
我在爬取凤凰网却出现
UnicodeEncodeError: 'gbk' codec can't encode character 'xa0' in position 151120: illegal multibyte sequence
这是我的代码
__author__ = 'my'
import urllib.request
url = 'http://www.ifeng.com/'
req = urllib.request.urlopen(url)
req = req.read()
req = req.decode('utf-8')
print(req)
为什么utf8却报错GBK?



















這是 cmd.exe 的問題,別的軟體都能正確解碼。例如 記事本、瀏覽器。 。 。 。
追加:
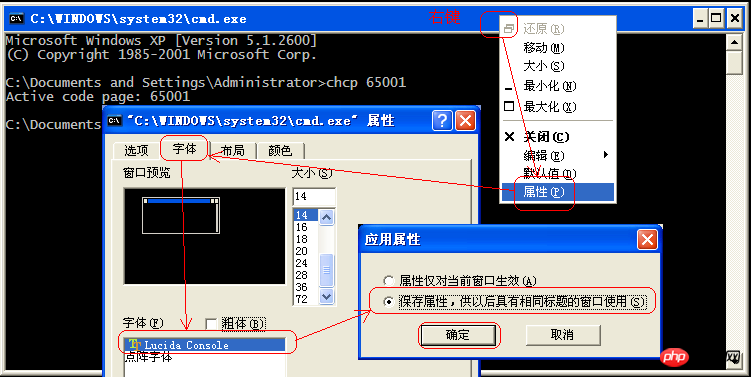
其實也可以修改cmd.exe 的編碼為utf-8(cp65001)
步驟:
1、運行CMD.exe
2、chcp 65001
3、修改視窗屬性的字體
在CMD視窗標題上點選右鍵,選擇"屬性"->"字體",將字體修改為True Type字體"Lucida Console"
如圖:
4、運行 python
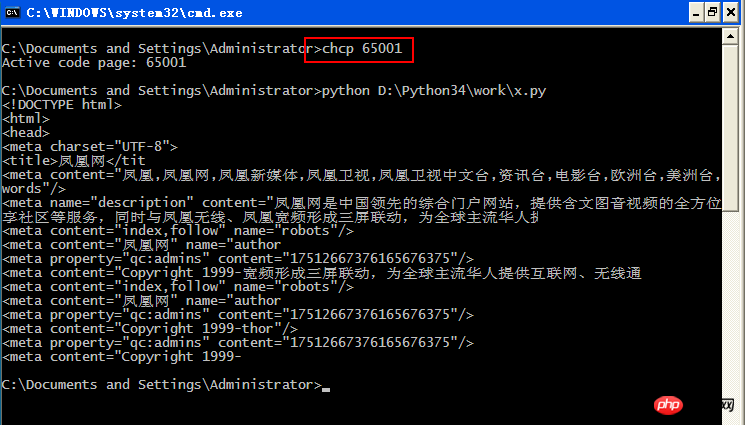
x.py 的內容:
剛我把題主的程式碼放到pycharm中,沒有出現這個問題。然後我用windows命令提示字元一行一行敲,出現了這個問題。 windows命令提示字元是使用的gbk編碼,而網頁本身使用的是utf-8進行編碼。如果你希望在命令列能運行它,那麼你需要這麼寫:
這裡
req = req.decode('gbk', 'ignore')我解釋一下:要在windows命令提示符中顯示,需要解碼為gbk,但是utf-8本身有些字符使用gbk解碼又會失敗,所以需要第二個參數ignoreign ,這個參數意思就是把不能解碼的字元捨棄掉。說句題外話,編碼可能也會遇到這個問題,例如用requests庫請求的話直接就是請求的字串而不是位元組類型,如果編碼遇到問題也用str.encode('編碼', 'ingore ').decode('解碼')來解決類似問題。
如果沒聽明白可以看看我的這篇部落格
還有回答一下題主的一個問題,有的網頁沒問題可能是某些網頁採用的就是GBK編碼或那些文字對於GBK和UTF-8都相容
估計你係統預設編碼是gbk,可以試試
你是用windows控制台運行的吧?因為控制台預設編碼是gbk。
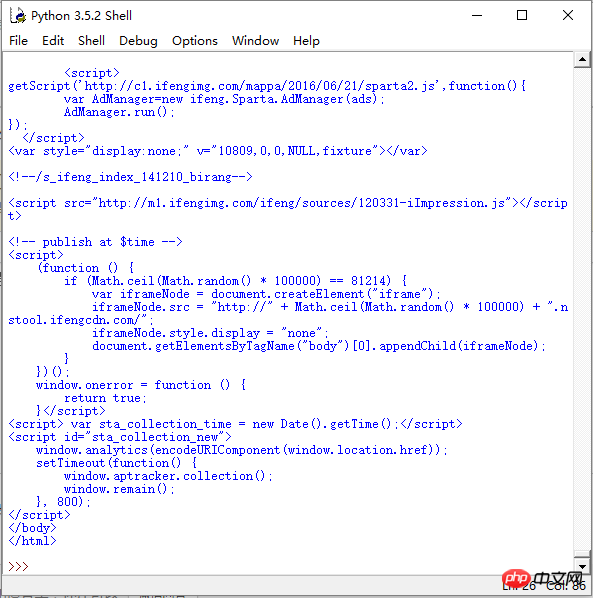
用python自備的解釋器就沒問題:
或用其他的工具,別用控制台就行。
# _*_ coding: utf-8 _*_指定檔案編碼
聲明你程式的編碼。