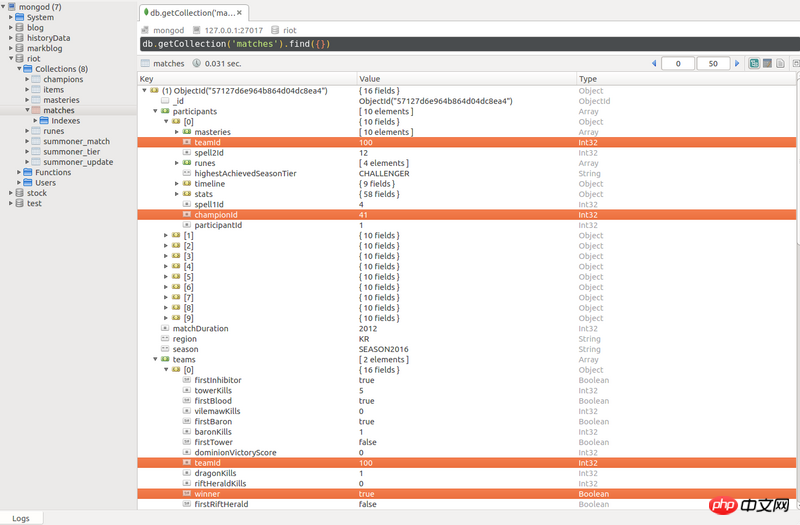
圖為mongodb中一條document結構,記錄的是LOL的一場比賽對局詳情
participants中有10個玩家,前5個teamID為100,後5個teamId為200.比賽的結果哪個隊伍取勝是記錄在teams那個子文檔中的。
我現在的想要查詢championId為64(盲僧), 157(亞索)這兩個英雄在同一個隊伍時的勝利場次,(規定遊戲版本號>6.7),查詢語句我是這樣寫的:
db.getCollection('matches').count({
$and: [
{ "matchVersion": {$gte:"6.7"} }
, {
$or:
[
{
$and:
[
{ "participants": {$elemMatch: {"teamId": 100, "championId": 64 } } }
, { "participants": {$elemMatch: {"teamId": 100, "championId": 157 } } }
, { "teams":{ $elemMatch: {"teamId": 100, "winner":true} } }
]
},
{
$and:
[
{ "participants": {$elemMatch: {"teamId": 200, "championId": 64 } } }
, { "participants": {$elemMatch: {"teamId": 200, "championId": 157 } } }
, { "teams":{ $elemMatch: {"teamId": 200, "winner":true} } }
]
}
]
}
]
}
)資料規模為14萬,可是執行這樣一個查詢要花3秒。已經對對應的查詢建立了索引。查詢explain的結果如下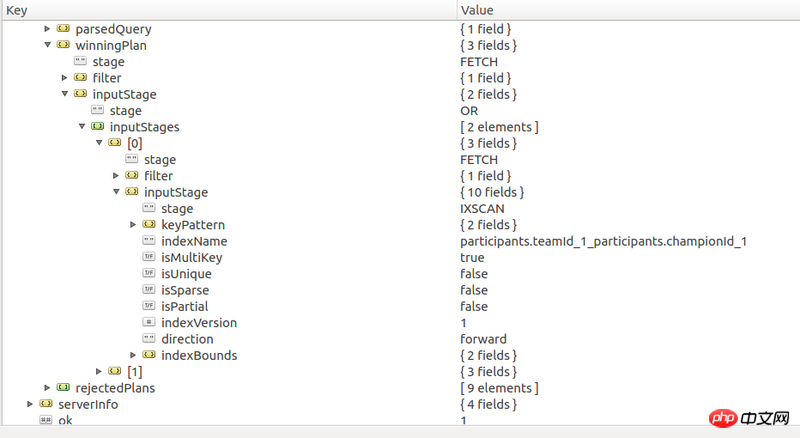
不過好像有些索引也沒用到,例如teams.teamId, teams.winner的複合索引,matchVersion的索引
請問這個查詢該如何最佳化呢?我覺得這個數據規模花這麼久應該是我的使用姿勢不對吧?



















你的執行計畫索引是用了,但是能看出來效率不高,但是很多關鍵資訊被折疊了,無法看出詳細內容。下次最好直接發原始的JSON會比較容易看懂。同樣如果有數據範例也最好發一個JSON出來,這樣別人在解決問題的時候可以有一份測試數據,會方便很多。
$and這個東西大部分時候是不用出現的,一個物件中的兩個並列的元素就是與的關係。這樣可以簡化你的查詢結構,別人看起來也輕鬆一點。所以對你的查詢做了簡化,如下:最後最關鍵的索引問題,推測對你更有用的索引應該是
participants.teamId+participants.championId+teams.teamId+teams.winner+matchVersion的聯合索引,應該根據條件的過濾性把過濾性更好的條件放前面。甚至去掉一些條件以提高寫入效率。但這取決於你的數據分佈情況。為什麼你的索引沒有被用到,mongodb 2.6以後雖然支持交叉索引,可以使用多個索引來滿足同一個查詢,但目前的執行計劃評估的體系使得交叉索引很難被觸發。所以要盡量用一個索引來滿足你的查詢。