
还以书上例子来说
sqlcreate table people( last_name varchar(50) not null, first_name varchar(50) not null, dob date not null, gender enum('m','f') no null, key(last_name,first_name,dob) );
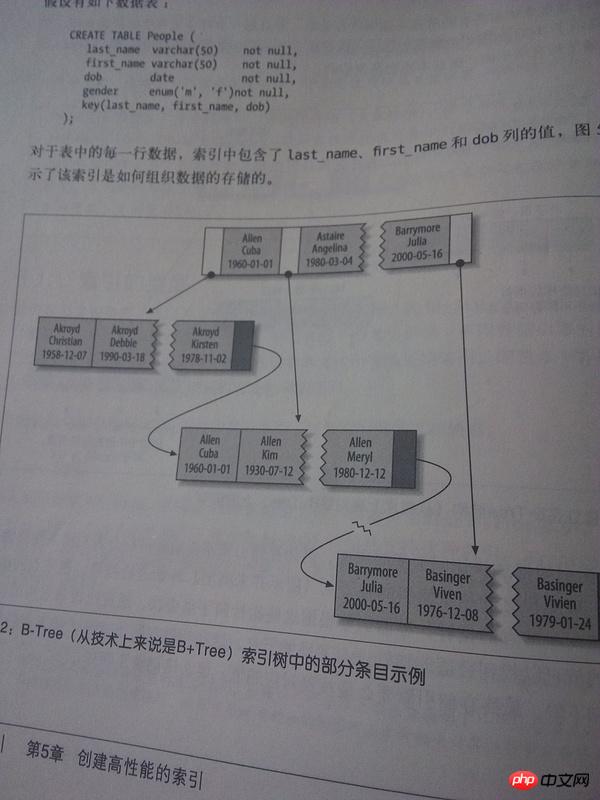
这个 B+tree 的索引示意图能明白,但是为什么马上在下文就说"B+树索引适用于全键值,键值范围或者最左键前缀查找"
我应该如何去理解,是否和 B+tree 有着不可分割的关系,应该如何理解.




















這句話的理解確實和B+樹的原理有著密切的關聯。
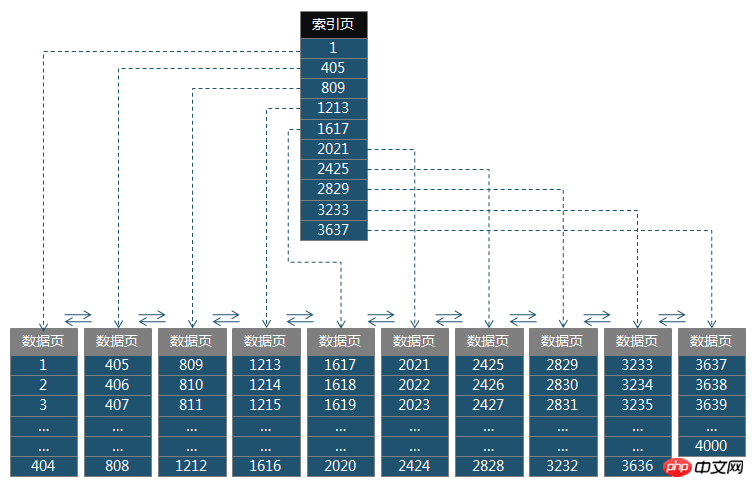
來看一張簡單的B+樹示意圖,該圖有一個根節點,剩下的只有葉子結點(沒有中間結點)。
相對於B-樹來說,B+樹有這樣的特徵:上級結點的元素會在下級結點中出現,例如圖中根節點中的“1”,也會出現在第一個葉子結點中;葉子結點之間是相互連接的(這是雙向鍊錶的結構)。
現在假設圖中的根節點存放的是主鍵Id,葉子結點存放的是資料項目(包括主鍵Id,還有其他欄位)。現在我們要執行這樣的SQL:
這時候資料庫就會在根節點中查找id=2426,在根節點中從上往下查找,可以得出2426是在2425到2829之間,所以要到第7個葉子結點中查找就可以找到id=2426的資料。這就是B+樹中鍵值的查找方式,可以看到要找到id=2426的數據,總共只要存取B+樹的兩個結點,磁碟IO開銷是比較小的。
當要執行這樣的SQL:
這就涉及到鍵值範圍查找的問題了,首先來看407,在根節點中處於405到809之間,所以應該到第二個葉子結點中開始找起,由於B+樹的葉子結點是一個雙向鍊錶,意味著當第二個資料頁406-808檢索完畢後,可以直接跳到下一個葉子結點檢索,直到所需資料都檢索完畢。
如果想加深理解B+樹的優點,可以跟B-樹比較理解一下。
這個說法是不正確的,
如果只是你題目中的優點,那麼,很明顯,二元樹比較適合,
但是在使用中,二元樹是不穩定的,有幾率變成單鍊錶,所以還有平衡二元樹。
而且隨著資料量的增加,查找效率是指數降低,因為二元樹的尋找效率跟它的層級成正比。
B-樹和B+樹都是在二元樹的基礎上(但本身並非二元樹)改良而來,是一種平衡策略。
B+樹經過父節點縮小範圍,然後透過葉子節點遍歷查找,並非效率最高,
但是,由於資料庫或檔案操作設計IO,這樣大大減少了IO,所以速度快。
以上是範圍查找,對於點查找,hash更合適。