

A proposal for more reliable locks using Redis

----------------- UPDATE: The algorithm is now described in the Redis documentation here => http://redis.io/topics/distlock. The article is left here in its older version, the updates will go into the Redis documentation instead. ---------
-----------------UPDATE: The algorithm is now described in the Redis documentation here => http://redis.io/topics/distlock. The article is left here in its older version, the updates will go into the Redis documentation instead.
-----------------
Many people use Redis to implement distributed locks. Many believe that this is a great use case, and that Redis worked great to solve an otherwise hard to solve problem. Others believe that this is totally broken, unsafe, and wrong use case for Redis.
Both are right, basically. Distributed locks are not trivial if we want them to be safe, and at the same time we demand high availability, so that Redis nodes can go down and still clients are able to acquire and release locks. At the same time a fast lock manager can solve tons of problems which are otherwise hard to solve in practice, and sometimes even a far from perfect solution is better than a very slow solution.
Can we have a fast and reliable system at the same time based on Redis? This blog post is an exploration in this area. I’ll try to describe a proposal for a simple algorithm to use N Redis instances for distributed and reliable locks, in the hope that the community may help me analyze and comment the algorithm to see if this is a valid candidate.
# What we really want?
Talking about a distributed system without stating the safety and liveness properties we want is mostly useless, because only when those two requirements are specified it is possible to check if a design is correct, and for people to analyze and find bugs in the design. We are going to model our design with just three properties, that are what I believe the minimum guarantees you need to use distributed locks in an effective way.
1) Safety property: Mutual exclusion. At any given moment, only one client can hold a lock.
2) Liveness property A: Deadlocks free. Eventually it is always possible to acquire a lock, even if the client that locked a resource crashed or gets partitioned.
3) Liveness property B: Fault tolerance. As long as the majority of Redis nodes are up, clients are able to acquire and release locks.
# Distributed locks, the naive way.
To understand what we want to improve, let’s analyze the current state of affairs.
The simple way to use Redis to lock a resource is to create a key into an instance. The key is usually created with a limited time to live, using Redis expires feature, so that eventually it gets released one way or the other (property 2 in our list). When the client needs to release the resource, it deletes the key.
Superficially this works well, but there is a problem: this is a single point of failure in our architecture. What happens if the Redis master goes down?
Well, let’s add a slave! And use it if the master is unavailable. This is unfortunately not viable. By doing so we can’t implement our safety property of the mutual exclusion, because Redis replication is asynchronous.
This is an obvious race condition with this model:
1) Client A acquires the lock into the master.
2) The master crashes before the write to the key is transmitted to the slave.
3) The slave gets promoted to master.
4) Client B acquires the lock to the same resource A already holds a lock for.
Sometimes it is perfectly fine that under special circumstances, like during a failure, multiple clients can hold the lock at the same time.
If this is the case, stop reading and enjoy your replication based solution. Otherwise keep reading for a hopefully safer way to implement it.
# First, let’s do it correctly with one instance.
Before to try to overcome the limitation of the single instance setup described above, let’s check how to do it correctly in this simple case, since this is actually a viable solution in applications where a race condition from time to time is acceptable, and because locking into a single instance is the foundation we’ll use for the distributed algorithm described here.
To acquire the lock, the way to go is the following:
SET resource_name my_random_value NX PX 30000
The command will set the key only if it does not already exist (NX option), with an expire of 30000 milliseconds (PX option).
The key is set to a value “my_random_value”. This value requires to be unique across all the clients and all the locks requests.
Basically the random value is used in order to release the lock in a safe way, with a script that tells Redis: remove the key only if exists and the value stored at the key is exactly the one I expect to be. This is accomplished by the following Lua script:
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
This is important in order to avoid removing a lock that was created by another client. For example a client may acquire the lock, get blocked into some operation for longer than the lock validity time (the time at which the key will expire), and later remove the lock, that was already acquired by some other client.
Using just DEL is not safe as a client may remove the lock of another client. With the above script instead every lock is “signed” with a random string, so the lock will be removed only if it is still the one that was set by the client trying to remove it.
What this random string should be? I assume it’s 20 bytes from /dev/urandom, but you can find cheaper ways to make it unique enough for your tasks.
For example a safe pick is to seed RC4 with /dev/urandom, and generate a pseudo random stream from that.
A simpler solution is to use a combination of unix time with microseconds resolution, concatenating it with a client ID, it is not as safe, but probably up to the task in most environments.
The time we use as the key time to live, is called the “lock validity time”. It is both the auto release time, and the time the client has in order to perform the operation required before another client may be able to acquire the lock again, without technically violating the mutual exclusion guarantee, which is only limited to a given window of time from the moment the lock is acquired.
So now we have a good way to acquire and release the lock. The system, reasoning about a non-distrubited system which is composed of a single instance, always available, is safe. Let’s extend the concept to a distributed system where we don’t have such guarantees.
# Distributed version
In the distributed version of the algorithm we assume to have N Redis masters. Those nodes are totally independent, so we don’t use replication or any other implicit coordination system. We already described how to acquire and release the lock safely in a single instance. We give for granted that the algorithm will use this method to acquire and release the lock in a single instance. In our examples we set N=5, which is a reasonable value, so we need to run 5 Redis masters in different computers or virtual machines in order to ensure that they’ll fail in a mostly independent way.
In order to acquire the lock, the client performs the following operations:
Step 1) It gets the current time in milliseconds.
Step 2) It tries to acquire the lock in all the N instances sequentially, using the same key name and random value in all the instances.
During the step 2, when setting the lock in each instance, the client uses a timeout which is small compared to the total lock auto-release time in order to acquire it.
For example if the auto-release time is 10 seconds, the timeout could be in the ~ 5-50 milliseconds range.
This prevents the client to remain blocked for a long time trying to talk with a Redis node which is down: if an instance is not available, we should try to talk with the next instance ASAP.
Step 3) The client computes how much time elapsed in order to acquire the lock, by subtracting to the current time the timestamp obtained in step 1.
If and only if the client was able to acquire the lock in the majority of the instances (at least 3), and the total time elapsed to acquire the lock is less than lock validity time, the lock is considered to be acquired.
Step 4) If the lock was acquired, its validity time is considered to be the initial validity time minus the time elapsed, as computed in step 3.
Step 5) If the client failed to acquire the lock for some reason (either it was not able to lock N/2+1 instances or the validity time is negative), it will try to unlock all the instances (even the instances it believe it was not able to lock).
# Synchronous or not?
Basically the algorithm is partially synchronous: it relies on the assumption that while there is no synchronized clock across the processes, still the local time in every process flows approximately at the same rate, with an error which is small compared to the auto-release time of the lock. This assumption closely resembles a real-world computer: every computer has a local clock and we can usually rely on different computers to have a clock drift which is small.
Moreover we need to refine our mutual exclusion rule: it is guaranteed only as long as the client holding the lock will terminate its work within the lock validity time (as obtained in step 3), minus some time (just a few milliseconds in order to compensate for clock drift between processes).
# Retry
When a client is not able to acquire the lock, it should try again after a random delay in order to try to desynchronize multiple clients trying to acquire the lock, for the same resource, at the same time (this may result in a split brain condition where nobody wins). Also the faster a client will try to acquire the lock in the majority of Redis instances, the less window for a split brain condition (and the need for a retry), so ideally the client should try to send the SET commands to the N instances at the same time using multiplexing.
It is worth to stress how important is for the clients that failed to acquire the majority of locks, to release the (partially) acquired locks ASAP, so that there is no need to wait for keys expiry in order for the lock to be acquired again (however if a network partition happens and the client is no longer able to communicate with the Redis instances, there is to pay an availability penalty and wait for the expires).
# Releasing the lock
Releasing the lock is simple and involves just to release the lock in all the instances, regardless of the fact the client believe it was able to successfully lock a given instance.
# Safety arguments
Is this system safe? We can try to understand what happens in different scenarios.
To start let’s assume that a client is able to acquire the lock in the majority of instances. All the instances will contain a key with the same time to live. However the key was set at different times, so the keys will also expire at different times. However if the first key was set at worst at time T1 (the time we sample before contacting the first server) and the last key was set at worst at time T2 (the time we obtained the reply from the last server), we are sure that the first key to expire in the set will exist for at least MIN_VALIDITY=TTL-(T2-T1)-CLOCK_DRIFT. All the other keys will expire later, so we are sure that the keys will be simultaneously set for at least this time.
During the time the majority of keys are set, another client will not be able to acquire the lock, since N/2+1 SET NX operations can’t succeed if N/2+1 keys already exist. So if a lock was acquired, it is not possible to re-acquire it at the same time (violating the mutual exclusion property).
However we want to also make sure that multiple clients trying to acquire the lock at the same time can’t simultaneously succeed.
If a client locked the majority of instances using a time near, or greater, than the lock maximum validity time (the TTL we use for SET basically), it will consider the lock invalid and will unlock the instances, so we only need to consider the case where a client was able to lock the majority of instances in a time which is less than the validity time. In this case for the argument already expressed above, for MIN_VALIDITY no client should be able to re-acquire the lock. So multiple clients will be albe to lock N/2+1 instances at the same time (with “time" being the end of Step 2) only when the time to lock the majority was greater than the TTL time, making the lock invalid.
Are you able to provide a formal proof of safety, or to find a bug? That would be very appreciated.
# Liveness arguments
The system liveness is based on three main features:
1) The auto release of the lock (since keys expire): eventually keys are available again to be locked.
2) The fact that clients, usually, will cooperate removing the locks when the lock was not acquired, or when the lock was acquired and the work terminated, making it likely that we don’t have to wait for keys to expire to re-acquire the lock.
3) The fact that when a client needs to retry a lock, it waits a time which is comparable greater to the time needed to acquire the majority of locks, in order to probabilistically make split brain conditions during resource contention unlikely.
However there is at least a scenario where a very special network partition/rejoin pattern, repeated indefinitely, may violate the system availability.
For example with N=5, two clients A and B may try to lock the same resource at the same time, nobody will be able to acquire the majority of locks, but they may be able to lock the majority of nodes if we sum the locks of A and B (for example client A locked 2 instances, client B just one instance).
Then the clients are partitioned away before they can unlock the locked instances. This will leave the resource not lockable for a time roughly equal to the auto release time. Then when the keys expire, the two clients A and B join again the partition repeating the same pattern, and so forth indefinitely.
Another point of view to see the problem above, is that we pay an availability penalty equal to “TTL” time on network partitions, so if there are continuous partitions, we can pay this penalty indefinitely.
I can’t find a simple way to have guaranteed liveness (but did not tried very hard honestly), but the worst case appears to be hard to trigger.
Basically it means that we can only provide, using this algorithm, an approximation of Property number 2.
# Performance, crash-recovery and fsync
Many users using Redis as a lock server need high performance in terms of both latency to acquire and release a lock, and number of acquire / release operations that it is possible to perform per second. In order to meet this requirement, the strategy to talk with the N Redis servers to reduce latency is definitely multiplexing (or poor’s man multiplexing, which is, putting the socket in non-blocking mode, send all the commands, and read all the commands later, assuming that the RTT between the client and each instance is similar).
However there is another consideration to do about persistence if we want to target a crash-recovery system model.
Basically to see the problem here, let’s assume we configure Redis without persistence at all. A client acquires the lock in 3 of 5 instances. One of the instances where the client was able to acquire the lock is restarted, at this point there are again 3 instances that we can lock for the same resource, and another client can lock it again, violating the safety property of exclusivity of lock.
If we enable AOF persistence, things will improve quite a bit. For example we can upgrade a server by sending SHUTDOWN and restarting it. Because Redis expires are semantically implemented so that virtually the time still elapses when the server is off, all our requirements are fine.
However everything is fine as long as it is a clean shutdown. What about a power outage? If Redis is configured, as by default, to fsync on disk every second, it is possible that after a restart our key is missing. Long story short if we want to guarantee the lock safety in the face of any kind of instance restart, we need to enable fsync=always in the persistence setting. This in turn will totally ruin performances to the same level of CP systems that are traditionally used to implement distributed locks in a safe way.
The good news is that because in our algorithm we don’t stop to acquire locks as soon as we reach the majority of the servers, the actual probability of safety violation is small, because most of the times the lock will be hold in all the 5 servers, so even if one restarts without a key, it is practically unlikely (but not impossible) that an actual safety violation happens. Long story short, this is an user pick, and a big trade off. Given the small probability for a race condition, if it is acceptable that with an extremely small probability, after a crash-recovery event, the lock may be acquired at the same time by multiple clients, the fsync at every operation can (and should) be avoided.
# Reference implementation
I wrote a simple reference implementation in Ruby, backed by redis-rb, here: http://github.com/antirez/redlock-rb
# Want to help?
If you are into distributed systems, it would be great to have your opinion / analysis.
Also reference implementations in other languages could be great.
Thanks in advance!
EDIT: I received feedbacks in this blog post comment and via Hacker News that's worth to incorporate in this blog post.
1) As Steven Benjamin notes in the comments below, if after restarting an instance we can make it unavailable for enough time for all the locks that used this instance to expire, we don't need fsync. Actually we don't need any persistence at all, so our safety guarantee can be provided with a pure in-memory configuration.
An example: previously we described the example race condition where a lock is obtained in 3 servers out of 5, and one of the servers where the lock was obtained restarts empty: another client may acquire the same lock by locking this server and the other two that were not locked by the previous client. However if the restarted server is not available for queries enough time for all the locks that were obtained with it to expire, we are guaranteed this race is no longer possible.
2) The Hacker News user eurleif noticed how it is possible to reacquire the lock as a strategy if the client notices it is taking too much time in order to complete the operation. This can be done by just extending an existing lock, sending a script that extends the expire of the value stored at the key is the expected one. If there are no new partitions, and we try to extend the lock enough in advance so that the keys will not expire, there is the guarantee that the lock will be extended.
3) The Hacker News user mjb noted how the term "skew" is not correct to describe the difference of the rate at which different clocks increment their local time, and I'm actually talking about "Drift". I'm replacing the word "skew" with "drift" to use the correct term.
Thanks for the very useful feedbacks. Comments

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 解决kernel_security_check_failure蓝屏的17种方法
Feb 12, 2024 pm 08:51 PM
解决kernel_security_check_failure蓝屏的17种方法
Feb 12, 2024 pm 08:51 PM
Kernelsecuritycheckfailure(内核检查失败)就是一个比较常见的停止代码类型,可蓝屏错误出现不管是什么原因都让很多的有用户们十分的苦恼,下面就让本站来为用户们来仔细的介绍一下17种解决方法吧。kernel_security_check_failure蓝屏的17种解决方法方法1:移除全部外部设备当您使用的任何外部设备与您的Windows版本不兼容时,则可能会发生Kernelsecuritycheckfailure蓝屏错误。为此,您需要在尝试重新启动计算机之前拔下全部外部设备。
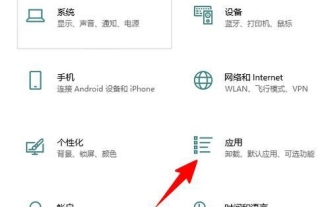 Win10如何卸载Skype for Business?电脑上的skype怎么彻底卸载方法
Feb 13, 2024 pm 12:30 PM
Win10如何卸载Skype for Business?电脑上的skype怎么彻底卸载方法
Feb 13, 2024 pm 12:30 PM
Win10skype可以卸载吗是很多用户们都想知道的一个问题,因为很多的用户们发现自己电脑上的默认程序上有这个应用,担心删除后会影响到系统的运行,下面就让本站来为用户们来仔细的介绍一下Win10如何卸载SkypeforBusiness吧。Win10如何卸载SkypeforBusiness1、在电脑桌面点击Windows图标,再点击设置图标进入。2、点击“应用”。3、在搜索框中输入“Skype”,点击选中找到的结果。4、点击“卸载”。5

 foreach和for循环的区别是什么
Jan 05, 2023 pm 04:26 PM
foreach和for循环的区别是什么
Jan 05, 2023 pm 04:26 PM
区别:1、for通过索引来循环遍历每一个数据元素,而forEach通过JS底层程序来循环遍历数组的数据元素;2、for可以通过break关键词来终止循环的执行,而forEach不可以;3、for可以通过控制循环变量的数值来控制循环的执行,而forEach不行;4、for在循环外可以调用循环变量,而forEach在循环外不能调用循环变量;5、for的执行效率要高于forEach。
 如何避免JAVA中简单的for循环出现异常?
Apr 26, 2023 pm 12:58 PM
如何避免JAVA中简单的for循环出现异常?
Apr 26, 2023 pm 12:58 PM
引言实际的业务项目开发中,大家应该对从给定的list中剔除不满足条件的元素这个操作不陌生吧?很多同学可以立刻想出很多种实现的方式,但你想到的这些实现方式都是人畜无害的吗?很多看似正常的操作其实背后是个陷阱,很多新手可能稍不留神就会掉入其中。倘若不幸踩中:代码运行时直接抛异常报错,这个算是不幸中的万幸,至少可以及时发现并去解决代码运行不报错,但是业务逻辑莫名其妙的出现各种奇怪问题,这种就比较悲剧了,因为这个问题稍不留神的话,可能就会给后续业务埋下隐患。那么,到底有哪些实现方式呢?哪些实现方式可能会
 Python中的常见流程控制结构有哪些?
Jan 20, 2024 am 08:17 AM
Python中的常见流程控制结构有哪些?
Jan 20, 2024 am 08:17 AM
Python中常见的流程控制结构有哪几种?在Python中,流程控制结构是用来决定程序的执行顺序的重要工具。它们允许我们根据不同的条件执行不同的代码块,或者重复执行一段代码。下面将介绍Python中常见的流程控制结构,并提供相应的代码示例。条件语句(if-else):条件语句允许我们根据不同的条件执行不同的代码块。它的基本语法是:if条件1:#当条件
 6个实例,8段代码,详解 Python 中的 For 循环
Apr 11, 2023 pm 07:43 PM
6个实例,8段代码,详解 Python 中的 For 循环
Apr 11, 2023 pm 07:43 PM
Python 支持for循环,它的语法与其他语言(如JavaScript 或Java)稍有不同。下面的代码块演示如何在Python中使用for循环来遍历列表中的元素:上述的代码段是将三个字母分行打印的。你可以通过在print语句的后面添加逗号“,”将输出限制在同一行显示(如果指定打印的字符很多,则会“换行”),代码如下所示:当你希望通过一行而不是多行显示文本中的内容时,可以使用上述形式的代码。Python还提供了内置
 利用Go语言for循环快速实现翻转功能
Mar 25, 2024 am 10:45 AM
利用Go语言for循环快速实现翻转功能
Mar 25, 2024 am 10:45 AM
使用Go语言实现翻转功能可以通过for循环非常快速地实现。翻转功能是将字符串或数组中的元素顺序颠倒,可以应用在很多场景中,例如字符串翻转、数组元素翻转等。下面我们来看一下如何利用Go语言的for循环来实现字符串和数组的翻转功能,并附上具体的代码示例。字符串翻转:packagemainimport("fmt")fun
