

伪分布式安装部署CDH4.2.1与Impala[原创实践]

参考资料: http://www.cloudera.com/content/cloudera-content/cloudera-docs/CDH4/latest/CDH4-Quick-Start/cdh4qs_topic_3_3.html http://www.cloudera.com/content/cloudera-content/cloudera-docs/Impala/latest/Installing-and-Using-Impala/Installing
参考资料:
http://www.cloudera.com/content/cloudera-content/cloudera-docs/CDH4/latest/CDH4-Quick-Start/cdh4qs_topic_3_3.html
http://www.cloudera.com/content/cloudera-content/cloudera-docs/Impala/latest/Installing-and-Using-Impala/Installing-and-Using-Impala.html
http://blog.cloudera.com/blog/2013/02/from-zero-to-impala-in-minutes/
什么是Impala?
Cloudera发布了实时查询开源项目Impala,根据多款产品实测表明,它比原来基于MapReduce的Hive SQL查询速度提升3~90倍。Impala是Google Dremel的模仿,但在SQL功能上青出于蓝胜于蓝。
1. 安装JDK
$ sudo yum install jdk-6u41-linux-amd64.rpm
2. 伪分布式模式安装CDH4
$ cd /etc/yum.repos.d/
$ sudo wget http://archive.cloudera.com/cdh4/redhat/6/x86_64/cdh/cloudera-cdh4.repo
$ sudo yum install hadoop-conf-pseudo
格式化NameNode.
$ sudo -u hdfs hdfs namenode -format
启动HDFS
$ for x in `cd /etc/init.d ; ls hadoop-hdfs-*` ; do sudo service $x start ; done
创建/tmp目录
$ sudo -u hdfs hadoop fs -rm -r /tmp
$ sudo -u hdfs hadoop fs -mkdir /tmp
$ sudo -u hdfs hadoop fs -chmod -R 1777 /tmp
创建YARN与日志目录
$ sudo -u hdfs hadoop fs -mkdir /tmp/hadoop-yarn/staging
$ sudo -u hdfs hadoop fs -chmod -R 1777 /tmp/hadoop-yarn/staging
$ sudo -u hdfs hadoop fs -mkdir /tmp/hadoop-yarn/staging/history/done_intermediate
$ sudo -u hdfs hadoop fs -chmod -R 1777 /tmp/hadoop-yarn/staging/history/done_intermediate
$ sudo -u hdfs hadoop fs -chown -R mapred:mapred /tmp/hadoop-yarn/staging
$ sudo -u hdfs hadoop fs -mkdir /var/log/hadoop-yarn
$ sudo -u hdfs hadoop fs -chown yarn:mapred /var/log/hadoop-yarn
检查HDFS文件树
$ sudo -u hdfs hadoop fs -ls -R /
drwxrwxrwt - hdfs supergroup 0 2012-05-31 15:31 /tmp drwxr-xr-x - hdfs supergroup 0 2012-05-31 15:31 /tmp/hadoop-yarn drwxrwxrwt - mapred mapred 0 2012-05-31 15:31 /tmp/hadoop-yarn/staging drwxr-xr-x - mapred mapred 0 2012-05-31 15:31 /tmp/hadoop-yarn/staging/history drwxrwxrwt - mapred mapred 0 2012-05-31 15:31 /tmp/hadoop-yarn/staging/history/done_intermediate drwxr-xr-x - hdfs supergroup 0 2012-05-31 15:31 /var drwxr-xr-x - hdfs supergroup 0 2012-05-31 15:31 /var/log drwxr-xr-x - yarn mapred 0 2012-05-31 15:31 /var/log/hadoop-yarn
启动YARN
$ sudo service hadoop-yarn-resourcemanager start
$ sudo service hadoop-yarn-nodemanager start
$ sudo service hadoop-mapreduce-historyserver start
创建用户目录(以用户dong.guo为例):
$ sudo -u hdfs hadoop fs -mkdir /user/dong.guo
$ sudo -u hdfs hadoop fs -chown dong.guo /user/dong.guo
测试上传文件
$ hadoop fs -mkdir input
$ hadoop fs -put /etc/hadoop/conf/*.xml input
$ hadoop fs -ls input
Found 4 items -rw-r--r-- 1 dong.guo supergroup 1461 2013-05-14 03:30 input/core-site.xml -rw-r--r-- 1 dong.guo supergroup 1854 2013-05-14 03:30 input/hdfs-site.xml -rw-r--r-- 1 dong.guo supergroup 1325 2013-05-14 03:30 input/mapred-site.xml -rw-r--r-- 1 dong.guo supergroup 2262 2013-05-14 03:30 input/yarn-site.xml
配置HADOOP_MAPRED_HOME环境变量
$ export HADOOP_MAPRED_HOME=/usr/lib/hadoop-mapreduce
运行一个测试Job
$ hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar grep input output23 'dfs[a-z.]+'
Job完成后,可以看到以下目录
$ hadoop fs -ls
Found 2 items drwxr-xr-x - dong.guo supergroup 0 2013-05-14 03:30 input drwxr-xr-x - dong.guo supergroup 0 2013-05-14 03:32 output23
$ hadoop fs -ls output23
Found 2 items -rw-r--r-- 1 dong.guo supergroup 0 2013-05-14 03:32 output23/_SUCCESS -rw-r--r-- 1 dong.guo supergroup 150 2013-05-14 03:32 output23/part-r-00000
$ hadoop fs -cat output23/part-r-00000 | head
1 dfs.safemode.min.datanodes 1 dfs.safemode.extension 1 dfs.replication 1 dfs.namenode.name.dir 1 dfs.namenode.checkpoint.dir 1 dfs.datanode.data.dir
3. 安装 Hive
$ sudo yum install hive hive-metastore hive-server
$ sudo yum install mysql-server
$ sudo service mysqld start
$ cd ~
$ wget 'http://cdn.mysql.com/Downloads/Connector-J/mysql-connector-java-5.1.25.tar.gz'
$ tar xzf mysql-connector-java-5.1.25.tar.gz
$ sudo cp mysql-connector-java-5.1.25/mysql-connector-java-5.1.25-bin.jar /usr/lib/hive/lib/
$ sudo /usr/bin/mysql_secure_installation
[...] Enter current password for root (enter for none): OK, successfully used password, moving on... [...] Set root password? [Y/n] y New password:hadoophive Re-enter new password:hadoophive Remove anonymous users? [Y/n] Y [...] Disallow root login remotely? [Y/n] N [...] Remove test database and access to it [Y/n] Y [...] Reload privilege tables now? [Y/n] Y All done!
$ mysql -u root -phadoophive
mysql> CREATE DATABASE metastore; mysql> USE metastore; mysql> SOURCE /usr/lib/hive/scripts/metastore/upgrade/mysql/hive-schema-0.10.0.mysql.sql; mysql> CREATE USER 'hive'@'%' IDENTIFIED BY 'hadoophive'; mysql> CREATE USER 'hive'@'localhost' IDENTIFIED BY 'hadoophive'; mysql> REVOKE ALL PRIVILEGES, GRANT OPTION FROM 'hive'@'%'; mysql> REVOKE ALL PRIVILEGES, GRANT OPTION FROM 'hive'@'localhost'; mysql> GRANT SELECT,INSERT,UPDATE,DELETE,LOCK TABLES,EXECUTE ON metastore.* TO 'hive'@'%'; mysql> GRANT SELECT,INSERT,UPDATE,DELETE,LOCK TABLES,EXECUTE ON metastore.* TO 'hive'@'localhost'; mysql> FLUSH PRIVILEGES; mysql> quit;
$ sudo mv /etc/hive/conf/hive-site.xml /etc/hive/conf/hive-site.xml.bak
$ sudo vim /etc/hive/conf/hive-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="http://heylinux.com/archives/configuration.xsl"?> javax.jdo.option.ConnectionURL jdbc:mysql://localhost/metastore the URL of the MySQL database javax.jdo.option.ConnectionDriverName com.mysql.jdbc.Driver javax.jdo.option.ConnectionUserName hive javax.jdo.option.ConnectionPassword hadoophive datanucleus.autoCreateSchema false datanucleus.fixedDatastore true hive.metastore.uris thrift://127.0.0.1:9083 IP address (or fully-qualified domain name) and port of the metastore host hive.aux.jars.path file:///usr/lib/hive/lib/zookeeper.jar,file:///usr/lib/hive/lib/hbase.jar,file:///usr/lib/hive/lib/hive-hbase-handler-0.10.0-cdh4.2.0.jar,file:///usr/lib/hive/lib/guava-11.0.2.jar
$ sudo service hive-metastore start
Starting (hive-metastore): [ OK ]
$ sudo service hive-server start
Starting (hive-server): [ OK ]
$ sudo -u hdfs hadoop fs -mkdir /user/hive
$ sudo -u hdfs hadoop fs -chown hive /user/hive
$ sudo -u hdfs hadoop fs -mkdir /tmp
$ sudo -u hdfs hadoop fs -chmod 777 /tmp
$ sudo -u hdfs hadoop fs -chmod o+t /tmp
$ sudo -u hdfs hadoop fs -mkdir /data
$ sudo -u hdfs hadoop fs -chown hdfs /data
$ sudo -u hdfs hadoop fs -chmod 777 /data
$ sudo -u hdfs hadoop fs -chmod o+t /data
$ sudo chown -R hive:hive /var/lib/hive
$ sudo vim /tmp/kv1.txt
1 www.baidu.com 2 www.google.com 3 www.sina.com.cn 4 www.163.com 5 heylinx.com
$ sudo -u hive hive
Logging initialized using configuration in file:/etc/hive/conf.dist/hive-log4j.properties Hive history file=/tmp/root/hive_job_log_root_201305140801_825709760.txt hive> CREATE TABLE IF NOT EXISTS pokes ( foo INT,bar STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t" LINES TERMINATED BY "\n"; hive> show tables; OK pokes Time taken: 0.415 seconds hive> LOAD DATA LOCAL INPATH '/tmp/kv1.txt' OVERWRITE INTO TABLE pokes; Copying data from file:/tmp/kv1.txt Copying file: file:/tmp/kv1.txt Loading data to table default.pokes rmr: DEPRECATED: Please use 'rm -r' instead. Deleted /user/hive/warehouse/pokes Table default.pokes stats: [num_partitions: 0, num_files: 1, num_rows: 0, total_size: 79, raw_data_size: 0] OK Time taken: 1.681 seconds
$ export HADOOP_MAPRED_HOME=/usr/lib/hadoop-mapreduce
4. 安装 Impala
$ cd /etc/yum.repos.d/
$ sudo wget http://archive.cloudera.com/impala/redhat/6/x86_64/impala/cloudera-impala.repo
$ sudo yum install impala impala-shell
$ sudo yum install impala-server impala-state-store
$ sudo vim /etc/hadoop/conf/hdfs-site.xml
... dfs.client.read.shortcircuit true dfs.domain.socket.path /var/run/hadoop-hdfs/dn._PORT dfs.client.file-block-storage-locations.timeout 3000 dfs.datanode.hdfs-blocks-metadata.enabled true
$ sudo cp -rpa /etc/hadoop/conf/core-site.xml /etc/impala/conf/
$ sudo cp -rpa /etc/hadoop/conf/hdfs-site.xml /etc/impala/conf/
$ sudo service hadoop-hdfs-datanode restart
$ sudo service impala-state-store restart
$ sudo service impala-server restart
$ sudo /usr/java/default/bin/jps
5. 安装 Hbase
$ sudo yum install hbase
$ sudo vim /etc/security/limits.conf
hdfs - nofile 32768 hbase - nofile 32768
$ sudo vim /etc/pam.d/common-session
session required pam_limits.so
$ sudo vim /etc/hadoop/conf/hdfs-site.xml
dfs.datanode.max.xcievers 4096
$ sudo cp /usr/lib/impala/lib/hive-hbase-handler-0.10.0-cdh4.2.0.jar /usr/lib/hive/lib/hive-hbase-handler-0.10.0-cdh4.2.0.jar
$ sudo /etc/init.d/hadoop-hdfs-namenode restart
$ sudo /etc/init.d/hadoop-hdfs-datanode restart
$ sudo yum install hbase-master
$ sudo service hbase-master start
$ sudo -u hive hive
Logging initialized using configuration in file:/etc/hive/conf.dist/hive-log4j.properties
Hive history file=/tmp/hive/hive_job_log_hive_201305140905_2005531704.txt
hive> CREATE TABLE hbase_table_1(key int, value string) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,cf1:val") TBLPROPERTIES ("hbase.table.name" = "xyz");
OK
Time taken: 3.587 seconds
hive> INSERT OVERWRITE TABLE hbase_table_1 SELECT * FROM pokes WHERE foo=5;
Total MapReduce jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1368502088579_0004, Tracking URL = http://ip-10-197-10-4:8088/proxy/application_1368502088579_0004/
Kill Command = /usr/lib/hadoop/bin/hadoop job -kill job_1368502088579_0004
Hadoop job information for Stage-0: number of mappers: 1; number of reducers: 0
2013-05-14 09:12:45,340 Stage-0 map = 0%, reduce = 0%
2013-05-14 09:12:53,165 Stage-0 map = 100%, reduce = 0%, Cumulative CPU 2.63 sec
MapReduce Total cumulative CPU time: 2 seconds 630 msec
Ended Job = job_1368502088579_0004
1 Rows loaded to hbase_table_1
MapReduce Jobs Launched:
Job 0: Map: 1 Cumulative CPU: 2.63 sec HDFS Read: 288 HDFS Write: 0 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 630 msec
OK
Time taken: 21.063 seconds
hive> select * from hbase_table_1;
OK
5 heylinx.com
Time taken: 0.685 seconds
hive> SELECT COUNT (*) FROM pokes;
Total MapReduce jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapred.reduce.tasks=<number>
Starting Job = job_1368502088579_0005, Tracking URL = http://ip-10-197-10-4:8088/proxy/application_1368502088579_0005/
Kill Command = /usr/lib/hadoop/bin/hadoop job -kill job_1368502088579_0005
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2013-05-14 10:32:04,711 Stage-1 map = 0%, reduce = 0%
2013-05-14 10:32:11,461 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.22 sec
2013-05-14 10:32:12,554 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.22 sec
2013-05-14 10:32:13,642 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.22 sec
2013-05-14 10:32:14,760 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.22 sec
2013-05-14 10:32:15,918 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.22 sec
2013-05-14 10:32:16,991 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.22 sec
2013-05-14 10:32:18,111 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.22 sec
2013-05-14 10:32:19,188 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 4.04 sec
MapReduce Total cumulative CPU time: 4 seconds 40 msec
Ended Job = job_1368502088579_0005
MapReduce Jobs Launched:
Job 0: Map: 1 Reduce: 1 Cumulative CPU: 4.04 sec HDFS Read: 288 HDFS Write: 2 SUCCESS
Total MapReduce CPU Time Spent: 4 seconds 40 msec
OK
5
Time taken: 28.195 seconds
</number></number></number>6. 测试Impala性能
View parameters on http://ec2-204-236-182-78.us-west-1.compute.amazonaws.com:25000
$ impala-shell
[ip-10-197-10-4.us-west-1.compute.internal:21000] > CREATE TABLE IF NOT EXISTS pokes ( foo INT,bar STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t" LINES TERMINATED BY "\n"; Query: create TABLE IF NOT EXISTS pokes ( foo INT,bar STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t" LINES TERMINATED BY "\n" [ip-10-197-10-4.us-west-1.compute.internal:21000] > show tables; Query: show tables Query finished, fetching results ... +-------+ | name | +-------+ | pokes | +-------+ Returned 1 row(s) in 0.00s [ip-10-197-10-4.us-west-1.compute.internal:21000] > SELECT * from pokes; Query: select * from pokes Query finished, fetching results ... +-----+-----------------+ | foo | bar | +-----+-----------------+ | 1 | www.baidu.com | | 2 | www.google.com | | 3 | www.sina.com.cn | | 4 | www.163.com | | 5 | heylinx.com | +-----+-----------------+ Returned 5 row(s) in 0.28s [ip-10-197-10-4.us-west-1.compute.internal:21000] > SELECT COUNT (*) from pokes; Query: select COUNT (*) from pokes Query finished, fetching results ... +----------+ | count(*) | +----------+ | 5 | +----------+ Returned 1 row(s) in 0.34s
通过两个COUNT的结果来看,Hive使用了 28.195 seconds 而 Impala仅使用了0.34s,由此可以看出Impala的性能确实要优于Hive。
原文地址:伪分布式安装部署CDH4.2.1与Impala[原创实践], 感谢原作者分享。

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 Win11系统无法安装中文语言包的解决方法
Mar 09, 2024 am 09:48 AM
Win11系统无法安装中文语言包的解决方法
Mar 09, 2024 am 09:48 AM
Win11系统无法安装中文语言包的解决方法随着Windows11系统的推出,许多用户开始升级他们的操作系统以体验新的功能和界面。然而,一些用户在升级后发现他们无法安装中文语言包,这给他们的使用体验带来了困扰。在本文中,我们将探讨Win11系统无法安装中文语言包的原因,并提供一些解决方法,帮助用户解决这一问题。原因分析首先,让我们来分析一下Win11系统无法
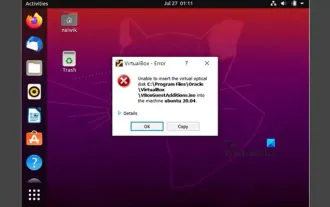 无法在VirtualBox中安装来宾添加
Mar 10, 2024 am 09:34 AM
无法在VirtualBox中安装来宾添加
Mar 10, 2024 am 09:34 AM
您可能无法在OracleVirtualBox中将来宾添加安装到虚拟机。当我们点击Devices>;InstallGuestAdditionsCDImage时,它只会抛出一个错误,如下所示:VirtualBox-错误:无法插入虚拟光盘C:将FilesOracleVirtualBoxVBoxGuestAdditions.iso编程到ubuntu机器中在这篇文章中,我们将了解当您无法在VirtualBox中安装来宾添加组件时该怎么办。无法在VirtualBox中安装来宾添加如果您无法在Virtua
 百度网盘下载成功但是安装不了怎么办?
Mar 13, 2024 pm 10:22 PM
百度网盘下载成功但是安装不了怎么办?
Mar 13, 2024 pm 10:22 PM
如果你已经成功下载了百度网盘的安装文件,但是无法正常安装,可能是软件文件的完整性发生了错误或者是残留文件和注册表项的问题,下面就让本站来为用户们来仔细的介绍一下百度网盘下载成功但是安装不了问题解析吧。 百度网盘下载成功但是安装不了问题解析 1、检查安装文件完整性:确保下载的安装文件完整且没有损坏。你可以重新下载一次,或者尝试使用其他可信的来源下载安装文件。 2、关闭杀毒软件和防火墙:某些杀毒软件或防火墙程序可能会阻止安装程序的正常运行。尝试将杀毒软件和防火墙禁用或退出,然后重新运行安装
 如何在Linux上安装安卓应用?
Mar 19, 2024 am 11:15 AM
如何在Linux上安装安卓应用?
Mar 19, 2024 am 11:15 AM
在Linux上安装安卓应用一直是许多用户所关心的问题,尤其是对于喜欢使用安卓应用的Linux用户来说,掌握如何在Linux系统上安装安卓应用是非常重要的。虽然在Linux系统上直接运行安卓应用并不像在Android平台上那么简单,但是通过使用模拟器或者第三方工具,我们依然可以在Linux上愉快地享受安卓应用的乐趣。下面将为大家介绍在Linux系统上安装安卓应
 在Ubuntu 24.04上安装和运行Ubuntu笔记应用程序的方法
Mar 22, 2024 pm 04:40 PM
在Ubuntu 24.04上安装和运行Ubuntu笔记应用程序的方法
Mar 22, 2024 pm 04:40 PM
在高中学习的时候,有些学生做的笔记非常清晰准确,比同一个班级的其他人都做得更多。对于一些人来说,记笔记是一种爱好,而对于其他人来说,当他们很容易忘记任何重要事情的小信息时,则是一种必需品。Microsoft的NTFS应用程序对于那些希望保存除常规讲座以外的重要笔记的学生特别有用。在这篇文章中,我们将描述Ubuntu24上的Ubuntu应用程序的安装。更新Ubuntu系统在安装Ubuntu安装程序之前,在Ubuntu24上我们需要确保新配置的系统已经更新。我们可以使用Ubuntu系统中最著名的“a
 如何在Ubuntu 24.04上安装Podman
Mar 22, 2024 am 11:26 AM
如何在Ubuntu 24.04上安装Podman
Mar 22, 2024 am 11:26 AM
如果您使用过Docker,则必须了解守护进程、容器及其功能。守护进程是在容器已在任何系统中使用时在后台运行的服务。Podman是一个免费的管理工具,用于管理和创建容器,而不依赖于任何守护程序,如Docker。因此,它在管理集装箱方面具有优势,而不需要长期的后台服务。此外,Podman不需要使用根级别的权限。本指南详细讨论了如何在Ubuntu24上安装Podman。更新系统我们首先要进行系统更新,打开Ubuntu24的Terminalshell。在安装和升级过程中,我们都需要使用命令行。一种简单的
 Yolov10:详解、部署、应用一站式齐全!
Jun 07, 2024 pm 12:05 PM
Yolov10:详解、部署、应用一站式齐全!
Jun 07, 2024 pm 12:05 PM
一、前言在过去的几年里,YOLOs由于其在计算成本和检测性能之间的有效平衡,已成为实时目标检测领域的主导范式。研究人员探索了YOLO的架构设计、优化目标、数据扩充策略等,取得了显着进展。同时,依赖非极大值抑制(NMS)进行后处理阻碍了YOLO的端到端部署,并对推理延迟产生不利影响。在YOLOs中,各种组件的设计缺乏全面彻底的检查,导致显着的计算冗余,限制了模型的能力。它提供了次优的效率,以及相对大的性能改进潜力。在这项工作中,目标是从后处理和模型架构两个方面进一步提高YOLO的性能效率边界。为此
 Win7电脑上安装Go语言的详细步骤
Mar 27, 2024 pm 02:00 PM
Win7电脑上安装Go语言的详细步骤
Mar 27, 2024 pm 02:00 PM
Win7电脑上安装Go语言的详细步骤Go(又称Golang)是一种由Google开发的开源编程语言,其简洁、高效和并发性能优秀,适合用于开发云端服务、网络应用和后端系统等领域。在Win7电脑上安装Go语言,可以让您快速入门这门语言并开始编写Go程序。下面将会详细介绍在Win7电脑上安装Go语言的步骤,并附上具体的代码示例。步骤一:下载Go语言安装包访问Go官
