

MongoDB入门学习(四):MongoDB的索引

上一篇讲到了MongoDB的基本操作增删查改,对于查询来说,必须按照我们的查询要求去集合中,并将查找到的结果返回,在这个过程中其实是对整个集合中每个文档进行了扫描,如果满足我们的要求就添加到结果集中最后返回。对于小集合来说,这个过程没什么,但是集
上一篇讲到了MongoDB的基本操作增删查改,对于查询来说,必须按照我们的查询要求去集合中,并将查找到的结果返回,在这个过程中其实是对整个集合中每个文档进行了扫描,如果满足我们的要求就添加到结果集中最后返回。对于小集合来说,这个过程没什么,但是集合中数据很大的时候,进行表扫描是一个非常恐怖的事情,于是有了索引一说,索引是用来加速查询的,相当于书籍的目录,有了目录可以很精准的定位要查找内容的位置,从而减少无谓的查找。
1.索引的类型
创建索引可以是在单个字段上,也可以是在多个字段上,这个根据自己的实际情况来选择,创建索引时字段的顺序也是有讲究的。创建索引是通过ensureIndex()方法,需要给该方法传递一个文档形式的数据,其中指定索引的字段和顺序,1代表升序,-1代表降序。
1).默认索引
还记得"_id"吗,这个字段的数据是不能重复的,它就是MongoDB的默认索引,而且不能被删除。
2).单列索引
在单个字段上创建的索引就是单列索引,在查询的过程中可以对该加速对该键的查询,然而对其他键的查询是没有帮助的。单列索引的顺序是不会影响对该键的随即查询,创建单列索引:
> db.people.ensureIndex({"name" : 1})3).组合索引
还可以在多个键上创建组合索引,此时键的位置和索引的顺序都会影响查询的效率,看下面创建组合索引:
> db.people.ensureIndex({"name" : 1, "age" : 1})
> db.people.ensureIndex({"age" : 1, "name" : 1})第一种情况会对name排序组织,当name一样时在对age排序,所以对{"name" : 1}和{“name” : 1, "age" : 1}的查询更高效,而第二种情况则对age排序,当age一样再对name排序,所以对{"age" : 1}和{"age" : 1, "name" : 1}的查询更高效。当组合索引包含很多字段的时候,会对前几个键的查询有帮助。
4).内嵌文档索引
还可以对内嵌文档创建索引,和普通键创建索引一样差不多,也可以对内嵌文档创建组合索引:
> db.people.ensureIndex({"friends.name" : 1})
> db.people.ensureIndex({"friends.name" : 1, "friends.age" : 1})在来看看其他几种形式的索引:
唯一索引
> db.people.ensureIndex({"name" : 1}, {"unique" : true})
> db.people.ensureIndex({"name" : 1}, {"unique" : true, "dropDups" : true})
松散索引
> db.people.ensureIndex({"name" : 1}, {"sparse" : true})
多值索引
> db.people.find()
{"name" : ["mary", "rose"]}
> db.people.ensureIndex({"name" : 1})唯一索引unique可以保证该键对应的值在集合中是唯一的,如果创建唯一索引的时候,该字段原来就存在了重复的数据,那么就会创建失败,可以加上dropDups字段来消除重复数据,它会保留发现的第一个文档,其他有重复数据的文档都将被删除。
集合中有的文档不存在某些字段,或者某些字段的值为null,那么我们在该字段上创建索引的时候不希望让这些空值的文档参与,那么就定义为松散索引sparse,比如在name上创建索引时,发现有的人在数据库中只有学号,没有名字,那么我们不希望把它们也包含进来,此时就定义为松散索引。
一个键对应的值是一个数组,在该键上创建索引时是一个多值索引,会为数组中每个值生成一个索引元素,相当于分裂成了几个独立的索引项,但是它们还是对应同一个文档数据。
2.索引的管理
索引固然是为查询而生,而且可以为每个键都创建索引,但是索引是需要存储空间的,所以索引不是越多越好,而且创建索引后,每次的插入,更新和删除文档都会产生额外的开销,因为数据库中不但要执行这些操作,而且还要在集合索引中标记这些操作。所以要根据实际情况来创建索引,索引没用之后将其删除。
创建索引是ensureIndex()方法,创建完成后可以通过getIndexes()来查看集合中创建的索引情况:
> db.people.ensureIndex({"name" : 1, "age" : 1})
> db.people.getIndexes()
[
{
"v" : 1,
"key" : {
"_id" : 1
},
"ns" : "test.people",
"name" : "_id_"
},
{
"v" : 1,
"key" : {
"name" : 1,
"age" : 1
},
"ns" : "test.people",
"name" : "name_1_age_1"
}
]可以看到people集合创建了两个索引,一个是"_id",这个是默认索引,另外一个是name和age的组合索引,名字为keyname1_dir_keyname2_dir_...,keyname代表索引的键,dir代表方向,1代表升序,-1代表降序。当然我们也可以自定义索引的名称:
> db.people.ensureIndex({"name" : 1, "age" : 1}, {"name" : "myIndex"})
> db.people.getIndexes()
[
{
"v" : 1,
"key" : {
"_id" : 1
},
"ns" : "test.people",
"name" : "_id_"
},
{
"v" : 1,
"key" : {
"name" : 1,
"age" : 1
},
"ns" : "test.people",
"name" : "myIndex"
}
]删除索引是通过dropIndex():
方式一:
> db.people.dropIndex({"name" : 1, "age" : 1})
{ "nIndexesWas" : 2, "ok" : 1 }
方式二:
> db.runCommand({"dropIndexes" : "people", "index" : "myIndex"})
{ "nIndexesWas" : 2, "ok" : 1 }索引的元信息存储在每个数据库的system.indexes集合中,不能对其进行插入和删除文档的操作,只能通过ensureIndex和dropIndex进行。
> db.system.indexes.find()
{ "v" : 1, "key" : { "_id" : 1 }, "ns" : "test.people", "name" : "_id_" }
{ "v" : 1, "key" : { "name" : 1, "age" : 1 }, "ns" : "test.people", "name" : "myIndex" }清空集合中所有的文档是不会将索引删除的,原来创建的索引依然存在,但是直接删除集合的话,该集合的索引也是会被删除的。
3.索引的效率
如果我们定义了很多的索引,那么MongoDB会根据我们的查询选项重新排序,并智能的选择一个最优的来使用,比如我们创建了{"name" : 1, "age" : 1}和{"age" : 1, "class" : 1}两个索引,但是我们的查询项为find({"age" : 10, "name" : "mary"}),那么MongoDB会自动重新排序为find({"name" : "mary", "age" : 10}),并且利用索引{"name" : 1, "age" : 1}来查询。
MongoDB提供了explain工具来帮助我们获得查询方面的很多有用信息,只要对游标调用这个方法就可以得到查询的细节。下面给math集合中添加10W个文档,再来看看使用索引前后的效率对比:
> var arr = [];
> for(var i = 0; i < 100000; i++){
... var doc = {};
... var value = Math.floor(Math.random() * 1000);
... doc["number"] = value;
... arr.push(doc);
... }
100000
> db.math.insert(arr)
> db.math.count()
100000
> db.math.find().limit(10)
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61fe5"), "number" : 462 }
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61fe6"), "number" : 123 }
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61fe7"), "number" : 90 }
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61fe8"), "number" : 46 }
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61fe9"), "number" : 244 }
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61fea"), "number" : 972 }
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61feb"), "number" : 925 }
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61fec"), "number" : 110 }
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61fed"), "number" : 739 }
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61fee"), "number" : 945 }通过for循环给arr数组中添加10W条数据,然后再批量插入这些数据到math集合中,查看前10条数据,因为是随即生成的值,所以number字段的值会有重复值,我们就来查询462这个值:
创建索引前:
> db.math.find({"number" : 462}).explain()
{
"cursor" : "BasicCursor",
"isMultiKey" : false,
"n" : 94,
"nscannedObjects" : 100000,
"nscanned" : 100000,
"nscannedObjectsAllPlans" : 100000,
"nscannedAllPlans" : 100000,
"scanAndOrder" : false,
"indexOnly" : false,
"nYields" : 0,
"nChunkSkips" : 0,
"millis" : 35,
"indexBounds" : {
},
"server" : "server0.169:9352"
}
创建索引后:
> db.math.ensureIndex({"number" : 1})
> db.math.find({"number" : 462}).explain()
{
"cursor" : "BtreeCursor number_1",
"isMultiKey" : false,
"n" : 94,
"nscannedObjects" : 94,
"nscanned" : 94,
"nscannedObjectsAllPlans" : 94,
"nscannedAllPlans" : 94,
"scanAndOrder" : false,
"indexOnly" : false,
"nYields" : 0,
"nChunkSkips" : 0,
"millis" : 0,
"indexBounds" : {
"number" : [
[
462,
462
]
]
},
"server" : "server0.169:9352"
}这里来看一下有用的信息,"cursor"指用的哪个索引,"nscanned"代表查找了多少个文档,"n"指返回文档的数量,"millis"表示查询所花时间,单位是毫秒。可以看出创建索引前没有使用索引,在全部的文档中查询的,花费了35毫秒,而创建索引后,使用了number_1索引查询,索引存储在B树结构中,只在94个文档中查询,几乎不花时间。
如果有很多索引的话,MongoDB会自动选一个来查询,你也可以通过hint来强制使用某个索引,这里强制使用{"age" : 1, "name" : 1}这个索引:
> db.people.find({"age" : {"$gt" : 10}, "name" : "mary"}).hint({"age" : 1, "name" : 1})
热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 AI在用 | AI制作独居女孩生活Vlog,3天狂揽上万点赞量
Aug 07, 2024 pm 10:53 PM
AI在用 | AI制作独居女孩生活Vlog,3天狂揽上万点赞量
Aug 07, 2024 pm 10:53 PM
机器之能报道编辑:杨文以大模型、AIGC为代表的人工智能浪潮已经在悄然改变着我们生活及工作方式,但绝大部分人依然不知道该如何使用。因此,我们推出了「AI在用」专栏,通过直观、有趣且简洁的人工智能使用案例,来具体介绍AI使用方法,并激发大家思考。我们也欢迎读者投稿亲自实践的创新型用例。视频链接:https://mp.weixin.qq.com/s/2hX_i7li3RqdE4u016yGhQ最近,独居女孩的生活Vlog在小红书上走红。一个插画风格的动画,再配上几句治愈系文案,短短几天就能轻松狂揽上
 为什么学线代时不知道:矩阵与图竟然存在等价关系
Aug 19, 2024 pm 04:52 PM
为什么学线代时不知道:矩阵与图竟然存在等价关系
Aug 19, 2024 pm 04:52 PM
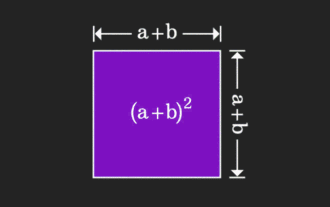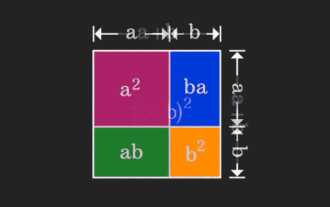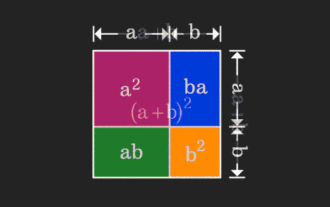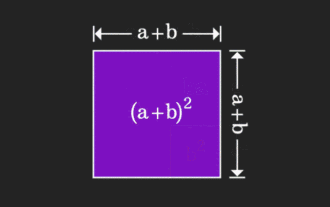
矩阵很难理解,但换个视角或许会不一样。在学习数学时,我们常因所学知识的难度和抽象而受挫;但有些时候,只需换个角度,我们就能为问题的解答找到一个简单又直观的解法。举个例子,小时候在学习和的平方(a+b)²公式时,我们可能并不理解为什么它等于a²+2ab+b²,只知道书上这么写,老师让这么记;直到某天我们看见了这张动图:登时恍然大悟,原来我们可以从几何角度来理解它!现在,这种恍然大悟之感又出现了:非负矩阵可以等价地转换成对应的有向图!如下图所示,左侧的3×3矩阵其实可
 如何在Debian上配置MongoDB自动扩容
Apr 02, 2025 am 07:36 AM
如何在Debian上配置MongoDB自动扩容
Apr 02, 2025 am 07:36 AM
本文介绍如何在Debian系统上配置MongoDB实现自动扩容,主要步骤包括MongoDB副本集的设置和磁盘空间监控。一、MongoDB安装首先,确保已在Debian系统上安装MongoDB。使用以下命令安装:sudoaptupdatesudoaptinstall-ymongodb-org二、配置MongoDB副本集MongoDB副本集确保高可用性和数据冗余,是实现自动扩容的基础。启动MongoDB服务:sudosystemctlstartmongodsudosys
 MongoDB在Debian上的高可用性如何保障
Apr 02, 2025 am 07:21 AM
MongoDB在Debian上的高可用性如何保障
Apr 02, 2025 am 07:21 AM
本文介绍如何在Debian系统上构建高可用性的MongoDB数据库。我们将探讨多种方法,确保数据安全和服务持续运行。关键策略:副本集(ReplicaSet):利用副本集实现数据冗余和自动故障转移。当主节点出现故障时,副本集会自动选举新的主节点,保证服务的持续可用性。数据备份与恢复:定期使用mongodump命令进行数据库备份,并制定有效的恢复策略,以应对数据丢失风险。监控与报警:部署监控工具(如Prometheus、Grafana)实时监控MongoDB的运行状态,并
 Navicat查看MongoDB数据库密码的方法
Apr 08, 2025 pm 09:39 PM
Navicat查看MongoDB数据库密码的方法
Apr 08, 2025 pm 09:39 PM
直接通过 Navicat 查看 MongoDB 密码是不可能的,因为它以哈希值形式存储。取回丢失密码的方法:1. 重置密码;2. 检查配置文件(可能包含哈希值);3. 检查代码(可能硬编码密码)。
 CentOS MongoDB备份策略是什么
Apr 14, 2025 pm 04:51 PM
CentOS MongoDB备份策略是什么
Apr 14, 2025 pm 04:51 PM
CentOS系统下MongoDB高效备份策略详解本文将详细介绍在CentOS系统上实施MongoDB备份的多种策略,以确保数据安全和业务连续性。我们将涵盖手动备份、定时备份、自动化脚本备份以及Docker容器环境下的备份方法,并提供备份文件管理的最佳实践。手动备份:利用mongodump命令进行手动全量备份,例如:mongodump-hlocalhost:27017-u用户名-p密码-d数据库名称-o/备份目录此命令会将指定数据库的数据及元数据导出到指定的备份目录。
 Pi币重大更新:Pi Bank要来了!
Mar 03, 2025 pm 06:18 PM
Pi币重大更新:Pi Bank要来了!
Mar 03, 2025 pm 06:18 PM
PiNetwork即将推出革命性移动银行平台PiBank!PiNetwork今日发布重大更新Elmahrosa(Face)PIMISRBank,简称PiBank,它将传统银行服务与PiNetwork加密货币功能完美融合,实现法币与加密货币的原子交换(支持美元、欧元、印尼盾等法币与PiCoin、USDT、USDC等加密货币的互换)。究竟PiBank有何魅力?让我们一探究竟!PiBank主要功能:一站式管理银行账户和加密货币资产。支持实时交易,并采用生物特
 MongoDB 与关系数据库:全面比较
Apr 08, 2025 pm 06:30 PM
MongoDB 与关系数据库:全面比较
Apr 08, 2025 pm 06:30 PM
MongoDB与关系型数据库:深度对比本文将深入探讨NoSQL数据库MongoDB与传统关系型数据库(如MySQL和SQLServer)的差异。关系型数据库采用行和列的表格结构组织数据,而MongoDB则使用灵活的面向文档模型,更适应现代应用的需求。主要区别数据结构:关系型数据库使用预定义模式的表格存储数据,表间关系通过主键和外键建立;MongoDB使用类似JSON的BSON文档存储在集合中,每个文档结构可独立变化,实现无模式设计。架构设计:关系型数据库需要预先定义固定的模式;MongoDB支持
