

hbase优化相关参数说明

1、hbase.regionserver.handler.count RegionServers处理远程请求的线程数,如果注重TPS,可以调大,默认10 note1:设得越大,意味着内存开销变大,hbase.client.write.buffer * hbase.regionserver.handler.count,hbase.client.write.buffer默认大小为2M n
1、hbase.regionserver.handler.count
RegionServers处理远程请求的线程数,如果注重TPS,可以调大,默认10 note1:值设得越大,意味着内存开销变大,hbase.client.write.buffer * hbase.regionserver.handler.count,hbase.client.write.buffer默认大小为2M note2: 对于提高write的速度,如果瓶颈在做flush、compact、split的速度,磁盘io跟不上,提高线程数,意义不大。2、hfile.block.cache.size
默认0.25,hfile/StoreFile的最大读缓存空间,所占堆空间比例。 note1:参数设定根据应用场景,如果读比写多,建议调大,读写平衡,建议设成0.3,如果读少于写,建议调小 note2:block.cache.size memstore limits 这些内存加起来不要超过60%。因为剩余的内存还要用来做其他事情。否则容易OOM。3、hbase.regionserver.global.memstore.upperLimit
默认0.4,memstores所占最大堆空间比例,如果达到上限,阻塞更新,强制flush数据4、hbase.regionserver.global.memstore.lowerLimit
默认0.35,menstores达到上限,做flush,知道memstores降到该值,停止flush。5、hbase.hstore.blockingStoreFiles
默认7,如果一个hstore里面storefile超过这个数字(每次memstore做flush时会生成一个hstore),会阻塞相应hregion的更新,知道一个compact压缩过程结束,或者阻塞时间超过hbase.hstore.blockingWaitTime(默认90s) note1:hbase.hstore.compactionThreshold,默认3,如果一个hstore里面的storefile数量超过这个数字,一个压缩任务会启动,将所有的storefile合并成一个。如果数量较多,那么会推迟合并过程,但是再执行时,将会消耗更多时间。 note2:对于持续写的系统,这个参数的设置,是为了compact与flush的速度平衡,如果compact的速度远小于flush的速度,有可能造成 文件io过多,造成too many openfile异常,以及给namenode带来更大的压力。6、hbase.hregion.memstore.flush.size、hbase.hregion.memstore.block.multiplier
默认134217728、2 第一个参数:如果一个memstore大小超过flushsize,则启动flush。后台会有一个线程在周期hbase.server.thread.wakefrequency内,定时检查 第二个参数:如果一个memstore大小超过 该值*flushsize,则阻塞更新。该参数可以平衡,写入速度、flush速度、compact速度、split速度7、hbase.regionserver.checksum.verify
默认false,决定,hbase使用自己的数据校验,而不是hdfs的校验。8、hbase.hregion.max.filesize
默认10G,一个region下,任一列簇的hfiles的大小,超过这个值,该region将split成2个region。 note:如果你的数据量增长的比较快,那么还是建议把这个大小调高,可以调成100G,因为越少的region你的集群越流畅,100G的阈值基本可以避免你的region增长过快,甚至你的region数目会长期不变。当然大region在compaction时也会更加缓慢。几十G的region启动和compaction都非常的慢,如果storefile较多,一个compaction可能会持续几天。9、谈谈region数量设置、以及region split过程
个人观点,如果可以尽早对region进行规划,可以提前预判规划好region的数量,这样可以节省split带来的消耗。 note1:人工进行split 设置hbase.hregion.max.filesize的值为LONG.MAX_VALUE,但是建议设成一个较大的值。预先设计region数量为10,或者更少,然后看数据发展情况。 如果数据较少,可以讲major compact的周期调大。如果数据增长比较快,那么可以调用org.apache.hadoop.hbase.util.RegionSplitter接口,主动进行split。
热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 C++ 函数参数类型安全检查
Apr 19, 2024 pm 12:00 PM
C++ 函数参数类型安全检查
Apr 19, 2024 pm 12:00 PM
C++参数类型安全检查通过编译时检查、运行时检查和静态断言确保函数只接受预期类型的值,防止意外行为和程序崩溃:编译时类型检查:编译器检查类型相容性。运行时类型检查:使用dynamic_cast检查类型相容性,不匹配则抛出异常。静态断言:在编译时对类型条件进行断言。
 C++ 程序优化:时间复杂度降低技巧
Jun 01, 2024 am 11:19 AM
C++ 程序优化:时间复杂度降低技巧
Jun 01, 2024 am 11:19 AM
时间复杂度衡量算法执行时间与输入规模的关系。降低C++程序时间复杂度的技巧包括:选择合适的容器(如vector、list)以优化数据存储和管理。利用高效算法(如快速排序)以减少计算时间。消除多重运算以减少重复计算。利用条件分支以避免不必要的计算。通过使用更快的算法(如二分搜索)来优化线性搜索。
 开源模型首胜GPT-4!竞技场最新战报引热议,Karpathy:这是我唯二信任的榜单
Apr 10, 2024 pm 03:16 PM
开源模型首胜GPT-4!竞技场最新战报引热议,Karpathy:这是我唯二信任的榜单
Apr 10, 2024 pm 03:16 PM
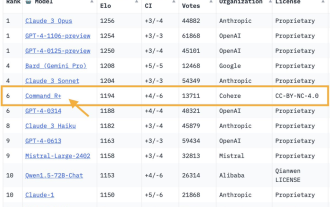
能打得过GPT-4的开源模型出现了!大模型竞技场最新战报:1040亿参数开源模型CommandR+攀升至第6位,与GPT-4-0314打成平手,超过了GPT-4-0613。图片这也是第一个在大模型竞技场上击败GPT-4的开放权重模型。大模型竞技场,可是大神Karpathy口中唯二信任的测试基准之一。图片CommandR+来自AI独角兽Cohere。这家大模型创业公司的联合创始人兼CEO,正是Transformer最年轻作者AidanGomez(简称割麦子)。图片这份战报一出,又掀起了一波大模型社
 vivox200ultra参数及价格详情
Jun 28, 2024 pm 01:23 PM
vivox200ultra参数及价格详情
Jun 28, 2024 pm 01:23 PM
vivox200ultra最新官方消息曝光了vivox200ultra参数及价格详情,据悉vivox200ultra将搭载10倍潜望超长焦,价格大概在6999元起,可见其在拍照性能上占据了绝对的优势地位,下面是vivox200ultra参数及价格详情,快来看看吧。一、vivox200ultra参数配置详情1、vivox200ultra渲染图由vivo X200 Ultra渲染图来看,该机正面采用了无边框的全面屏设计,整个手机正面的视觉效果可以说非常的无敌。2、vivox200ultra有黑鹰框架
 C++ 函数中引用参数和指针参数的高级用法
Apr 21, 2024 am 09:39 AM
C++ 函数中引用参数和指针参数的高级用法
Apr 21, 2024 am 09:39 AM
C++函数中的引用参数(本质为变量别名,修改引用修改原始变量)和指针参数(存储原始变量的内存地址,通过解引用指针修改变量)在传递和修改变量时有着不同的用法。引用参数常用于修改原始变量(尤其是大型结构体),传递给构造函数或赋值运算符时避免复制开销。指针参数则用于灵活指向内存位置,实现动态数据结构或传递空指针表示可选参数。
 优化WIN7系统开机启动项的操作方法
Mar 26, 2024 pm 06:20 PM
优化WIN7系统开机启动项的操作方法
Mar 26, 2024 pm 06:20 PM
1、在桌面上按组合键(win键+R)打开运行窗口,接着输入【regedit】,回车确认。2、打开注册表编辑器后,我们依次点击展开【HKEY_CURRENT_USERSoftwareMicrosoftWindowsCurrentVersionExplorer】,然后看目录里有没有Serialize项,如果没有我们可以单击右键Explorer,新建项,并将其命名为Serialize。3、接着点击Serialize,然后在右边窗格空白处单击鼠标右键,新建一个DWORD(32)位值,并将其命名为Star
 解决 PHP 函数效率低下的方法有哪些?
May 02, 2024 pm 01:48 PM
解决 PHP 函数效率低下的方法有哪些?
May 02, 2024 pm 01:48 PM
PHP函数效率优化的五大方法:避免不必要的变量复制。使用引用以避免变量复制。避免重复函数调用。内联简单的函数。使用数组优化循环。
 优化 Discuz 在线人数显示的方法分享
Mar 10, 2024 pm 12:57 PM
优化 Discuz 在线人数显示的方法分享
Mar 10, 2024 pm 12:57 PM
优化Discuz在线人数显示的方法分享Discuz是一款常用的论坛程序,通过优化在线人数的显示,可以提升用户体验和网站的整体性能。本文将分享一些优化在线人数显示的方法,并提供具体的代码示例供您参考。一、利用缓存在Discuz的在线人数显示中,通常需要频繁地查询数据库来获取最新的在线人数数据,这会增加数据库的负担和影响网站的性能。为了解决这个问题,我
