

数据库和ADO

数据库语言 数据库的简易流程(数据库客户端软件和数据库服务软件的执行流程) 主键的概念 如何创建主键 如何创建外键 主外键关系的概念以及使用 数据库的主要类型 数据库的主要数据类型 使用SQL语句来创建数据库和表 约束分类 top的使用 Distinct的使用(去除
- 数据库语言
- 数据库的简易流程(数据库客户端软件和数据库服务软件的执行流程)
- 主键的概念
- 如何创建主键
- 如何创建外键
- 主外键关系的概念以及使用
- 数据库的主要类型
- 数据库的主要数据类型
- 使用SQL语句来创建数据库和表
- 约束分类
- top的使用
- Distinct的使用(去除重复数)
- 聚合函数
- 聚合函数注意事项
- between and 和 in 的使用
- like, not like 通配符(%,_,[],^)
- 空值处理:null 是什么?
- 排序(order by id asc / desc)(默认是哪一种排序?)
- 分组(group by ),单条件分组,多条件分组(分组时,要注意的事情[位置,列])
- 筛选(Having的使用),它和where的区别
- 类型转换(CAST,CONVERT)
- union,union all的使用
- 一次插入多条数据
- 字符串函数
- ADO.NET主要类
- 数据库连接字符串
- SqlConnection类的State属性
- SqlCommand类的方法:
- StatementCompleted事件的触发
- 获得刚刚插入数据库的自增id
- Sql注入攻击(避免方式?)
- 如何使用迭代生成树形菜单
- 单例模式(单例模式的创建)
- DataTable的使用
- 类SqlDataAdapter的使用(重点)
- 类SqlCommandBuilder的使用(注意:他必须操作的是有主键的数据库)
- 提取查询语句,封装SqlHelper类(不仅要会,而且要理解思想)
- SQL中的Switch语句
- SQL中的子查询
- SQL中的Exists用法
- SQL中的Any
- SQL中的All
- SQL2008 微软官方推荐分页方式
- SQL中表等值连接(内连接) inner join
- SQL中表左连接(左外连接) left join
- SQL中表右连接(右外连接) right join
- SQL中表交叉连接(两张表的乘积)
- SQL中表全连接 full join
- SQL中变量
- SQL中的事务
- 创建存储过程
- 存储过程带输出参数
- 调用存储过程
- 触发器定义
- 触发器类型:
- 触发器触发条件:
- 什么是索引
- 索引类型
- 什么是填充因子
- 什么是临时表
- 什么是局部临时表
- 什么是全局临时表
- 什么是三层结构
- 三层结构的目的
- 具体的三层是哪三层
- 三层之间的关系
- 三层结构的优缺点
- 邮件发送方法
- Excel导入导出
- MD5加密解密方法
- 读取数据库后,判断dataset里列的值是否为空
- 项目术语
- 数据库语言
-
DML(数据操作语言)
- select
- insert
- delete
- update
-
DDL(数据定义语言--建表建库等)
- creat
- drop
- alter
-
DCL(数据控制语言)
- grant
- revoke
-
DML(数据操作语言)
- 数据库的简易流程(数据库客户端软件和数据库服务软件的执行流程)
- 安装时有一个客户端管理软件和一个服务器。我们平常操作的是客户端软件,发送脚本到服务器DMSM(数据库服务器),服务器分析和解析并展示执行结果。
- 主键的概念
- 唯一的标识一行数据操作
- 可以作为其他表的外键来引用
- 业务主键:有意义(例:身份证号)
- 逻辑主键:唯一的意义就是标识一行
- 如何创建主键
-
ALTER TABLE [dbo].[OperateType]
ADD CONSTRAINT [PK_OperateType]
PRIMARY KEY CLUSTERED ([Id] ASC);
GO
-
- 如何创建外键
-
ALTER TABLE [dbo].[RoleAction]
ADD CONSTRAINT [FK_RoleAction_Role]
FOREIGN KEY ([Role_RoleId])
REFERENCES [dbo].[RoleInfo]
([RoleId])
ON DELETE NO ACTION ON UPDATE NO ACTION;
GO
-
- 主外键关系的概念以及使用
-
作用
- 可以优化查询效率
- 减少数据冗余
- 维护方便
- 两张聊存在依赖数据时,就可以使用主外键来解决,其中将依赖列作为主键的就叫作:主键表;另一个就叫作外键表,外键表的外键列数据取自主键表的主键
-
主外键约束
-
为什么
- 为了避免两张表的主外键数据出现不一致的情况,需要建立主外键约束关系
-
作用
- 当两张表数据修改时出现主外键数据不一致,则报错,拒绝修改
-
为什么
-
作用
- 数据库的主要类型
- 网状数据库、层次数据库和关系数据库
- 数据库的主要数据类型
- char类型:当储存的数据小于长度时,会自动用空格来补充
- Nchar类型:使用Unicode编码,任意字符都占两个字节
- varchar类型:当储存的数据小于长度时,不会自动用空格来表示
- datetime类型:储存日期时间数据
- 使用SQL语句来创建数据库和表
-
创建数据库
-
create database MySchool
on
(
--括号一定是圆括号
name='MySchool_data',--数据库名称
filename='d:\MySchool_data.mdf',--物理文件名
size=5mb,--初始大小
maxsize=10mb,--最大大小
filegrowth=15% --主文件增长率
)
log on
(
name='MySchool_log',--日志文件名
filename='d:\MySchool_log.ldf',--日志物理文件名
maxsize=4mb,--最大大小
size=2mb,
filegrowth=1mb
)
go
-
-
创建表
-
create table Student
(--创建学生信息表
sId int identity(1,1) primary key,--自动编号
sClassId int not null, --班级外键
sName nvarchar(50) not null,
sAge int not null,
sNo numeric(18,0),--身份证号,十八位数字,小数为
sSex char(2) not null,
sEmail varchar(50)
)
-
-
创建数据库
- 约束分类
-
非空约束
- alter table Employees alter column EmpName varchar(50) not null
-
主键约束
-
alter table Score
add constraint PK_Score primary key(sId)
-
-
唯一约束
-
alter table student
add constraint UQ_student unique(sNo)
-
-
默认约束
-
alter table student
add constraint DF_student default('男') for sSex
-
-
检测约束
-
alter table student
add constraint CK_student check(sAge >=18 and sAge 100)
-
-
外键约束
-
alter table Employees
add constraint FK_DeptId_DepId foreign key(DeptId) references Department(DepId)
-
-
非空约束
- top的使用
-
select top 2 * from teacher
-
select top 20 percent * from teacher--按百分比算行数,如果出现小数,则+1(类似天花板函数celling)
-
- Distinct的使用(去除重复数)
-
select distinct(age) from teacher --求出不重复的age
-
select distinct age,salary from teacher --求出不重复的age和salary的组合(相当于将两个列的值加在一起的值不重复)
-
- 聚合函数
-
MAX(最大数)
- SELECT max(UserId),UserId from dbo.UserInfo GROUP BY UserId
-
MIN(最小数)
- SELECT min(UserId),UserId from dbo.UserInfo GROUP BY UserId
-
AVG(平均数)
- SELECT avg(UserId),UserId from dbo.UserInfo GROUP BY UserId
-
SUM(和)
- SELECT sum(UserId),UserId from dbo.UserInfo GROUP BY UserId
- COUNT(计数)
- SELECT COUNT(UserId),UserId from dbo.UserInfo GROUP BY UserId
-
MAX(最大数)
- 聚合函数注意事项
- 聚合函数对NULL值不计算
- 聚合函数的结果集是单个的值,没办法与多个值的结果集集合
-
不能整除的情况
- 该列是小数列:如果除出来是小数,则返回带小数的结果
- 该列是整数列:如果除出来是小数,也是直接当整数算,不会自动+1
- between and 和 in 的使用
-
betwenn and
- 求两个值的区间,推荐使用between and
- select * from UserInfo where ID between 40 and 50
-
in
- 当使用子查询配合in关键字时,子查询的结果集必须只有一个列,而且列的类型必须和条件列类型一直
- select * from UserInfo Where ID in (40,41)
- select * from teacher where id in (select id from Score where English>98 and Math> 98)
-
betwenn and
- like, not like 通配符(%,_,[],^)
- ^只有MSSQLServer支持,其他DBMS用not like,且只能放在[]里用
- not like 不取like的值
- _ 代表单个任意字符;
-
% 代表任意长度任意字符
- Select * from student where sName like '张%'
- [] 代表取值范围内的单个字符
- ^ 取非符号,必须和[]连用
- 空值处理:null 是什么?
-
查询列中null的值用is关键字
- select *from teacher where name is NULL
-
isnull函数
- 如果第一个参数为null,则使用第二个参数作为返回值,否则,返回第一个参数
- SELECT ISNULL (Email ,'aaa')as Email from UserInfo
-
查询列中null的值用is关键字
- 排序(order by id asc / desc)(默认是哪一种排序?)
- order by 子句要放到where子句之后
-
asc--默认是升序
- select * from UserInfo where Sort=0 order by id asc
-
desc--降序
- select * from UserInfo order by Phone desc,ID desc
- 多条件排序时,如上,当Phone中有相等的值,那么这些值按ID排序
- 分组(group by ),单条件分组,多条件分组(分组时,要注意的事情[位置,列])
-
根据性别统计男女的人数
- select count(*) gender from teacher group by gender
- group by 子句必须放到where语句之后,group by 与 order by 都是对筛选后的数据进行处理,而where是用来筛选数据的
-
多条件分组
- 分组条件,是age和gender列的组合,只有当age和gender一样的值时,才分为一组
- select count(*),age, gender from teacher group by age,gender
- 分组一般和聚合函数使用的
- 分组的结果是组信息,与表里的当行信息无关
- 一旦出现分组,前面要么是聚合函数,要么是分组的条件
-
根据性别统计男女的人数
- 筛选(Having的使用),它和where的区别
- having是group by的条件对分组后的数据进行筛选(与where类似,都是筛选,只不过having是用来筛选分组后的组)
- 在where中不能使用聚合函数,必须使用having,having要位于group by之后
- having的使用几乎是与where一样的,也可以用in
- select sClassId,count(sName) from student group by sClassId having count(sName)>3
- 类型转换(CAST,CONVERT)
-
cast
- select cast(salary as int) from teacher
-
convert
- select convert(int,salary) from teacher
-
cast
- union,union all的使用
- 是对两个集合操作的,两个集合必须具有相同的列数,列具有相同的数据类型(至少能隐式转换的),最终输出的集合的列名由第一个集合的列名来确定(可以用来连接多个结果)
- 要union的两个结果集的列数必须一样
- 要连接的两个列的类型鼻血一直(或者类型兼容,比如varchar和nchar)
- union默认去除了结果集中重复数据
- 而union all 不会删除重复的数据;(因此,union all 的效率要比union的效果高一些)
- 一次插入多条数据
-
insert into Score(studentId,english,math)
select 1,80,100 union
select 1,80,100 union
select 3,50,59 union all
select 4,66,89 union
select 5,59,100
-
- 字符串函数
-
LEN()
-
select len('字符串的长度')
- 结果是6
- LEN返回的是去掉尾部空格后的字符数
-
select len('字符串的长度')
-
Datalength()
-
select datalength('字符串的长度')
- 结果是12
- 返回的是包含尾部空格的字符串的字节数
-
select datalength('字符串的长度')
-
LOWER()
- select lower('JJJJJj')
- 转小写
-
UPPER()
- 转大写
-
LTRIM()
- 去除左边空格
-
RTRIM()
- 去除右边空格
-
LEFT()
- 从左边取指定长度字符串
-
RIGHT()
- 从右边取指定长度字符串
-
SUBSTRING(string,start , length)
- 从指定位置取指定长度字符串
-
LEN()
- ADO.NET主要类
-
Connection
- 主要是开启程序和数据库之间的连接,没有利用连接对象将数据库打开,是无法从数据库中取得数据的
-
Close和Dispose的区别
- Close以后还可以Open,Dispose以后则不能再用
-
Command
- 主要可以用来对数据库发出一些指令,例如可以对数据库下达查询、新增、修改、删除数据等指令,以及调用存在数据库中的存储过程等,这个对象是架构在Connection对象上,也就是Command对象是通过连接到数据源
-
DataAdapter
- 主要是在数据源以及DataSet之间执行数据传输的工作,它可以透过Command对象下达命令后,并将取得的数据放入DataSet对象中,这个对象是架构在Command对象上,并提供了许多配合DataSet使用的功能
-
DataSet
- 这个对象可以视为一个暂存区(Cache),可以把从数据库中查询到的数据保存起来,试着可以将整个数据库显示出来,DataSet是放在内存中的,DataSet的能力不只是可以存储多个Table而已,还可以透过DataAdapter对象取得一些例如主键等的数据结构,并可以记录数据表间的关联。DataSet对象可以说是ADO.NET中重量级的对象,这个对象架构在DataAdapter对象上,本身不具有和数据源沟通的能力,也就是说我们是将DataAdapter对象当作DataSet对象及数据源间传输数据的桥梁,DataSet包含诺干DataTable,DataTable包含诺干DataRow
-
DataReader
- 当我们只需要循序的读取数据而不需要其它操作时,可以使用 DataReader 对象。DataReader 对象只是一次一笔向下循序的读取数据源中的数据,这些数据是存在数据库服务器中的,而不是一次性加载到程序的内存中的,只能(通过游标)读取当前行的数据,而且这些数据是只读的,并不允许作其它的操作。因为 DataReader 在读取数据的时候限制了每次只读取一笔,而且只能只读,所以使用起来不但节省资源而且效率很好。使用DataReader 对象除了效率较好之外,因为不用把数据全部传回,故可以降低网络的负载。 ADO.NET 使用 Connection 对象来连接数据库,使用 Command 或 DataAdapter 对象来执行SQL 语句,并将执行的结果返回给 DataReader 或 DataAdapter ,然后再使用取得的DataReader 或 DataAdapter 对象操作数据结果。
-
Connection
- 数据库连接字符串
- server=.;database='dbName';uid=sa;pwd=123
- SqlConnection类的State属性
- 是判断数据库连接状态的一组枚举值
- SqlCommand类的方法:
-
ExecuteNonQuery()
- 执行非查询语句(增、删、改),返回受影响函数
-
ExecuteScalar()
- 返回查询结果集的首行首列,是一个Object类型。
-
ExecuteReader()
- 返回一个游标指针,然后用read()方法一行一行的读。性能很好。
-
ExecuteNonQuery()
- StatementCompleted事件的触发
- 每条SQL语句执行完后会触发
- 获得刚刚插入数据库的自增id
- 方法一:string strSql="Insert into Student(name,age,cid) values ('{0}','{1}','{2}'); Select @@identity;"
- 方法二:string strSql="Insert into Student(name,age,cid) output inserted.id values('{0}','{1}','{2}') "
- Sql注入攻击(避免方式?)
- 参数化查询,SqlParameter
- 如何使用迭代生成树形菜单
-
void BuildTree(TreeNode node, ListCategory> list)
-
{
//获得父元素的ID
int pId = Convert.ToInt32(node.Tag);
foreach (Category model in list)
{
//找出集合中 父ID 和传入参数一致的
if (model.TParentId == pId)
{
//创建子节点
TreeNode sonNode = new TreeNode(model.TName);
//将子节点自己的ID存入 节点的 TAG中
sonNode.Tag = model.TId;
//将子节点 添加到父节点中
node.Nodes.Add(sonNode);
//迭代 调用(看看子节点还有没有子节点)
BuildTree(sonNode, list);
}
}
}
- 单例模式(单例模式的创建)
- 关闭要实现单例模式的类的构造函数(私有化构造函数)
- 在类中添加一个私有的类的静态变量
- 在类中添加一个共有的方法,返回当前的静态变量,在方法中判断静态变量是否为null,如果为null则先new在返回
public Person GetSingleInstance()
{
//在多线程情况下,需要 加锁
//这里:第一,直接锁当前的对象; 第二,定义一个线程 锁的标识volatile,然后锁住标识
lock(_mySinglePerson)
{
if(_mySinglePerson == null || _mySinglePerson.IsDisPosed)
{
_mySinglePerson = new Person();
}
}
return _mySinglePerson;
}
- DataTable的使用
-
DataTable dt = new DataTable(); foreach(DataRow row in dt.Rows) { string str = row["columnName"].ToString(); .... }
-
- 类SqlDataAdapter的使用(重点)
- Fill()方法
- 注意:SqlDataAdapter的内部还是使用了SqlDataRader去读取数据,只不过读取的过程微软帮我们封装了
- 类SqlCommandBuilder的使用(注意:他必须操作的是有主键的数据库)
- 往里边传入一个DataAdapter对象,然后可以用相应方法直接执行对表的操作,使用相当简单,功能也很强大,主要是微软为我们做了一系列封装,简化了程序员的操作(但一般我们都不使用这种方式对数据表进行操作)
-
<span>//SQL命令生成助手(适配器)</span> SqlCommandBuilder scb<span>=</span><span><strong>new</strong></span><span> </span>SqlCommandBuilder(da); <span>//适配器在助手生成的SQL语句帮助下,成功的修改类数据库 da.Update(ds,"tempTable");</span> MessageBox.Show(<span>"修改成功"</span>)
-
提取查询语句,封装SqlHelper类(不仅要会,而且要理解思想)
- SQL中的Switch语句
-
直接对列进行值的判断
- then的值必须是同一种类型(因为列的类型只能有一个)
-
select pId,
case pTypeId
when 1 then 'a'
when 2 then 'b'
else 'c'
end,
pName from PhoneNum
-
一般用来为列的取值范围
- case不一定非要和列在一起判断
-
select studentId,成绩=(
case
when english between 90 and 100 then 'A'
when english between 80 and 89 then 'B'
when english between 70 and 79 then 'C'
when english between 60 and 69 then 'D'
when english 60 then 'E'
else '缺考'
end
)
from score
-
直接对列进行值的判断
- SQL中的子查询
- 在结果集的基础上,再次查询,一定要给结果集取别名,否则会报错
- select * from (select * from bc) as temp
- SQL中的Exists用法
-
先执行的是主查询,然后再执行子查询,将匹配行的数据显示出来
- select * from tbl where exists(select * from phonType where tbl.pid=phonType.pid)
-
判断结果集是否存在,但效率低
-
if exists(select * from tbl where ptId=1)
select 1
else
select 2
-
-
先执行的是主查询,然后再执行子查询,将匹配行的数据显示出来
- SQL中的Any
-
Any相当于条件是很多个or
- select * from Phone where pTypeID=any(select pType from b)
- select * from Phone where pTypeID=1 or pTypeID=2
-
Any相当于条件是很多个or
- SQL中的All
-
All相当于条件是很多个and
- select * from Phone where pTypeId=all(select pTypeId from b)
- select * from Phone where pTypeId=1 and pTypeId=2
- any、in、all匹配结果集时,结果集只能有一个列
-
All相当于条件是很多个and
- SQL2008 微软官方推荐分页方式
-
select * from(
select row_number() over(order by ar_id)as num,*from area
)as t where runm between 10 and 14
-
- SQL中表等值连接(内连接) inner join
- 任何一方都必须满足连接条件,如果有一方不满足连接条件就不显示
- select * from Phone inner join PhoneType on n.pTypeId=t.ptId
- SQL中表左连接(左外连接) left join
- 保证左边的数据都有,根据左边数据匹配,显示Join左边表的所有记录,右侧表中符合条件的显示,不符合条件的就显示null
- select * from Phone n left join PhoneType t on n.pTypeId=t.ptId
- SQL中表右连接(右外连接) right join
- 保证右边的数据都有,根据右边数据匹配
- select * from PhoneNum n right join PhoneType t on n.pTypeId = t.ptId
- SQL中表交叉连接(两张表的乘积)
- select * from student cross join Score
- SQL中表全连接 full join
- 左右两边的数据都进行匹配,相当于左连接和右连接相加和inner join刚好相反
-
select * from PhoneNum n full join PhoneType t on n.pTypeId = t.ptId
- SQL中变量
-
声明变量
- declare @age int
-
变量赋值
- set @age=3
-
声明并赋值
- select @age=3
-
如果表数据出现多行,则将最后一行的列赋值给变量
- select @age=age from Student
-
输出变量的值
- print @age
-
声明变量
- SQL中的事务
- begin transaction 开始事务
- rollback transaction 回滚事务
- commit transaction 提交事务
-
银行事务转账例子
-
declare @err int
set @err = 0
begin transaction
begin
print '开始事务'
update bank set balance=balance-1000 where cid='0001'
set @err=@err+@@ERROR
update bank set balance=balance + 1000 where cid='0002'
set @err=@err+@@ERROR
if(@err>0)
begin
rollback transaction
print '回滚事务'
end
else
begin
commit transaction
print '提交事务'
end
end
-
- 创建存储过程
-
create procedure usp_transferMoney
@intPerson varchar(20)
@outPerson varchar(20) '123' --可以给默认值,当参数有默认值的时候,执行的时候可以不传该参数
@abcPerson varchar(20)
as
select @intPerson,@outPerson,@abcPerson
-
- 存储过程带输出参数
-
--登陆成功返回用户名不存在返回密码错误返回登陆超过次返回试登陆次数超过次返回
--drop proc login
create proc Login
@result int output,
@times int output,
@name varchar(10),
@pwd varchar(10)
as
select @times = uTimes from [user] where uName=@name
if(@times>=3)
begin
set @result = 4
return
end
if exists(select * from [user] where uName=@name)
begin
if exists(select * from [user] where uName=@name and uPwd=@pwd)
begin
set @result = 1
end
else --密码错误返回
begin
set @result = 3
update [user] set uTimes= uTimes+1 where uName=@name
select @times = uTimes from [user] where uName=@name
end
end
else --用户名不存在返回
begin
set @result = 2
end
insert into [user] values('admin','000000',0)
update [user] set uTimes=0
select * from [user]
declare @times int,@r int
exec Login @r output,@times output ,'admin111','admin'
print 'times'+cast(@times as varchar)
print 'result'+ cast(@r as varchar)
-
- 调用存储过程
-
无参数的存储过程调用
- Exec usp_upGrade
-
有参数的存储过程两种调用法
- EXEC usp_upGrade2 60,55 ---按次序
- EXEC usp_upGrade2 @english=55,@math=60 --参数名
-
参数名参数有默认值时
-
EXEC usp_upGrade2 --都用默认值
-
EXEC usp_upGrade2 1 --第一个用默认值
-
EXEC usp_upGrade2 1,5 --不用默认值
-
-
无参数的存储过程调用
- 触发器定义
- 触发器是一种特殊的存储过程
- 触发器不能传参,通过事件进行触发执行
-
针对tbL_abc表的新增之后的触发器
-
Create Trigger triggerName on tbL_abc
after
insert
as
begin
select * from inserted --保存了引发新增触发器的新增数据,只能在触发器中访问
end
-
- 触发器类型
- after和for是在执行操作后触发
- instead of 是在操作之前触发(替换触发器),但不会执行原语句
- 触发器触发条件
- update
- insert
- delete
- 什么是索引
- 就是为某个表,某个列建立一个查找目录,如果没有目录,汉语字典就要一页一页的翻,有了目录直接翻目录,快速定位到查找位置
- 索引类型
-
聚集索引(拼音目录)
- 数据的排列顺序,按照聚集索引排列(控制表的物理顺序)
- 每个表只能建立一个聚集索引
-
非聚集索引(偏旁部首目录)
- 非聚集索引不会改变表的物理顺序
- 每个表可以建立多个非聚集索引
-
聚集索引(拼音目录)
- 什么是填充因子
- 就是为每页索引设置预留空间,在将来加入新索引的时候,就只需要更新当前索引页,而不需要更新索引树
- 如每页索引1M大小,当填充因子设置为60%,在每页只存放60%的数据,剩下40%留给将来要加入的索引项使用
- 什么是临时表
- 是存在缓存中,而不是写在文件中
- 可以在系统数据库→tempdb中找到
- 什么是局部临时表
- 生命周期在当前会话,当前会话结束就销毁临时表
- 相当于C#的局部成员
- 创建时表名前加一个#号
-
create table #tempUsers
(
id int identity(1,1),
name varchar(20)
)
- 什么是全局临时表
- 多个用户可以共享这个全局临时表
- 当所有会话都退出的时候,这个全局临时表才会被销毁
- 相当与C#的static 静态成员
- 创建时,表名前面加两个##号
-
create table ##tempUsers
(
id

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 Go语言如何实现数据库的增删改查操作?
Mar 27, 2024 pm 09:39 PM
Go语言如何实现数据库的增删改查操作?
Mar 27, 2024 pm 09:39 PM
Go语言是一种高效、简洁且易于学习的编程语言,因其在并发编程和网络编程方面的优势而备受开发者青睐。在实际开发中,数据库操作是不可或缺的一部分,本文将介绍如何使用Go语言实现数据库的增删改查操作。在Go语言中,我们通常使用第三方库来操作数据库,比如常用的sql包、gorm等。这里以sql包为例介绍如何实现数据库的增删改查操作。假设我们使用的是MySQL数据库。
 PHP MQTT客户端开发指南
Mar 27, 2024 am 09:21 AM
PHP MQTT客户端开发指南
Mar 27, 2024 am 09:21 AM
MQTT(MessageQueuingTelemetryTransport)是一种轻量级的消息传输协议,通常用于物联网设备之间的通信。PHP是一种常用的服务器端编程语言,可以用来开发MQTT客户端。本文将介绍如何使用PHP开发MQTT客户端,并包含以下内容:MQTT协议的基本概念PHPMQTT客户端库的选取和使用实例:使用PHPMQTT客户端发布和
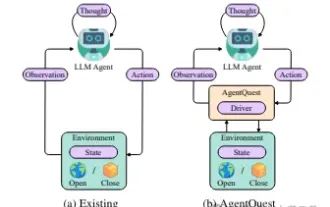 探索智能体的边界:AgentQuest,一个全面衡量和提升大型语言模型智能体性能的模块化基准框架
Apr 11, 2024 pm 08:52 PM
探索智能体的边界:AgentQuest,一个全面衡量和提升大型语言模型智能体性能的模块化基准框架
Apr 11, 2024 pm 08:52 PM
基于大模型的持续优化,LLM智能体——这些强大的算法实体已经展现出解决复杂多步骤推理任务的潜力。从自然语言处理到深度学习,LLM智能体正逐渐成为研究和工业界的焦点,它们不仅能理解和生成人类语言,还能在多样的环境中制定策略、执行任务,甚至使用API调用和编码来构建解决方案。在这种背景下,AgentQuest框架的提出具有里程碑意义,它不仅仅是一个LLM智能体的评估和进步提供了一个模块化的基准测试平台,而且通过其易于扩展的API,为研究人员提供了一个强大的工具,以更细粒度地跟踪和改进这些智能体的性能
 在PHP中使用MySQLi建立数据库连接的详尽教程
Jun 04, 2024 pm 01:42 PM
在PHP中使用MySQLi建立数据库连接的详尽教程
Jun 04, 2024 pm 01:42 PM
如何在PHP中使用MySQLi建立数据库连接:包含MySQLi扩展(require_once)创建连接函数(functionconnect_to_db)调用连接函数($conn=connect_to_db())执行查询($result=$conn->query())关闭连接($conn->close())
 Hibernate 如何实现多态映射?
Apr 17, 2024 pm 12:09 PM
Hibernate 如何实现多态映射?
Apr 17, 2024 pm 12:09 PM
Hibernate多态映射可映射继承类到数据库,提供以下映射类型:joined-subclass:为子类创建单独表,包含父类所有列。table-per-class:为子类创建单独表,仅包含子类特有列。union-subclass:类似joined-subclass,但父类表联合所有子类列。
 iOS 18 新增'已恢复”相册功能 可找回丢失或损坏的照片
Jul 18, 2024 am 05:48 AM
iOS 18 新增'已恢复”相册功能 可找回丢失或损坏的照片
Jul 18, 2024 am 05:48 AM
苹果公司最新发布的iOS18、iPadOS18以及macOSSequoia系统为Photos应用增添了一项重要功能,旨在帮助用户轻松恢复因各种原因丢失或损坏的照片和视频。这项新功能在Photos应用的"工具"部分引入了一个名为"已恢复"的相册,当用户设备中存在未纳入其照片库的图片或视频时,该相册将自动显示。"已恢复"相册的出现为因数据库损坏、相机应用未正确保存至照片库或第三方应用管理照片库时照片和视频丢失提供了解决方案。用户只需简单几步
 大模型下B端前端代码辅助生成的思考与实践
Apr 18, 2024 am 09:30 AM
大模型下B端前端代码辅助生成的思考与实践
Apr 18, 2024 am 09:30 AM
一、背景重构工作中,代码规范:B端前端开发过程中开发者总会面临重复开发的痛点,很多CRUD页面的元素模块基本相似,但仍需手动开发,将时间花在简单的元素搭建上,降低了业务需求的开发效率,同时因为不同开发者的代码风格不一致,使得迭代时其他人上手成本较高。AI代替简单脑力:AI大模型的不断发展,已经具备简单的理解能力,并可以进行语言到指令的转换。对于基础页面搭建这样的通用指令可满足日常基础页面搭建的需求,提升通用场景业务开发效率。二、生成链路一览B端页面列表、表单、详情都支持生成,链路大概可分为以下几
 深入解析HTML如何读取数据库
Apr 09, 2024 pm 12:36 PM
深入解析HTML如何读取数据库
Apr 09, 2024 pm 12:36 PM
HTML无法直接读取数据库,但可以通过JavaScript和AJAX实现。其步骤包括建立数据库连接、发送查询、处理响应和更新页面。本文提供了利用JavaScript、AJAX和PHP来从MySQL数据库读取数据的实战示例,展示了如何在HTML页面中动态显示查询结果。该示例使用XMLHttpRequest建立数据库连接,发送查询并处理响应,从而将数据填充到页面元素中,实现了HTML读取数据库的功能。
