
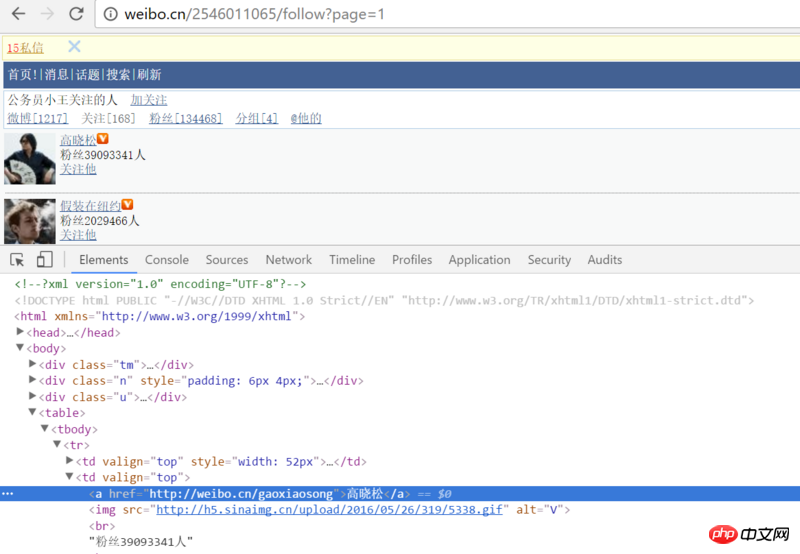
第一次用xpath写的爬虫,想获取某人关注列表的每位博主的昵称,但是用下面的代码得到的li永远是空的,为什么捏?
for i in range(1, pagenum + 1):
urli = "http://weibo.cn/%d/follow?page=%d"%(uid,i)
html_sample = requests.get(urli, cookies=cookie).content
# 使用xpath获取所有昵称
selector = etree.HTML(html_sample)
list = selector.xpath('//table/tbody/tr/td[2]/a[1]/text()')
for li in list:
print nums,li
nums += 1


















你打開頁面原始碼看看就知道結構和你截圖的有點差別,
用BeautifulSoup也很方便