
如图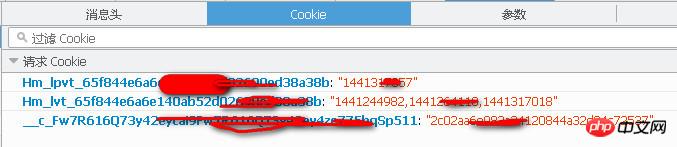
图片上是浏览器抓包的cookies结果,cookies有3个内容,分别是Hm_lpvt,Hm_lvt,__c_Fw7.
我求教的问题,python怎么得到这样的cookies?
我的做法:分别用了requests.session(),urllib2,pycurl三种方法, 却都是只获得了__c_Fw7,另外2个怎么得到呢?
补充:Hm_lpvt的values只保存在浏览器会话,它的值浏览器刷新一次就更改一次。
pycurl库得到cookies的截图,__c_18j9,就是上面说的__c_Fw7。
response截图,看不到 set-cookies,或许是我方法不对,才看不到?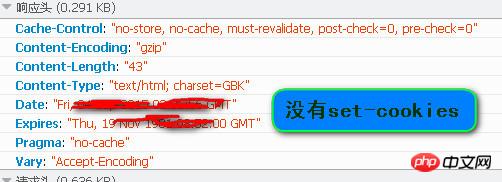
百度response的确是有set-cookie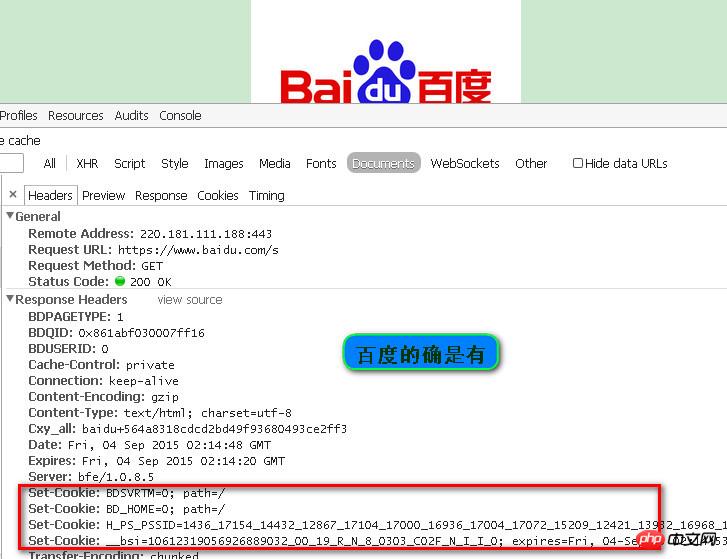




















你可以自己寫程式碼來控制cookie,主要就是看reqsponse的headers中的set-cookie字段,然後把它解析出來,再傳到下一次的request的headers中去。
例如下面這個就是我請求www.baidu.com時的response中的set-cookie欄位
自己解析下,再傳到request中去 就行了。
瀏覽器會解析 html 然後存取請求頁面中的 css 、圖片、javascript 等資源,然後執行 js 腳本,會有各種各樣的其它請求。
自己寫的腳本只會請求一次,並不會解析 html 。
如果開發者把一此 cookies 藏在 js 腳本的請求中的話,你的腳本就會出現缺少 cookies 的情況。
你可以用 chrome 的開發者工具追蹤一下頁面載入的所有請求,看下 set-cookies 指令是在哪一個請求中的,然後用腳本模擬。
參考我在寫這篇登陸極路由的程式碼 http://www.cnblogs.com/gayhub/p/5476712.html
必須指定正確的Content-Type,不然取不到COOKIES
抓包工具用fiddler比較好。