

【OpenCV2.4】SVM处理线性不可分的例子

【原文:http://www.cnblogs.com/justany/archive/2012/11/26/2788509.html】 目的 实际事物模型中,并非所有东西都是线性可分的。 需要寻找一种方法对线性不可分数据进行划分。 原理 ,我们推导出对于线性可分数据,最佳划分超平面应满足: 现在我们想引入
【原文:http://www.cnblogs.com/justany/archive/2012/11/26/2788509.html】
目的
- 实际事物模型中,并非所有东西都是线性可分的。
- 需要寻找一种方法对线性不可分数据进行划分。
原理
,我们推导出对于线性可分数据,最佳划分超平面应满足:

现在我们想引入一些东西,来表示那些被错分的数据点(比如噪点),对划分的影响。
如何来表示这些影响呢?
被错分的点,离自己应当存在的区域越远,就代表了,这个点“错”得越严重。
所以我们引入 ,为对应样本离同类区域的距离。
,为对应样本离同类区域的距离。

接下来的问题是,如何将这种错的程度,转换为和原模型相同的度量呢?
我们再引入一个常量C,表示和原模型度量的转换关系,用C对进行加权和,来表征错分点对原模型的影响,这样我们得到新的最优化问题模型:

关于参数C的选择, 明显的取决于训练样本的分布情况。 尽管并不存在一个普遍的答案,但是记住下面几点规则还是有用的:
- C比较大时分类错误率较小,但是间隔也较小。 在这种情形下, 错分类对模型函数产生较大的影响,既然优化的目的是为了最小化这个模型函数,那么错分类的情形必然会受到抑制。
- C比较小时间隔较大,但是分类错误率也较大。 在这种情形下,模型函数中错分类之和这一项对优化过程的影响变小,优化过程将更加关注于寻找到一个能产生较大间隔的超平面。
说白了,C的大小表征了,错分数据对原模型的影响程度。于是C越大,优化时越关注错分问题。反之越关注能否产生一个较大间隔的超平面。
开始使用

#include <iostream><span>
#include </span><opencv2><span>
#include </span><opencv2><span>
#include </span><opencv2>
<span>#define</span> NTRAINING_SAMPLES 100 <span>//</span><span> 每类训练样本的数量</span>
<span>#define</span> FRAC_LINEAR_SEP 0.9f <span>//</span><span> 线性可分部分的样本组成比例</span>
<span>using</span> <span>namespace</span><span> cv;
</span><span>using</span> <span>namespace</span><span> std;
</span><span>int</span><span> main(){
</span><span>//</span><span> 用于显示的数据</span>
<span>const</span> <span>int</span> WIDTH = <span>512</span>, HEIGHT = <span>512</span><span>;
Mat I </span>=<span> Mat::zeros(HEIGHT, WIDTH, CV_8UC3);
</span><span>/*</span><span> 1. 随即产生训练数据 </span><span>*/</span><span>
Mat trainData(</span><span>2</span>*NTRAINING_SAMPLES, <span>2</span><span>, CV_32FC1);
Mat labels (</span><span>2</span>*NTRAINING_SAMPLES, <span>1</span><span>, CV_32FC1);
RNG rng(</span><span>100</span>); <span>//</span><span> 生成随即数
</span><span>//</span><span> 设置线性可分的训练数据</span>
<span>int</span> nLinearSamples = (<span>int</span>) (FRAC_LINEAR_SEP *<span> NTRAINING_SAMPLES);
</span><span>//</span><span> 生成分类1的随机点</span>
Mat trainClass = trainData.rowRange(<span>0</span><span>, nLinearSamples);
</span><span>//</span><span> 点的x坐标在[0, 0.4)之间</span>
Mat c = trainClass.colRange(<span>0</span>, <span>1</span><span>);
rng.fill(c, RNG::UNIFORM, Scalar(</span><span>1</span>), Scalar(<span>0.4</span> *<span> WIDTH));
</span><span>//</span><span> 点的y坐标在[0, 1)之间</span>
c = trainClass.colRange(<span>1</span>,<span>2</span><span>);
rng.fill(c, RNG::UNIFORM, Scalar(</span><span>1</span><span>), Scalar(HEIGHT));
</span><span>//</span><span> 生成分类2的随机点</span>
trainClass = trainData.rowRange(<span>2</span>*NTRAINING_SAMPLES-nLinearSamples, <span>2</span>*<span>NTRAINING_SAMPLES);
</span><span>//</span><span> 点的x坐标在[0.6, 1]之间</span>
c = trainClass.colRange(<span>0</span> , <span>1</span><span>);
rng.fill(c, RNG::UNIFORM, Scalar(</span><span>0.6</span>*<span>WIDTH), Scalar(WIDTH));
</span><span>//</span><span> 点的y坐标在[0, 1)之间</span>
c = trainClass.colRange(<span>1</span>,<span>2</span><span>);
rng.fill(c, RNG::UNIFORM, Scalar(</span><span>1</span><span>), Scalar(HEIGHT));
</span><span>/*</span><span> 设置非线性可分的训练数据 </span><span>*/</span>
<span>//</span><span> 生成分类1和分类2的随机点</span>
trainClass = trainData.rowRange( nLinearSamples, <span>2</span>*NTRAINING_SAMPLES-<span>nLinearSamples);
</span><span>//</span><span> 点的x坐标在[0.4, 0.6)之间</span>
c = trainClass.colRange(<span>0</span>,<span>1</span><span>);
rng.fill(c, RNG::UNIFORM, Scalar(</span><span>0.4</span>*WIDTH), Scalar(<span>0.6</span>*<span>WIDTH));
</span><span>//</span><span> 点的y坐标在[0, 1)之间</span>
c = trainClass.colRange(<span>1</span>,<span>2</span><span>);
rng.fill(c, RNG::UNIFORM, Scalar(</span><span>1</span><span>), Scalar(HEIGHT));
</span><span>/*</span><span>*/</span><span>
labels.rowRange( </span><span>0</span>, NTRAINING_SAMPLES).setTo(<span>1</span>); <span>//</span><span> Class 1</span>
labels.rowRange(NTRAINING_SAMPLES, <span>2</span>*NTRAINING_SAMPLES).setTo(<span>2</span>); <span>//</span><span> Class 2</span>
<span>/*</span><span> 设置支持向量机参数 </span><span>*/</span><span>
CvSVMParams </span><span>params</span><span>;
</span><span>params</span>.svm_type =<span> SVM::C_SVC;
</span><span>params</span>.C = <span>0.1</span><span>;
</span><span>params</span>.kernel_type =<span> SVM::LINEAR;
</span><span>params</span>.term_crit = TermCriteria(CV_TERMCRIT_ITER, (<span>int</span>)1e7, 1e-<span>6</span><span>);
</span><span>/*</span><span> 3. 训练支持向量机 </span><span>*/</span><span>
cout </span>"<span>Starting training process</span><span>"</span> endl;
CvSVM svm;
svm.train(trainData, labels, Mat(), Mat(), <span>params</span><span>);
cout </span>"<span>Finished training process</span><span>"</span> endl;
<span>/*</span><span> 4. 显示划分区域 </span><span>*/</span><span>
Vec3b green(</span><span>0</span>,<span>100</span>,<span>0</span>), blue (<span>100</span>,<span>0</span>,<span>0</span><span>);
</span><span>for</span> (<span>int</span> i = <span>0</span>; i i)
<span>for</span> (<span>int</span> j = <span>0</span>; j j){
Mat sampleMat = (Mat_float>(<span>1</span>,<span>2</span>) i, j);
<span>float</span> response =<span> svm.predict(sampleMat);
</span><span>if</span> (response == <span>1</span>) I.at<vec3b>(j, i) =<span> green;
</span><span>else</span> <span>if</span> (response == <span>2</span>) I.at<vec3b>(j, i) =<span> blue;
}
</span><span>/*</span><span> 5. 显示训练数据 </span><span>*/</span>
<span>int</span> thick = -<span>1</span><span>;
</span><span>int</span> lineType = <span>8</span><span>;
</span><span>float</span><span> px, py;
</span><span>//</span><span> 分类1</span>
<span>for</span> (<span>int</span> i = <span>0</span>; i i){
px = trainData.atfloat>(i,<span>0</span><span>);
py </span>= trainData.atfloat>(i,<span>1</span><span>);
circle(I, Point( (</span><span>int</span>) px, (<span>int</span>) py ), <span>3</span>, Scalar(<span>0</span>, <span>255</span>, <span>0</span><span>), thick, lineType);
}
</span><span>//</span><span> 分类2</span>
<span>for</span> (<span>int</span> i = NTRAINING_SAMPLES; i 2*NTRAINING_SAMPLES; ++<span>i){
px </span>= trainData.atfloat>(i,<span>0</span><span>);
py </span>= trainData.atfloat>(i,<span>1</span><span>);
circle(I, Point( (</span><span>int</span>) px, (<span>int</span>) py ), <span>3</span>, Scalar(<span>255</span>, <span>0</span>, <span>0</span><span>), thick, lineType);
}
</span><span>/*</span><span> 6. 显示支持向量 */</span>
thick = <span>2</span><span>;
lineType </span>= <span>8</span><span>;
</span><span>int</span> x =<span> svm.get_support_vector_count();
</span><span>for</span> (<span>int</span> i = <span>0</span>; i i)
{
<span>const</span> <span>float</span>* v =<span> svm.get_support_vector(i);
circle( I, Point( (</span><span>int</span>) v[<span>0</span>], (<span>int</span>) v[<span>1</span>]), <span>6</span>, Scalar(<span>128</span>, <span>128</span>, <span>128</span><span>), thick, lineType);
}
imwrite(</span><span>"</span><span>result.png</span><span>"</span>, I); <span>//</span><span> 保存图片</span>
imshow(<span>"</span><span>SVM线性不可分数据划分</span><span>"</span>, I); <span>//</span><span> 显示给用户</span>
waitKey(<span>0</span><span>);
}</span></vec3b></vec3b></opencv2></opencv2></opencv2></iostream>
设置SVM参数
这里的参数设置可以参考一下的API。
<span>CvSVMParams</span> <span>params</span><span>;</span> <span>params</span><span>.</span><span>svm_type</span> <span>=</span> <span>SVM</span><span>::</span><span>C_SVC</span><span>;</span> <span>params</span><span>.</span><span>C</span> <span>=</span> <span>0.1</span><span>;</span> <span>params</span><span>.</span><span>kernel_type</span> <span>=</span> <span>SVM</span><span>::</span><span>LINEAR</span><span>;</span> <span>params</span><span>.</span><span>term_crit</span> <span>=</span> <span>TermCriteria</span><span>(</span><span>CV_TERMCRIT_ITER</span><span>,</span> <span>(</span><span>int</span><span>)</span><span>1e7</span><span>,</span> <span>1e-6</span><span>);</span>登录后复制
可以看到,这次使用的是C类支持向量分类机。其参数C的值为0.1。
结果
- 程序创建了一张图像,在其中显示了训练样本,其中一个类显示为浅绿色圆圈,另一个类显示为浅蓝色圆圈。
- 训练得到SVM,并将图像的每一个像素分类。 分类的结果将图像分为蓝绿两部分,中间线就是最优分割超平面。由于样本非线性可分, 自然就有一些被错分类的样本。 一些绿色点被划分到蓝色区域, 一些蓝色点被划分到绿色区域。
- 最后支持向量通过灰色边框加重显示。

被山寨的原文
Support Vector Machines for Non-Linearly Separable Data . OpenCV.org

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 WIN10服务主机太占cpu的处理操作过程
Mar 27, 2024 pm 02:41 PM
WIN10服务主机太占cpu的处理操作过程
Mar 27, 2024 pm 02:41 PM
1、首先我们右击任务栏空白处,选择【任务管理器】选项,或者右击开始徽标,然后再选择【任务管理器】选项。2、在打开的任务管理器界面,我们点击最右端的【服务】选项卡。3、在打开的【服务】选项卡,点击下方的【打开服务】选项。4、在打开的【服务】窗口,右击【InternetConnectionSharing(ICS)】服务,然后选择【属性】选项。5、在打开的属性窗口,将【打开方式】修改为【禁用】,点击【应用】后点击【确定】。6、点击开始徽标,然后点击关机按钮,选择【重启】,完成电脑重启就行了。
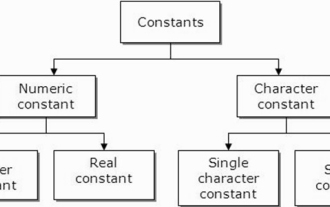 C语言中的常量是什么,可以举一个例子吗?
Aug 28, 2023 pm 10:45 PM
C语言中的常量是什么,可以举一个例子吗?
Aug 28, 2023 pm 10:45 PM
常量也称为变量,一旦定义,其值在程序执行期间就不会改变。因此,我们可以将变量声明为引用固定值的常量。它也被称为文字。必须使用Const关键字来定义常量。语法C编程语言中使用的常量语法如下-consttypeVariableName;(or)consttype*VariableName;不同类型的常量在C编程语言中使用的不同类型的常量如下所示:整数常量-例如:1,0,34,4567浮点数常量-例如:0.0,156.89,23.456八进制和十六进制常量-例如:十六进制:0x2a,0xaa..八进制
 Excel数据导入Mysql常见问题汇总:如何处理导入数据时遇到的错误日志问题?
Sep 10, 2023 pm 02:21 PM
Excel数据导入Mysql常见问题汇总:如何处理导入数据时遇到的错误日志问题?
Sep 10, 2023 pm 02:21 PM
Excel数据导入Mysql常见问题汇总:如何处理导入数据时遇到的错误日志问题?导入Excel数据到MySQL数据库是一项常见的任务。然而,在这个过程中,我们经常会遇到各种错误和问题。其中之一就是错误日志问题。当我们尝试导入数据时,系统可能会生成一个错误日志,列出了发生错误的具体信息。那么,当我们遇到这种情况时,应该如何处理错误日志呢?首先,我们需要知道如何
 CSV文件操作速成指南
Dec 26, 2023 pm 02:23 PM
CSV文件操作速成指南
Dec 26, 2023 pm 02:23 PM
快速学会打开和处理CSV格式文件的方法指南随着数据分析和处理的不断发展,CSV格式成为了广泛使用的文件格式之一。CSV文件是一种简单且易于阅读的文本文件,其以逗号分隔不同的数据字段。无论是在学术研究、商业分析还是数据处理方面,都经常会遇到需要打开和处理CSV文件的情况。下面的指南将向您介绍如何快速学会打开和处理CSV格式文件。步骤一:了解CSV文件格式首先,
 学习PHP中如何处理特殊字符转换单引号
Mar 27, 2024 pm 12:39 PM
学习PHP中如何处理特殊字符转换单引号
Mar 27, 2024 pm 12:39 PM
在PHP开发过程中,处理特殊字符是一个常见的问题,尤其是在字符串处理中经常会遇到特殊字符转义的情况。其中,将特殊字符转换单引号是一个比较常见的需求,因为在PHP中,单引号是一种常用的字符串包裹方式。在本文中,我们将介绍如何在PHP中处理特殊字符转换单引号,并提供具体的代码示例。在PHP中,特殊字符包括但不限于单引号(')、双引号(")、反斜杠()等。在字符串
 如何处理Java中的java.lang.UnsatisfiedLinkError错误?
Aug 24, 2023 am 11:01 AM
如何处理Java中的java.lang.UnsatisfiedLinkError错误?
Aug 24, 2023 am 11:01 AM
Java.lang.UnsatisfiedLinkError异常在运行时发生,当尝试访问或加载本地方法或库时,由于其架构、操作系统或库路径配置与引用的不匹配而失败。它通常表示存在与架构、操作系统配置或路径配置不兼容的问题,导致无法成功-通常引用的本地库与系统上安装的库不匹配,并且在运行时不可用要克服这个错误,关键是原生库与您的系统兼容并且可以通过其库路径设置进行访问。应该验证库文件是否存在于其指定位置,并满足系统要求。java.lang.UnsatisfiedLinkErrorjava.lang
 C#开发中如何处理XML和JSON数据格式
Oct 09, 2023 pm 06:15 PM
C#开发中如何处理XML和JSON数据格式
Oct 09, 2023 pm 06:15 PM
C#开发中如何处理XML和JSON数据格式,需要具体代码示例在现代软件开发中,XML和JSON是广泛应用的两种数据格式。XML(可扩展标记语言)是一种用于存储和传输数据的标记语言,而JSON(JavaScript对象表示)是一种轻量级的数据交换格式。在C#开发中,我们经常需要处理和操作XML和JSON数据,本文将重点介绍如何使用C#处理这两种数据格式,并附上
 如何在PHP项目中通过调用API接口来实现数据的爬取和处理?
Sep 05, 2023 am 08:41 AM
如何在PHP项目中通过调用API接口来实现数据的爬取和处理?
Sep 05, 2023 am 08:41 AM
如何在PHP项目中通过调用API接口来实现数据的爬取和处理?一、介绍在PHP项目中,我们经常需要爬取其他网站的数据,并对这些数据进行处理。而许多网站提供了API接口,我们可以通过调用这些接口来获取数据。本文将介绍如何使用PHP来调用API接口,实现数据的爬取和处理。二、获取API接口的URL和参数在开始之前,我们需要先获取目标API接口的URL以及所需的
