

解剖SQLSERVER 第十六篇 OrcaMDF RawDatabase

解剖 SQLSERVER 第十六篇 OrcaMDF RawDatabase --MDF文件的瑞士军刀(译) http://improve.dk/orcamdf-rawdatabase-a-swiss-army-knife-for-mdf-files/ 当我最初开始开发OrcaMDF的时候我只有一个目标,比市面上大部分的书要获取MDF文件内部的更深层次的知识
解剖SQLSERVER 第十六篇 OrcaMDF RawDatabase --MDF文件的瑞士军刀(译)
http://improve.dk/orcamdf-rawdatabase-a-swiss-army-knife-for-mdf-files/
当我最初开始开发OrcaMDF的时候我只有一个目标,比市面上大部分的书要获取MDF文件内部的更深层次的知识
随着时间的推移,OrcaMDF确实做到了。在我当初没有计划的时候,OrcaMDF 已经可以解析系统表,元数据,甚至DMVs。我还做了一个简单UI,让OrcaMDF 更加容易使用。
这很好,但是带来的代价是软件非常复杂。为了自动解析元数据 例如schemas, partitions, allocation units 还有其他的东西,更不要提对于堆表和索引的细节的抽象层了,抽象层需要很多代码并且需要更多的数据库了解。鉴于不同SQLSERVER版本之间元数据的改变,OrcaMDF 目前仅支持SQL Server 2008 R2。然而,数据结构是相对稳定的,元数据的存储方式只有一点不同,使用DMVs暴露数据等等。要让OrcaMDF 正常运行,需要元数据是完好无损的,这就导致当SQLSERVER损坏的时候OrcaMDF 也是一样的。遇到损坏的boot page吗?无论SQLSERVER还是 OrcaMDF 都不能解析数据库
向RawDatabase问好
我在憧憬OrcaMDF 的未来 和如何使用他才是最有用的。我能够不断增加新的特性进去以使SQLSERVER支持什么功能他也支持,最终使得他能100%解析MDF文件。但是意义何在?当然,这是一个很好的学习机会,不过重点是,你使用软件读取数据,SQLSERVER能比你做得更好。所以,该如何选择?
RawDatabase, 参照Database 类,他不会尝试解析任何东西除非你让他去解析。
他不会自动解析schemas。他不知道系统表。他不知道DMVs。然而他知道SQLSERVER数据结构和给他一个接口他可以直接读取MDF文件。
让RawDatabase 只解析数据结构意味着他可以跳过损坏的系统表或者损坏的数据
例子
这个工具还在开发的早起,不过让我展示一下使用RawDatabase能够做什么东西。
当我运行LINQPad上的代码,他很容易的显示出结果,结果只是标准的.NET 对象。
所有的例子都在AdventureWorks 2008R2 LT (Light Weight)数据库上运行
获取单个页面
很多时候,我们只需要解析单个页面
<span>//</span><span> Get page 197 in file 1</span> <span>var</span> db = <span>new</span> RawDatabase(<span>@"</span><span>C:\AWLT2008R2.mdf</span><span>"</span><span>); db.GetPage(</span><span>1</span>, <span>197</span>).Dump();

解析页头
现在我们获取到页面,我们如何把页头dump出来
<span>//</span><span> Get the header of page 197 in file 1</span> <span>var</span> db = <span>new</span> RawDatabase(<span>@"</span><span>C:\AWLT2008R2.mdf</span><span>"</span><span>); db.GetPage(</span><span>1</span>, <span>197</span>).Header.Dump();

解析行偏移阵列
就像页头那样,我们也可以把页尾的行偏移阵列条目dump出来
<span>//</span><span> Get the slot array entries of page 197 in file 1</span> <span>var</span> db = <span>new</span> RawDatabase(<span>@"</span><span>C:\AWLT2008R2.mdf</span><span>"</span><span>); db.GetPage(</span><span>1</span>, <span>197</span>).SlotArray.Dump();

解析数据记录
当获取到行偏移条目的原始数据,你通常想看一下数据行记录的内容。幸运的是,这也很容易做到
<span>//</span><span> Get all records on page 197 in file 1</span> <span>var</span> db = <span>new</span> RawDatabase(<span>@"</span><span>C:\AWLT2008R2.mdf</span><span>"</span><span>); db.GetPage(</span><span>1</span>, <span>197</span>).Records.Dump();

从记录中检索数据
一旦你得到记录,你现在可以利用FixedLengthData 或者 VariableLengthOffsetValues 属性
去获取原始的定长数据内容和变长数据内容。然而,你肯定只想获取到实际的已解析的数据值。
对于解析,OrcaMDF会帮你解析,你只需要为他提供schema.
<span>//</span><span> Read the record contents of the first record on page 197 of file 1</span>
<span>var</span> db = <span>new</span> RawDatabase(<span>@"</span><span>C:\AWLT2008R2.mdf</span><span>"</span><span>);
RawPrimaryRecord firstRecord </span>= (RawPrimaryRecord)db.GetPage(<span>1</span>, <span>197</span><span>).Records.First();
</span><span>var</span> values = RawColumnParser.Parse(firstRecord, <span>new</span><span> IRawType[] {
RawType.Int(</span><span>"</span><span>AddressID</span><span>"</span><span>),
RawType.NVarchar(</span><span>"</span><span>AddressLine1</span><span>"</span><span>),
RawType.NVarchar(</span><span>"</span><span>AddressLine2</span><span>"</span><span>),
RawType.NVarchar(</span><span>"</span><span>City</span><span>"</span><span>),
RawType.NVarchar(</span><span>"</span><span>StateProvince</span><span>"</span><span>),
RawType.NVarchar(</span><span>"</span><span>CountryRegion</span><span>"</span><span>),
RawType.NVarchar(</span><span>"</span><span>PostalCode</span><span>"</span><span>),
RawType.UniqueIdentifier(</span><span>"</span><span>rowguid</span><span>"</span><span>),
RawType.DateTime(</span><span>"</span><span>ModifiedDate</span><span>"</span><span>)
});
values.Dump();</span>
RawColumnParser.Parse方法做的事情是 跟他一个schema,他帮你自动将raw bytes转换为Dictionary
而value就是数据列的实际值,例如int,short,guid,string等等。让你的用户给定schema, OrcaMDF 可以跳过大量的依赖的元数据进行解析,因此可以忽略可能的元数据错误带来的数据读取失败。
由于页头已经给出了 NextPageID 和 PreviousPageID属性 ,这能够让软件简单的遍历链表中的所有页面,并解析这些页面里面的数据 --他基本上是根据给定的allocation unit来进行扫描
过滤页面
除非检索一个特定的页面,RawDatabase 也有一个页面属性能够枚举数据库中的所有页面。
使用这个属性,举个例子,获取数据库中所有的IAM页面的列表
<span>//</span><span> Get a list of all IAM pages in the database</span>
<span>var</span> db = <span>new</span> RawDatabase(<span>@"</span><span>C:\AWLT2008R2.mdf</span><span>"</span><span>);
db.Pages
.Where(x </span>=> x.Header.Type ==<span> PageType.IAM)
.Dump();</span>
并且由于这是使用LINQ技术,这很容易去设计你想要的属性。
举个例子,你可以获取所有的 index pages 和他们的 slot counts 就像这样:
<span>//</span><span> Get all index pages and their slot counts</span>
<span>var</span> db = <span>new</span> RawDatabase(<span>@"</span><span>C:\AWLT2008R2.mdf</span><span>"</span><span>);
db.Pages
.Where(x </span>=> x.Header.Type ==<span> PageType.Index)
.Select(x </span>=> <span>new</span><span> {
x.PageID,
x.Header.SlotCnt
}).Dump();</span>
或者假设你想获得如下条件的页面
1、页面里面至少有一条记录
2、free space空间至少有7000 bytes
下面是page id, free count, record count 和 平均记录大小的输出
<span>var</span> db = <span>new</span> RawDatabase(<span>@"</span><span>C:\AWLT2008R2.mdf</span><span>"</span><span>);
db.Pages
.Where(x </span>=> x.Header.FreeCnt > <span>7000</span><span>)
.Where(x </span>=> x.Header.SlotCnt >= <span>1</span><span>)
.Where(x </span>=> x.Header.Type ==<span> PageType.Data)
.Select(x </span>=> <span>new</span><span> {
x.PageID,
x.Header.FreeCnt,
RecordCount </span>=<span> x.Records.Count(),
RecordSize </span>= (<span>8096</span> - x.Header.FreeCnt) /<span> x.Records.Count()
}).Dump();</span>
最后一个例子,,假设你只有一个MDF文件并且你已经忘记了有哪些对象存储在MDF文件里面。
不要紧,我们只需要查询系统表sysschobjs !sysschobjs 系统表包含了所有对象的数据
并且幸运的是,他的object ID 是 34。利用这些信息,我们可以把所有属于object ID 34的数据页面
过滤出来,并且从这些页面里读取记录并只需要解析这个表的前两列(你可以定义一个分部schema, 只要你在最后忽略列)
最后我们只需要把名称dump出来(当然我们可以把表里的所有列都查询出来,如果我们想的话)
<span>SELECT</span> <span>*</span> <span>FROM</span> sys.sysschobjs

<span>var</span> db = <span>new</span> RawDatabase(<span>@"</span><span>C:\AWLT2008R2.mdf</span><span>"</span><span>);
</span><span>var</span> records =<span> db.Pages
.Where(x </span>=> x.Header.ObjectID == <span>34</span> && x.Header.Type ==<span> PageType.Data)
.SelectMany(x </span>=><span> x.Records);
</span><span>var</span> rows = records.Select(x => RawColumnParser.Parse((RawPrimaryRecord)x, <span>new</span><span> IRawType[] {
RawType.Int(</span><span>"</span><span>id</span><span>"</span><span>),
RawType.NVarchar(</span><span>"</span><span>name</span><span>"</span><span>)
}));
rows.Select(x </span>=> x[<span>"</span><span>name</span><span>"</span>]).Dump();
兼容性
可以看到 RawDatabase并不依赖于元数据,这很容易兼容多个版本的SQLSERVER。
因此,我很高兴的宣布:RawDatabase 完全兼容SQL Server 2005, 2008, 2008R2 , 2012.
这也有可能兼容2014,不过我还未进行测试。说到测试,所有的单元测试都是自动运行的
在测试期间使用AdventureWorksLT for 2005, 2008, 2008R2 and 2012 。
现在有一些测试demo来让OrcaMDF RawDatabase去解析AdventureWorks LT 数据库里面每个表的每条记录
数据损坏
其中一个有趣的使用RawDatabase 的方法是用来附加损坏的数据库。你可以检索特定object id的所有页面然后硬解析每个页面
无论他们是否是可读的。如果元数据损坏,你可以忽略他,你手工提供schema (输入表的每个列的列名)并且只需要沿着页面链表
或者解析IAM页面去读取堆表里面的数据。接下来的几个星期我将会 写一些关于OrcaMDF RawDatabase 的使用场景的博客,其中包括数据损坏
源代码和反馈
我非常兴奋因为最新的RawDatabase 已经添加到OrcaMDF 里面并且我希望不单只只有我一个见证他的威力。
如果你也想试一试,或者有任何想法,建议或者其他反馈,我都很乐意接受。
如果你想试用,在GitHub上签出OrcaMDF项目。一旦这个工具做得比较完美了,我会把他放上去NuGet 。
就好像OrcaMDF一样,在GPL v3 licensed 下发布
第十六篇完

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 sqlserver数据库中已存在名为的对象怎么解决
Apr 05, 2024 pm 09:42 PM
sqlserver数据库中已存在名为的对象怎么解决
Apr 05, 2024 pm 09:42 PM
对于 SQL Server 数据库中已存在同名对象,需要采取以下步骤:确认对象类型(表、视图、存储过程)。如果对象为空,可使用 IF NOT EXISTS 跳过创建。如果对象有数据,使用不同名称或修改结构。使用 DROP 删除现有对象(谨慎操作,建议备份)。检查架构更改,确保没有引用删除或重命名的对象。
 sqlserver怎么导入mdf文件
Apr 08, 2024 am 11:41 AM
sqlserver怎么导入mdf文件
Apr 08, 2024 am 11:41 AM
导入步骤如下:将 MDF 文件复制到 SQL Server 的数据目录(通常为 C:\Program Files\Microsoft SQL Server\MSSQL\DATA)。在 SQL Server Management Studio(SSMS)中,打开数据库并选择“附加”。单击“添加”按钮,选择 MDF 文件。确认数据库名称,点击确定按钮即可。
 sqlserver服务无法启动怎么办
Apr 05, 2024 pm 10:00 PM
sqlserver服务无法启动怎么办
Apr 05, 2024 pm 10:00 PM
当 SQL Server 服务无法启动时,可采取以下步骤解决:检查错误日志以确定根本原因。确保服务帐户具有启动服务的权限。检查依赖项服务是否正在运行。禁用防病毒软件。修复 SQL Server 安装。如果修复不起作用,重新安装 SQL Server。
 怎么查看sqlserver端口号
Apr 05, 2024 pm 09:57 PM
怎么查看sqlserver端口号
Apr 05, 2024 pm 09:57 PM
要查看 SQL Server 端口号:打开 SSMS,连接到服务器。在对象资源管理器中找到服务器名称,右键单击它,然后选择“属性”。在“连接”选项卡中,查看“TCP 端口”字段。
 sqlserver数据库在哪里
Apr 05, 2024 pm 08:21 PM
sqlserver数据库在哪里
Apr 05, 2024 pm 08:21 PM
SQL Server 数据库文件通常存储在以下默认位置:Windows: C:\Program Files\Microsoft SQL Server\MSSQL\DATALinux: /var/opt/mssql/data可通过修改数据库文件路径设置来自定义数据库文件位置。
 sqlserver误删数据库怎么恢复
Apr 05, 2024 pm 10:39 PM
sqlserver误删数据库怎么恢复
Apr 05, 2024 pm 10:39 PM
若误删 SQL Server 数据库,可采取以下步骤恢复:停止数据库活动;备份日志文件;检查数据库日志;恢复选项:从备份恢复;从事务日志恢复;使用 DBCC CHECKDB;使用第三方工具。请定期备份数据库并启用事务日志以防止数据丢失。
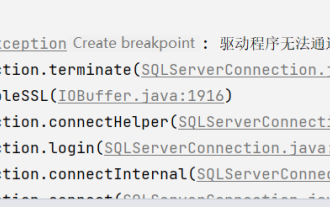 Java连接SqlServer错误如何解决
May 01, 2023 am 09:22 AM
Java连接SqlServer错误如何解决
May 01, 2023 am 09:22 AM
问题发现这次使用的是SqlServer数据库,之前并没有使用过,但是问题不大,我按照需求文档的步骤连接好SqlServer之后,启动SpringBoot项目,发现了一个报错,如下:刚开始我以为是SqlServer连接问题呢,于是便去查看数据库,发现数据库一切正常,我首先第一时间问了我的同事,他们是否有这样的问题,发现他们并没有,于是我便开始了我最拿手的环节,面向百度编程。开始解决具体报错信息是这样,于是我便开始了百度报错:ERRORc.a.d.p.DruidDataSource$CreateCo
 sqlserver安装失败怎么样删除干净
Apr 05, 2024 pm 11:27 PM
sqlserver安装失败怎么样删除干净
Apr 05, 2024 pm 11:27 PM
如果 SQL Server 安装失败,可通过以下步骤清理:卸载 SQL Server删除注册表项删除文件和文件夹重启计算机
