/'):
'''如果原uri后面有"/",要保留'''
tmp_abs += '/'
elif what == 'args':
if text == '':
tmp_abs = ''
else:
try:
tmp_dict = OrderedDict((tmp.split('=') for tmp in text.split('&')))
for k, v in tmp_dict.items():
if not re.match(r'[a-zA-Z\-_]+$', v):
'''除了value值为全字母的情况,都进行转换'''
tmp_dict[k] = '?'
for k, v in tmp_dict.items():
if tmp_abs == '':
tmp_abs += '{}={}'.format(k, v)
else:
tmp_abs += '&{}={}'.format(k, v)
except ValueError:
'''参数中没有= 或者 即没&也没= 会抛出ValueError'''
tmp_abs = '?'
return tmp_abs
def insert_data(line_data, cursor, results, limit, t_name, l_name):
"""
记录处理之后的数据,累积limit条执行一次插入
line_data:每行处理之前的字符串数据;
limit:每limit行执行一次数据插入;
t_name:对应的表名;
l_name:日志文件名
"""
line_result = process_line(line_data)
results.append(line_result)
# print('len(result):{}'.format(len(result))) #debug
if len(results) == limit:
insert_correct(cursor, results, t_name, l_name)
results.clear()
print('{} {} 处理至 {}'.format(time.strftime('%H:%M:%S', time.localtime()), l_name, line_result[5]))
def insert_correct(cursor, results, t_name, l_name):
"""在插入数据过程中处理异常"""
insert_sql = 'insert into {} (server,uri_abs,uri_abs_crc32,args_abs,args_abs_crc32,time_local,response_code,' \
'bytes_sent,request_time,user_ip,cdn_ip,request_method,uri,args) ' \
'values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)'.format(t_name)
try:
cursor.executemany(insert_sql, results)
except pymysql.err.Warning as err:
print('\n{} Warning: {}'.format(l_name, err))
except pymysql.err.MySQLError as err:
print('\n{} Error: {}'.format(l_name, err))
print('插入数据时出错...\n')
connection.close()
exit(10)
def get_prev_num(t_name, l_name):
"""取得今天已入库的行数 t_name:表名 l_name:日志文件名"""
try:
con_cur.execute('select min(id) from {0} where time_local=('
'select min(time_local) from {0} where time_local>="{1}")'.format(t_name, today_start))
min_id = con_cur.fetchone()[0]
if min_id is not None: # 假如有今天的数据
con_cur.execute('select max(id) from {}'.format(t_name))
max_id = con_cur.fetchone()[0]
con_cur.execute(
'select count(*) from {} where id>={} and id<={} and server="{}"'.format(t_name, min_id, max_id, server))
prev_num = con_cur.fetchone()[0]
else:
prev_num = 0
return prev_num
except pymysql.err.MySQLError as err:
print('Error: {}'.format(err))
print('Error:未取得已入库的行数,本次跳过{}\n'.format(l_name))
return
def del_old_data(t_name, l_name, n=3):
"""删除n天前的数据,n默认为3"""
# n天前的日期间
three_days_ago = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time() - 3600 * 24 * n))
try:
con_cur.execute('select max(id) from {0} where time_local=('
'select max(time_local) from {0} where time_local!="0000-00-00 00:00:00" and time_local<="{1}")'.format(
t_name, three_days_ago))
max_id = con_cur.fetchone()[0]
if max_id is not None:
con_cur.execute('delete from {} where id<={}'.format(t_name, max_id))
except pymysql.err.MySQLError as err:
print('\n{} Error: {}'.format(l_name, err))
print('未能删除表{}天前的数据...\n'.format(n))
def main_loop(log_name):
"""主逻辑 log_name:日志文件名"""
table_name = log_name.split('.access')[0].replace('.', '_') # 将域名例如m.api转换成m_api,因为表名中不能包含'.'
results = []
# 创建表
create_table(table_name)
# 当前日志文件总行数
num = int(subprocess.run('wc -l {}'.format(log_dir + log_name), shell=True, stdout=subprocess.PIPE,
universal_newlines=True).stdout.split()[0])
print('num: {}'.format(num)) # debug
# 上一次处理到的行数
prev_num = get_prev_num(table_name, log_name)
if prev_num is not None:
# 根据当前行数和上次处理之后记录的行数对比,来决定本次要处理的行数范围
i = 0
with open(log_name) as fp:
for line in fp:
i += 1
if i <= prev_num:
continue
elif prev_num < i <= num:
insert_data(line, con_cur, results, 1000, table_name, log_name)
else:
break
# 插入不足1000行的results
if len(results) > 0:
insert_correct(con_cur, results, table_name, log_name)
del_old_data(table_name, log_name)
if __name__ == "__main__":
# 检测如果当前已经有该脚本在运行,则退出
if_run = subprocess.run('ps -ef|grep {}|grep -v grep|grep -v "/bin/sh"|wc -l'.format(argv[0]), shell=True,
stdout=subprocess.PIPE).stdout
if if_run.decode().strip('\n') == '1':
os.chdir(log_dir)
logs_list = os.listdir(log_dir)
logs_list = [i for i in logs_list if 'access' in i and os.path.isfile(i) and i.split('.access')[0] in todo]
if len(logs_list) > 0:
# 并行
with Pool(len(logs_list)) as p:
p.map(main_loop, logs_list)日誌檔案清單如下:
#資料庫沒有問題,之前填寫錯訊息,有報錯,修改好之後資料庫就沒有什麼問題了,現在重新執行為什麼沒有任何回饋呢?怎麼排查
root@iZbp1iqn00z9x3jov6bas1Z:~# python log.py
root@iZbp1iqn00z9x3jov6bas1Z:~# python log.py
root@iZbp1iqn00z9x3jov6bas1Z:~# python log.py
root@iZbp1iqn00z9x3jov6bas1Z:~# python log.py
root@iZbp1iqn00z9x3jov6bas1Z:~# python log.py
root@iZbp1iqn00z9x3jov6bas1Z:~# python log.py
root@iZbp1iqn00z9x3jov6bas1Z:~#
root@iZbp1iqn00z9x3jov6bas1Z:~#
root@iZbp1iqn00z9x3jov6bas1Z:~#
root@iZbp1iqn00z9x3jov6bas1Z:~#
root@iZbp1iqn00z9x3jov6bas1Z:~#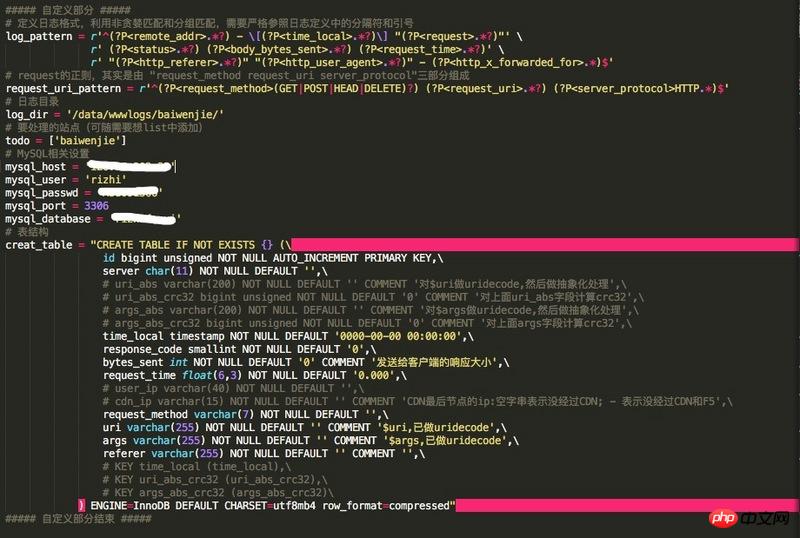



















請先看一下資料庫表記錄的id有沒有自增,用視覺化工具看資料表結構,因為表引擎是innodb,所以有可能是pymysql執行insert後,還要執行commit方法才可行,python別的操作myslq資料的引擎(單指innodb)工具,例如mysqlconnetcor,是有commit這個步驟的,請看pymysql的wiki文檔
沒反應有可能是語句沒有執行, 或者執行了, 沒有反饋! 你可以在腳本中多加幾句 print xxx, 通過輸出判斷是否執行到那個語句, 同時看看處理的結果是不是你想要的
雷雷