

手动安装cloudera cdh4.2 hadoop + hbase + hive(一)

安装版本 hadoop-2.0.0-cdh4.2.0hbase-0.94.2-cdh4.2.0hive-0.10.0-cdh4.2.0jdk1.6.0_38 安装前说明 安装目录为/opt 检查hosts文件 关闭防火墙 设置时钟同步 使用说明 安装hadoop、hbase、hive成功之后启动方式为: 启动dfs和mapreduce desktop1上执行start-
安装版本
<code>hadoop-2.0.0-cdh4.2.0 hbase-0.94.2-cdh4.2.0 hive-0.10.0-cdh4.2.0 jdk1.6.0_38 </code>
安装前说明
- 安装目录为/opt
- 检查hosts文件
- 关闭防火墙
- 设置时钟同步
使用说明
安装hadoop、hbase、hive成功之后启动方式为:
- 启动dfs和mapreduce desktop1上执行start-dfs.sh和start-yarn.sh
- 启动hbase desktop3上执行start-hbase.xml
- 启动hive desktop1上执行hive
规划
<code> 192.168.0.1 NameNode、Hive、ResourceManager
192.168.0.2 SSNameNode
192.168.0.3 DataNode、HBase、NodeManager
192.168.0.4 DataNode、HBase、NodeManager
192.168.0.6 DataNode、HBase、NodeManager
192.168.0.7 DataNode、HBase、NodeManager
192.168.0.8 DataNode、HBase、NodeManager
</code>部署过程
系统和网络配置
-
修改每台机器的名称
[root@desktop1 ~]# cat /etc/sysconfig/network NETWORKING=yes HOSTNAME=desktop1
登录后复制 -
在各个节点上修改/etc/hosts增加以下内容:
[root@desktop1 ~]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.0.1 desktop1 192.168.0.2 desktop2 192.168.0.3 desktop3 192.168.0.4 desktop4 192.168.0.6 desktop6 192.168.0.7 desktop7 192.168.0.8 desktop8
登录后复制 -
配置ssh无密码登陆 以下是设置desktop1上可以无密码登陆到其他机器上。
[root@desktop1 ~]# ssh-keygen
[root@desktop1 ~]# ssh-copy-id -i .ssh/id_rsa.pub desktop2
[root@desktop1 ~]# ssh-copy-id -i .ssh/id_rsa.pub desktop3
[root@desktop1 ~]# ssh-copy-id -i .ssh/id_rsa.pub desktop4
[root@desktop1 ~]# ssh-copy-id -i .ssh/id_rsa.pub desktop6
[root@desktop1 ~]# ssh-copy-id -i .ssh/id_rsa.pub desktop7
[root@desktop1 ~]# ssh-copy-id -i .ssh/id_rsa.pub desktop8
- 每台机器上关闭防火墙:
<code> [root@desktop1 ~]# service iptables stop </code>
安装Hadoop
配置Hadoop
将jdk1.6.0_38.zip上传到/opt,并解压缩。 将hadoop-2.0.0-cdh4.2.0.zip上传到/opt,并解压缩。
在NameNode上配置以下文件:
<code>core-site.xml fs.defaultFS指定NameNode文件系统,开启回收站功能。
hdfs-site.xml
dfs.namenode.name.dir指定NameNode存储meta和editlog的目录,
dfs.datanode.data.dir指定DataNode存储blocks的目录,
dfs.namenode.secondary.http-address指定Secondary NameNode地址。
开启WebHDFS。
slaves 添加DataNode节点主机
</code>- core-site.xml 该文件指定fs.defaultFS连接desktop1,即NameNode节点。
<code>[root@desktop1 hadoop]# pwd
/opt/hadoop-2.0.0-cdh4.2.0/etc/hadoop
[root@desktop1 hadoop]# cat core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--fs.default.name for MRV1 ,fs.defaultFS for MRV2(yarn) -->
<property>
<name>fs.defaultFS</name>
<!--这个地方的值要和hdfs-site.xml文件中的dfs.federation.nameservices一致-->
<value>hdfs://desktop1</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
<property>
<name>fs.trash.checkpoint.interval</name>
<value>10080</value>
</property>
</configuration>
</code>- hdfs-site.xml 该文件主要设置数据副本保存份数,以及namenode、datanode数据保存路径以及http-address。
<code>[root@desktop1 hadoop]# cat hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/data/hadoop-${user.name}</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>desktop1:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>desktop2:50090</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
</code>- masters 设置namenode和secondary namenode节点。
<code>[root@desktop1 hadoop]# cat masters desktop1 desktop2 </code>
- slaves 设置哪些机器上安装datanode节点。
<code>[root@desktop1 hadoop]# cat slaves desktop3 desktop4 desktop6 desktop7 desktop8 </code>
配置MapReduce
- mapred-site.xml 配置使用yarn计算框架,以及jobhistory的地址。
<code>[root@desktop1 hadoop]# cat mapred-site.xml <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>desktop1:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>desktop1:19888</value> </property> </configuration> </code>
- yarn-site.xml 主要配置resourcemanager地址以及
yarn.application.classpath(这个路径很重要,要不然集成hive时候会提示找不到class)
<code>[root@desktop1 hadoop]# cat yarn-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>desktop1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>desktop1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>desktop1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>desktop1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>desktop1:8088</value>
</property>
<property>
<description>Classpath for typical applications.</description>
<name>yarn.application.classpath</name>
<value>$HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/share/hadoop/common/*,
$HADOOP_COMMON_HOME/share/hadoop/common/lib/*,
$HADOOP_HDFS_HOME/share/hadoop/hdfs/*,$HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*,
$YARN_HOME/share/hadoop/yarn/*,$YARN_HOME/share/hadoop/yarn/lib/*,
$YARN_HOME/share/hadoop/mapreduce/*,$YARN_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce.shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/opt/data/yarn/local</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/opt/data/yarn/logs</value>
</property>
<property>
<description>Where to aggregate logs</description>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/opt/data/yarn/logs</value>
</property>
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/user</value>
</property>
</configuration>
</code>同步配置文件
修改.bashrc环境变量,并将其同步到其他几台机器,并且source .bashrc
<code>[root@desktop1 ~]# cat .bashrc
# .bashrc
alias rm='rm -i'
alias cp='cp -i'
alias mv='mv -i'
# Source global definitions
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi
# User specific environment and startup programs
export LANG=zh_CN.utf8
export JAVA_HOME=/opt/jdk1.6.0_38
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=./:$JAVA_HOME/lib:$JRE_HOME/lib:$JRE_HOME/lib/tools.jar
export HADOOP_HOME=/opt/hadoop-2.0.0-cdh4.2.0
export HIVE_HOME=/opt/hive-0.10.0-cdh4.2.0
export HBASE_HOME=/opt/hbase-0.94.2-cdh4.2.0
export HADOOP_MAPRED_HOME=${HADOOP_HOME}
export HADOOP_COMMON_HOME=${HADOOP_HOME}
export HADOOP_HDFS_HOME=${HADOOP_HOME}
export YARN_HOME=${HADOOP_HOME}
export HADOOP_YARN_HOME=${HADOOP_HOME}
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HDFS_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export YARN_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin:$HIVE_HOME/bin
</code>修改配置文件之后,使其生效。
<code>[root@desktop1 ~]# source .bashrc </code>
将desktop1上的/opt/hadoop-2.0.0-cdh4.2.0拷贝到其他机器上
启动脚本
第一次启动hadoop需要先格式化NameNode,该操作只做一次。当修改了配置文件时,需要重新格式化
<code>[root@desktop1 hadoop]hadoop namenode -format </code>
在desktop1上启动hdfs:
<code>[root@desktop1 hadoop]#start-dfs.sh </code>
在desktop1上启动mapreduce:
<code>[root@desktop1 hadoop]#start-yarn.sh </code>
在desktop1上启动historyserver:
<code>[root@desktop1 hadoop]#mr-jobhistory-daemon.sh start historyserver </code>
查看MapReduce:
<code>http://desktop1:8088/cluster </code>
查看节点:
<code>http://desktop2:8042/ http://desktop2:8042/node </code>
检查集群进程
<code>[root@desktop1 ~]# jps 5389 NameNode 5980 Jps 5710 ResourceManager 7032 JobHistoryServer [root@desktop2 ~]# jps 3187 Jps 3124 SecondaryNameNode [root@desktop3 ~]# jps 3187 Jps 3124 DataNode 5711 NodeManager</code>

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 Win11系统无法安装中文语言包的解决方法
Mar 09, 2024 am 09:48 AM
Win11系统无法安装中文语言包的解决方法
Mar 09, 2024 am 09:48 AM
Win11系统无法安装中文语言包的解决方法随着Windows11系统的推出,许多用户开始升级他们的操作系统以体验新的功能和界面。然而,一些用户在升级后发现他们无法安装中文语言包,这给他们的使用体验带来了困扰。在本文中,我们将探讨Win11系统无法安装中文语言包的原因,并提供一些解决方法,帮助用户解决这一问题。原因分析首先,让我们来分析一下Win11系统无法
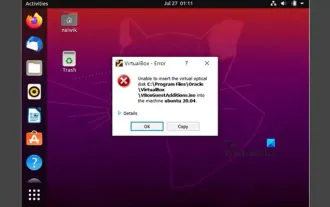 无法在VirtualBox中安装来宾添加
Mar 10, 2024 am 09:34 AM
无法在VirtualBox中安装来宾添加
Mar 10, 2024 am 09:34 AM
您可能无法在OracleVirtualBox中将来宾添加安装到虚拟机。当我们点击Devices>;InstallGuestAdditionsCDImage时,它只会抛出一个错误,如下所示:VirtualBox-错误:无法插入虚拟光盘C:将FilesOracleVirtualBoxVBoxGuestAdditions.iso编程到ubuntu机器中在这篇文章中,我们将了解当您无法在VirtualBox中安装来宾添加组件时该怎么办。无法在VirtualBox中安装来宾添加如果您无法在Virtua
 百度网盘下载成功但是安装不了怎么办?
Mar 13, 2024 pm 10:22 PM
百度网盘下载成功但是安装不了怎么办?
Mar 13, 2024 pm 10:22 PM
如果你已经成功下载了百度网盘的安装文件,但是无法正常安装,可能是软件文件的完整性发生了错误或者是残留文件和注册表项的问题,下面就让本站来为用户们来仔细的介绍一下百度网盘下载成功但是安装不了问题解析吧。 百度网盘下载成功但是安装不了问题解析 1、检查安装文件完整性:确保下载的安装文件完整且没有损坏。你可以重新下载一次,或者尝试使用其他可信的来源下载安装文件。 2、关闭杀毒软件和防火墙:某些杀毒软件或防火墙程序可能会阻止安装程序的正常运行。尝试将杀毒软件和防火墙禁用或退出,然后重新运行安装
 如何在Linux上安装安卓应用?
Mar 19, 2024 am 11:15 AM
如何在Linux上安装安卓应用?
Mar 19, 2024 am 11:15 AM
在Linux上安装安卓应用一直是许多用户所关心的问题,尤其是对于喜欢使用安卓应用的Linux用户来说,掌握如何在Linux系统上安装安卓应用是非常重要的。虽然在Linux系统上直接运行安卓应用并不像在Android平台上那么简单,但是通过使用模拟器或者第三方工具,我们依然可以在Linux上愉快地享受安卓应用的乐趣。下面将为大家介绍在Linux系统上安装安卓应
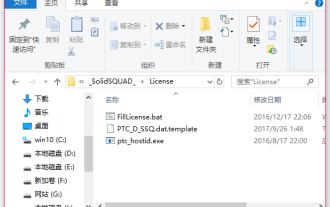 creo怎么安装-creo安装教程
Mar 04, 2024 pm 10:30 PM
creo怎么安装-creo安装教程
Mar 04, 2024 pm 10:30 PM
很多新手小伙伴还不了解creo怎么安装,所以下面小编就带来了creo安装的相关教程,有需要的小伙伴赶紧来看一下吧,希望可以帮助大家。1、打开下载好的安装包,找到License文件夹,如下图所示:2、然后把它复制到C盘的目录里面,如下图所示:3、双击进入,看看有没有许可文件,如下图所示:4、然后把许可文件复制到此文件中,如下图所示:5、在C盘的PROGRAMFILES文件中,新建一个PLC文件夹,如下图所示:6、把许可文件也复制一份进来,如下图所示:7、双击主程序的安装文件。进行安装,勾选安装新软
 如何在Ubuntu 24.04上安装Podman
Mar 22, 2024 am 11:26 AM
如何在Ubuntu 24.04上安装Podman
Mar 22, 2024 am 11:26 AM
如果您使用过Docker,则必须了解守护进程、容器及其功能。守护进程是在容器已在任何系统中使用时在后台运行的服务。Podman是一个免费的管理工具,用于管理和创建容器,而不依赖于任何守护程序,如Docker。因此,它在管理集装箱方面具有优势,而不需要长期的后台服务。此外,Podman不需要使用根级别的权限。本指南详细讨论了如何在Ubuntu24上安装Podman。更新系统我们首先要进行系统更新,打开Ubuntu24的Terminalshell。在安装和升级过程中,我们都需要使用命令行。一种简单的
 在Ubuntu 24.04上安装和运行Ubuntu笔记应用程序的方法
Mar 22, 2024 pm 04:40 PM
在Ubuntu 24.04上安装和运行Ubuntu笔记应用程序的方法
Mar 22, 2024 pm 04:40 PM
在高中学习的时候,有些学生做的笔记非常清晰准确,比同一个班级的其他人都做得更多。对于一些人来说,记笔记是一种爱好,而对于其他人来说,当他们很容易忘记任何重要事情的小信息时,则是一种必需品。Microsoft的NTFS应用程序对于那些希望保存除常规讲座以外的重要笔记的学生特别有用。在这篇文章中,我们将描述Ubuntu24上的Ubuntu应用程序的安装。更新Ubuntu系统在安装Ubuntu安装程序之前,在Ubuntu24上我们需要确保新配置的系统已经更新。我们可以使用Ubuntu系统中最著名的“a
 Win7电脑上安装Go语言的详细步骤
Mar 27, 2024 pm 02:00 PM
Win7电脑上安装Go语言的详细步骤
Mar 27, 2024 pm 02:00 PM
Win7电脑上安装Go语言的详细步骤Go(又称Golang)是一种由Google开发的开源编程语言,其简洁、高效和并发性能优秀,适合用于开发云端服务、网络应用和后端系统等领域。在Win7电脑上安装Go语言,可以让您快速入门这门语言并开始编写Go程序。下面将会详细介绍在Win7电脑上安装Go语言的步骤,并附上具体的代码示例。步骤一:下载Go语言安装包访问Go官
