

BigData-09-Greenplum概述及架构

0.写在前面: 0.1. 此笔记是参考《Greenplum企业应用实战》、《PostgreSQL8.2.3 中文文档》和《Getting Started with Greenplum for Big Data Analytics》整理; 0.2. 《Greenplum企业应用实战》购买地址:【京东商城】 【 当当网】 0.3.参考网页(持续更新)
0.写在前面:
0.1. 此笔记是参考《Greenplum企业应用实战》、《PostgreSQL8.2.3 中文文档》和《Getting Started with Greenplum for Big Data Analytics》整理;
0.2. 《Greenplum企业应用实战》购买地址:【京东商城】 【 当当网】
0.3.参考网页(持续更新)
1) Shared Disk VS Shared Nothing分布式架构1. Greenplum概述及架构
1.1. 什么是Greenplum
1) 为全球大型企业用户提供新型企业级数据仓库(EDW)、企业级数据云(EDC)和商务智能(BI)提供解决方案和咨询服务,专注于OLAP系统数据引擎开发;
2) 海量并行处理(Massively Parallel Processing) DBMS:
Greenplum的架构采用了MPP(大规模并行处理),在 MPP 系统中,每个 SMP节点也可以运行自己的操作系统、数据库等。换言之,每个节点内的 CPU 不能访问另一个节点的内存。节点之间的信息交互是通过节点互联网络实现的,这个过程一般称为数据重分配(Data Redistribution) 。
SMP(SymmetricMulti-Processing),对称多处理结构的简称,是指在一个计算机上汇集了一组处理器(多CPU),各CPU之间共享内存子系统以及总线结构。在这种技术的支持下,一个服务器系统可以同时运行多个处理器,并共享内存和其他的主机资源。传统的ORACLE和DB2均是此种类型,ORACLE RAC 是半共享状态;
与传统的SMP架构明显不同,通常情况下,MPP系统因为要在不同处理单元之间传送信息,所以它的效率要比SMP要差一点,但是这也不是绝对的,因为 MPP系统不共享资源,因此对它而言,资源比SMP要多,当需要处理的事务达到一定规模时,MPP的效率要比SMP好。这就是看通信时间占用计算时间的比例而定,如果通信时间比较多,那MPP系统就不占优势了,相反,如果通信时间比较少,那MPP系统可以充分发挥资源的优势,达到高效率。
3) 基于PostgreSQL 8.2开源版本,具有相同的客户端功能,增加支持并行处理的技术,增加支持数据仓库和BI的特性;
4) 外部表(external tables)/并行加载(parallel loading):外部表是指数据库可以直接使用操作系统中的数据文件,在Greenplum 4.2版本中支持对外部表的读写操作;
5) 资源管理:基于PostgreSQL增加了并行度的处理;
6) 查询优化器增强(query optimizer enhancements):增加对分布式的支持,空间的回收和分析,不需要进行多方面的调优。
1.2. Greenplum 体系架构

图一
Greenplum是一种基于ProstgreSQL的分布式数据库,其采用Shared-Nothing架构、主机、操作系统、内存、存储都是自我控制的,不存在共享。
补充:SharedDisk与Shared Nothing介绍

图二

图三
|
比较事项 |
概述 |
优点 |
缺点 |
使用场景 |
|
Shared Disk |
如图二所示,所有节点共享一份数据 |
只要有一个节点就可以访问所有数据 |
内存融合限制水平扩展能力 |
Oracle RAC,24*7的高可用性核心业务 |
|
Shared Nothing |
如图三所示,数据和节点有一一对应关系 |
每个节点交互少,很容易扩展 |
如果需要访问所有数据,需要所有节点都可用 |
SQL Server、DB2、Hadoop以及Greenplum |
1.2.1.Master Host
1) 建立与客户端的会话连接和管理;
2) SQL的解析并形成分布式的执行计划;
3) 将生成好的执行计划分发到每个Segment上执行;
4) 收集Segment的执行结果;
5) 不存储业务数据,只存储数据字典;
6) 可以一主一备,分布在两台机器上,为了提高性能,最好单独占用一台机器。
1.2.2.Segment Host
1) 业务数据的存储和存取;
2) 执行由Master分发的SQL语句;
3) 对于Master来说,每个Segment都是对等的,负责对应数据的存储和计算;
4) 每一台机器上可以配置一到多个Segment,因此建议采用相同的机器配置。
1.2.3.Interconnect
1) 是GP数据库的网络层,在每个Segment中起到一个IPC作用;
2) 推荐使用千兆以太网交换机做Interconnect;
3) 支持UDP和TCP两种协议,推荐使用UDP协议,因为其高可靠性、高性能以及可扩展性;而TCP协议最高只能使用1000个Segment实例。
1.3.网络配置示例

图四
图四显示一个常见的网络配置示例,其中X4200是主节点,X4500(Segment host1)是主从节点,当主节点宕机后会主节点服务切换到此节点上,X4500(Segment host2)是从节点。
每个网络接口对应不同的网口,隔离到独立网络,保证不会竞争其他端口的网络带宽,提高网络的可靠性;串口连接到交换机是管理员管理的窗口。
1.4.Greenplum 高可用性体系架构

图五
图五中显示高可用性体系的示例图,其中按照从左到右且从上到下依次是主从节点,主节点,客户端,私有局域网以及从节点集群,实现功能和图一基本一致。
1.5.Master/Standby 镜像保护

图六
图六说明:Standby 节点用于当 Master 节点损坏时提供 Master服务,Standby 实时与Master 节点的Catalog 和事务日志保持同步,确保系统的变更信息不会丢失,提升系统的健壮性。
1.6.数据冗余-Segment 镜像保护

图七
图七说明:
1) 当GP配置了镜像节点之后,主节点不可用时会自动切换到镜像节点,集群仍然保持可用状态。当主节点恢复并启动之后,主节点会自动恢复期间的变更;
2) 只要Master不能连接上Segment实例时,就会在系统表中将此实例标识为不可用,并用镜像节点来代替,一般需要和主节点位于不同的服务器上,当Primary Segment失败时,Mirror Segment将自动提供服务,Primary Segment恢复正常后,使用gprecoverseg –F 同步数据
1.7.Segment 主机硬件配置示例

图八
1.8.网络冗余

图九
图九说明:
1) 数据之间存在冗余,网络也存在冗余;
2) 公共网络连接到主节点,主节点通过一台或者多台交换机连接到子节点。

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 深度学习架构的对比分析
May 17, 2023 pm 04:34 PM
深度学习架构的对比分析
May 17, 2023 pm 04:34 PM
深度学习的概念源于人工神经网络的研究,含有多个隐藏层的多层感知器是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示,以表征数据的类别或特征。它能够发现数据的分布式特征表示。深度学习是机器学习的一种,而机器学习是实现人工智能的必经之路。那么,各种深度学习的系统架构之间有哪些差别呢?1.全连接网络(FCN)完全连接网络(FCN)由一系列完全连接的层组成,每个层中的每个神经元都连接到另一层中的每个神经元。其主要优点是“结构不可知”,即不需要对输入做出特殊的假设。虽然这种结构不可知使得完
 此「错」并非真的错:从四篇经典论文入手,理解Transformer架构图「错」在何处
Jun 14, 2023 pm 01:43 PM
此「错」并非真的错:从四篇经典论文入手,理解Transformer架构图「错」在何处
Jun 14, 2023 pm 01:43 PM
前段时间,一条指出谷歌大脑团队论文《AttentionIsAllYouNeed》中Transformer构架图与代码不一致的推文引发了大量的讨论。对于Sebastian的这一发现,有人认为属于无心之过,但同时也会令人感到奇怪。毕竟,考虑到Transformer论文的流行程度,这个不一致问题早就应该被提及1000次。SebastianRaschka在回答网友评论时说,「最最原始」的代码确实与架构图一致,但2017年提交的代码版本进行了修改,但同时没有更新架构图。这也是造成「不一致」讨论的根本原因。
 多路径多领域通吃!谷歌AI发布多领域学习通用模型MDL
May 28, 2023 pm 02:12 PM
多路径多领域通吃!谷歌AI发布多领域学习通用模型MDL
May 28, 2023 pm 02:12 PM
面向视觉任务(如图像分类)的深度学习模型,通常用来自单一视觉域(如自然图像或计算机生成的图像)的数据进行端到端的训练。一般情况下,一个为多个领域完成视觉任务的应用程序需要为每个单独的领域建立多个模型,分别独立训练,不同领域之间不共享数据,在推理时,每个模型将处理特定领域的输入数据。即使是面向不同领域,这些模型之间的早期层的有些特征都是相似的,所以,对这些模型进行联合训练的效率更高。这能减少延迟和功耗,降低存储每个模型参数的内存成本,这种方法被称为多领域学习(MDL)。此外,MDL模型也可以优于单
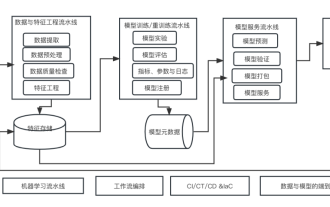 机器学习系统架构的十个要素
Apr 13, 2023 pm 11:37 PM
机器学习系统架构的十个要素
Apr 13, 2023 pm 11:37 PM
这是一个AI赋能的时代,而机器学习则是实现AI的一种重要技术手段。那么,是否存在一个通用的通用的机器学习系统架构呢?在老码农的认知范围内,Anything is nothing,对系统架构而言尤其如此。但是,如果适用于大多数机器学习驱动的系统或用例,构建一个可扩展的、可靠的机器学习系统架构还是可能的。从机器学习生命周期的角度来看,这个所谓的通用架构涵盖了关键的机器学习阶段,从开发机器学习模型,到部署训练系统和服务系统到生产环境。我们可以尝试从10个要素的维度来描述这样的一个机器学习系统架构。1.
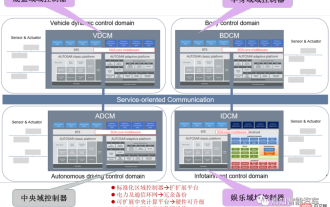 SOA中的软件架构设计及软硬件解耦方法论
Apr 08, 2023 pm 11:21 PM
SOA中的软件架构设计及软硬件解耦方法论
Apr 08, 2023 pm 11:21 PM
对于下一代集中式电子电器架构而言,采用central+zonal 中央计算单元与区域控制器布局已经成为各主机厂或者tier1玩家的必争选项,关于中央计算单元的架构方式,有三种方式:分离SOC、硬件隔离、软件虚拟化。集中式中央计算单元将整合自动驾驶,智能座舱和车辆控制三大域的核心业务功能,标准化的区域控制器主要有三个职责:电力分配、数据服务、区域网关。因此,中央计算单元将会集成一个高吞吐量的以太网交换机。随着整车集成化的程度越来越高,越来越多ECU的功能将会慢慢的被吸收到区域控制器当中。而平台化
 1.3ms耗时!清华最新开源移动端神经网络架构 RepViT
Mar 11, 2024 pm 12:07 PM
1.3ms耗时!清华最新开源移动端神经网络架构 RepViT
Mar 11, 2024 pm 12:07 PM
论文地址:https://arxiv.org/abs/2307.09283代码地址:https://github.com/THU-MIG/RepViTRepViT在移动端ViT架构中表现出色,展现出显着的优势。接下来,我们将探讨本研究的贡献所在。文中提到,轻量级ViTs通常比轻量级CNNs在视觉任务上表现得更好,这主要归功于它们的多头自注意力模块(MSHA)可以让模型学习全局表示。然而,轻量级ViTs和轻量级CNNs之间的架构差异尚未得到充分研究。在这项研究中,作者们通过整合轻量级ViTs的有效
 Spring Data JPA 的架构和工作原理是什么?
Apr 17, 2024 pm 02:48 PM
Spring Data JPA 的架构和工作原理是什么?
Apr 17, 2024 pm 02:48 PM
SpringDataJPA基于JPA架构,通过映射、ORM和事务管理与数据库交互。其存储库提供CRUD操作,派生查询简化了数据库访问。此外,它使用延迟加载,仅在必要时检索数据,从而提高了性能。
 2023年值得了解的几个前端格式化工具【总结】
Sep 30, 2022 pm 02:17 PM
2023年值得了解的几个前端格式化工具【总结】
Sep 30, 2022 pm 02:17 PM
eslint 使用eslint的生态链来规范开发者对js/ts基本语法的规范。防止团队的成员乱写. 这里主要使用到的eslint的包有以下几个: 使用的以下语句来按照依赖: 接下来需要对eslint的
