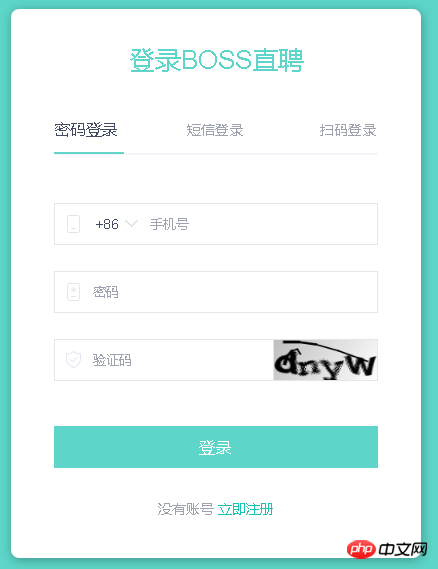
最近想用Python写个爬虫去抓取一些东西,但是碰到个问题,就是验证码不知道该如何处理。现在验证码一般有两种,一种是简单的,比如下面这种纯字符型的:
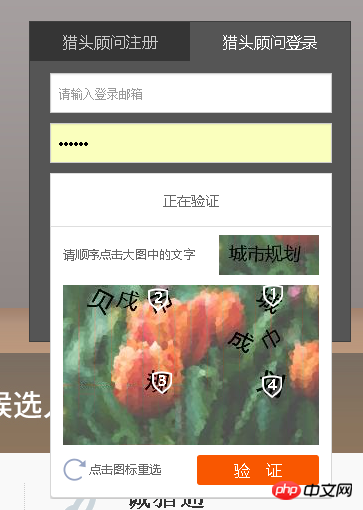
另外一种就是出来一些特定字符,需要按顺序点击的:
我看有的人说可以获取浏览器cookies写到程序里就直接通过验证了,有的说这个涉及到机器学习方面的东西。由于我个人以前没接触过这方面东西,所以不知道从何处入手,想问下要处理这种验证码的话,一般该如何处理? 有没有这方面合适的书推荐下啊……
走同样的路,发现不同的人生
這個本身用驗證碼技術就是防止爬蟲之類的網路程式的,我所知道的破解驗證碼就是用人工智慧的圖像識別那塊,好像有類似的函數可用,但是準確率都不會太高的
驗證碼問題,一可以轉到專業服務商提供的API(他們用機器學習或人工),如優優圖,二是自己寫驗證碼識別程序,提供一個項目供參考:https://github.com /luyishisi/...
有一個方案是在瀏覽器手動登陸然後把cookies提取出來直接在爬蟲裡包在請求裡發出去。
圖片一好處理,驗證碼就是張圖片,透過圖片處理可以取得驗證碼(ocr技術);圖片二比較麻煩,如果用第一種方法的話,它的數字覆蓋在文字上面了,在獲取圖片內容的時候難度比較大,第二種方法我沒有什麼好方法,希望有這方面經驗的同學幫忙解答一下
驗證碼就是用來反制機器和爬蟲的,如果驗證碼能讓你的自動化爬蟲輕鬆繞過,那還能叫驗證碼麼?樓主還是先搞清楚驗證碼是個怎麼機制,再來看看是否真如你想像中能夠輕鬆繞過.總而言之,除非人家網站的驗證碼實現有漏洞,否則你是無法繞過驗證碼機制的,你只能識別出驗證碼上的文字,比如OCR(Optical Character Recognition)技術就是用來解決這個問題的.OCR是指電子設備(如掃描儀)檢查紙上打印的字符.通過檢測暗/亮的模式確定其形狀,然後用字符識別方法將形狀翻譯成計算機文字的過程.
驗證碼辨識基本步驟:1.預處理2.灰階化3.二值化4.去噪5.分割6.辨識
總而言之,驗證碼識別門檻高,成本也高,避無可避.比如下圖,驗證碼東倒西歪,還重疊,識別起來有難度.
可以用一個驗證碼服務像是我在用的9eu。
最省事的方式就是把cookie拿出來寫在程式碼裡,不過cookie是有時效性的
應對複雜的驗證碼,比較高效率省時的方法應是對接到打碼平台,交由他們的人工處理。




















這個本身用驗證碼技術就是防止爬蟲之類的網路程式的,我所知道的破解驗證碼就是用人工智慧的圖像識別那塊,好像有類似的函數可用,但是準確率都不會太高的
驗證碼問題,一可以轉到專業服務商提供的API(他們用機器學習或人工),如優優圖,二是自己寫驗證碼識別程序,提供一個項目供參考:https://github.com /luyishisi/...
有一個方案是在瀏覽器手動登陸然後把cookies提取出來直接在爬蟲裡包在請求裡發出去。
圖片一好處理,驗證碼就是張圖片,透過圖片處理可以取得驗證碼(ocr技術);
圖片二比較麻煩,如果用第一種方法的話,它的數字覆蓋在文字上面了,在獲取圖片內容的時候難度比較大,第二種方法我沒有什麼好方法,希望有這方面經驗的同學幫忙解答一下
驗證碼就是用來反制機器和爬蟲的,如果驗證碼能讓你的自動化爬蟲輕鬆繞過,那還能叫驗證碼麼?樓主還是先搞清楚驗證碼是個怎麼機制,再來看看是否真如你想像中能夠輕鬆繞過.總而言之,除非人家網站的驗證碼實現有漏洞,否則你是無法繞過驗證碼機制的,你只能識別出驗證碼上的文字,比如OCR(Optical Character Recognition)技術就是用來解決這個問題的.OCR是指電子設備(如掃描儀)檢查紙上打印的字符.通過檢測暗/亮的模式確定其形狀,然後用字符識別方法將形狀翻譯成計算機文字的過程.
驗證碼辨識基本步驟:
1.預處理
2.灰階化
3.二值化
4.去噪
5.分割
6.辨識
總而言之,驗證碼識別門檻高,成本也高,避無可避.
比如下圖,驗證碼東倒西歪,還重疊,識別起來有難度.
可以用一個驗證碼服務像是我在用的9eu。
最省事的方式就是把cookie拿出來寫在程式碼裡,不過cookie是有時效性的
應對複雜的驗證碼,比較高效率省時的方法應是對接到打碼平台,交由他們的人工處理。