

sphinx 源码阅读之 分词,压缩索引,倒排

前言 sphinx 在创建索引前需要做下面几件事:有数据源(pSource),有分词器(pTokenizer),有停止词Stopword 和 字典(pDict),索引引擎。 我们假设 数据源是 mysql, 分词器是 utf8 分词器。 索引前背景介绍 第一步是准备数据源。 这里采用 mysql 数据源。 mysq
前言
sphinx 在创建索引前需要做下面几件事:有数据源(pSource),有分词器(pTokenizer),有停止词Stopword 和 字典(pDict),索引引擎。
我们假设 数据源是 mysql, 分词器是 utf8 分词器。
索引前背景介绍
第一步是准备数据源。
这里采用 mysql 数据源。
mysql 数据的特点是一行一个记录。
每个记录有相同的字段。
每个字段可能代表数字,字符串,时间,二进制等信息,我们都可以按字符串处理即可。
<code>//数据源 CSphSource_MySQL * pSrcMySQL = new CSphSource_MySQL (); CSphSource * pSource = pSrcMySQL; </code>
第二步准备分词器和字典。
这里不多说分词器,以后会专门写一篇记录来讲解分词器。
分词器依靠字典,可以把一个字符串分割为一些词语(word)。
然后根据这些词语,我们可以把mysql的每条记录每个字段都分割为若干词语,这里成为分词。
分割后这个分词需要保留几个信息:什么分词,属于哪个记录,属于哪个字段,在字段中的位置。
分词我们会hash (crc32) 成一个数字,冲突了就当做一个词了。
记录标示就是用自增整数ID.
字段一般不会很多,我们假设最多255个,使用8位可以表示。
字段的位置不确定,但是一个字段的内容也不会很多,我们用24位表示足够了。
所以哪个字段和字段的哪个位置就可以用一个32位整数代替了。
这样一个分词就可以用三个整数
<code>//分词器 pTokenizer = sphCreateUTF8Tokenizer (); pSource->SetTokenizer ( pTokenizer ); //字典 CSphDict_CRC32 * pDict = new CSphDict_CRC32 ( iMorph ); pSource->SetDict ( pDict ); </code>
一个分词称为一个hit, 数据结构如下
<code>struct CSphWordHit {
DWORD m_iDocID; //文档ID, 唯一代表一个记录
DWORD m_iWordID; //单词ID, 对单词的hash值,可以理解为唯一标示
DWORD m_iWordPos; //储存两个信息:字段位置(高8位)和分词的位置(低24位)
};
</code>我们一条记录一条记录的把所有的记录都分词了,就得到一个分词列表了。
由于这个列表很大,我们需要分成多块储存,这里假设最多16块吧。
对于每块,储存前先排序一下,这样我们就得到 16 个 有序的数组了。
然后我们就可以创建索引了。
<code>//索引 CSphIndex * pIndex = sphCreateIndexPhrase ( sIndexPath ); //开始创建索引 pIndex->Build ( pDict, pSource, iMemLimit ) </code>
其中 一切准备完毕后进入 Build 函数。
build 函数创建搜索
进入 build 函数后先准备内容。
在执行 build 函数时 ,先逐条读取记录,然后对每条记录的每个字段会进行分词(Next函数),存在 hit 数据结构中。
而且会把 hit 数据按指定块大小排序后压缩储存在 *.spr 文件中。
块信息储存在 bins 数组中,块数最多16块, 块数用 iRawBlocks 表示。
接下来就是关键的创建压缩索引了。
首先创建索引对象。
<code>cidxCreate() //打开索引文件,先写入 m_tHeader 信息 和 cidxPagesDir 信息。 fdIndex = new CSphWriter_VLN ( ".spi" ); fdIndex->PutRawBytes ( &m_tHeader, sizeof(m_tHeader) ); //cidxPagesDir 数组全是 -1 fdIndex->PutBytes ( cidxPagesDir, sizeof(cidxPagesDir) ); //打开压缩数据文件,先写入一个开始符 bDummy fdData = new CSphWriter_VLN ( ".spd" ); BYTE bDummy = 1; fdData->PutBytes ( &bDummy, 1 ); </code>
外部排序
现在我们的背景是有16个已经排序的数据存在磁盘上。
由于数据量很大,我们不能一次性全部读进来。
我们的目标是依次挑出最小的hit,然后交给索引引擎处理。
sphinx 使用了 CSphHitQueue 这个数据结构。
CSphHitQueue 你猜是什么? 队列? 恭喜你,猜错了。
CSphHitQueue 是一个最小堆。
且 堆的最大个数是 iRawBlocks。
由于 iRawBlocks 个 hits 数组已经排序,所以我们只需要得到 已排序的hits数组的第一个元素,就可以用堆得到最小的那个元素了。
然后我们把最小的这个元素建索引压缩储存,删除最小元素,并取出最小元素所在 hits数组中下一个元素,扔到堆中。
这样就可以从小到大取出所有的元素,并逐个建立索引压缩储存了。
这段话看不懂的话,可以看下面的图。

创建索引压缩储存
其中创建索引压缩储存主要依靠这个函数
<code>cidxHit ( tQueue.m_pData ); </code>
其中 tQueue.m_pData 的数据结构如下
<code>/// fat hit, which is actually stored in VLN index
struct CSphFatHit{
DWORD m_iDocID; ///</code>hit 是先按 m_iWordID 排序, 相等了再按 m_iDocID 排序, 最后才按 m_iWordPos 排序的。
现在我们先不考虑上面的堆,我们假设所有的 hit 已经在一个数组中了,且按上面的规则排序了。
现在我们想做的是对这个 hit 数组创建索引,并压缩储存。
我们现在来看看这个久等的代码吧。
<code>void CSphIndex_VLN::cidxHit ( CSphFatHit * hit ){
// next word
if ( m_tLastHit.m_iWordID!=hit->m_iWordID ){
// close prev hitlist, if any
if ( m_tLastHit.m_iWordPos ){
fdData->ZipInt ( 0 );
m_tLastHit.m_iWordPos = 0;
}
// flush prev doclist, if any
if ( m_dDoclist.GetLength() ){
// finish writing wordlist entry
fdIndex->ZipOffset ( fdData->m_iPos - m_iLastDoclistPos );
fdIndex->ZipInt ( m_iLastWordDocs );
fdIndex->ZipInt ( m_iLastWordHits );
m_iLastDoclistPos = fdData->m_iPos;
m_iLastWordDocs = 0;
m_iLastWordHits = 0;
// write doclist
fdData->ZipOffsets ( &m_dDoclist );
fdData->ZipInt ( 0 );
m_dDoclist.Reset ();
// restart doclist deltas
m_tLastHit.m_iDocID = 0;
m_iLastHitlistPos = 0;
}
if ( !hit->m_iWordPos ){
fdIndex->ZipInt ( 0 );
return;
}
DWORD iPageID = hit->m_iWordID >> SPH_CLOG_BITS_PAGE;
if ( m_iLastPageID!=iPageID ){
// close wordlist
fdIndex->ZipInt ( 0 );
m_tLastHit.m_iWordID = 0;
m_iLastDoclistPos = 0;
// next map page
m_iLastPageID = iPageID;
cidxPagesDir [ iPageID ] = fdIndex->m_iPos;
}
fdIndex->ZipInt ( hit->m_iWordID - m_tLastHit.m_iWordID );
m_tLastHit.m_iWordID = hit->m_iWordID;
}
// next doc
if ( m_tLastHit.m_iDocID!=hit->m_iDocID ){
if ( m_tLastHit.m_iWordPos ){
fdData->ZipInt ( 0 );
m_tLastHit.m_iWordPos = 0;
}
m_dDoclist.Add ( hit->m_iDocID - m_tLastHit.m_iDocID );
m_dDoclist.Add ( hit->m_iGroupID ); // R&D: maybe some delta-coding would help here too
m_dDoclist.Add ( hit->m_iTimestamp );
m_dDoclist.Add ( fdData->m_iPos - m_iLastHitlistPos );
m_tLastHit.m_iDocID = hit->m_iDocID;
m_iLastHitlistPos = fdData->m_iPos;
// update per-word stats
m_iLastWordDocs++;
}
// the hit
// add hit delta
fdData->ZipInt ( hit->m_iWordPos - m_tLastHit.m_iWordPos );
m_tLastHit.m_iWordPos = hit->m_iWordPos;
m_iLastWordHits++;
}
</code>上面的代码主要做了这个几件事。
第一,根据 m_iWordID 将分词分为 2014 块。
并使用 cidxPagesDir 记录块的偏移量(还记得索引文件第二个写入的数据吗)。
第二,对于每一块,我们按分词分组,并在索引文件 spi 中储存每个词组的信息。
具体储存的信息如下
- 和上一个分词(wordID)的偏差
- 这个分词组在 spd 文件内的长度
- 这个分词记录的变化次数
- 这个分词的 hit 数量
第三,对于每个hit,我们存两部分信息。
- 位置(pos)偏移量信息
- 文档(docId)偏移量的信息
上面的三部分信息都储存后,我们就可以快速的解析出来。
模拟索引数据与还原数据
比如对于下面的数据
| wordId | docId | pos |
|---|---|---|
| 1 | 1 | 2 |
| 1 | 1 | 3 |
| 1 | 2 | 3 |
| 1 | 3 | 4 |
| 2 | 1 | 1 |
在 spd 文件中,我们可以得到下面的序列
<code>2 1 0 3 0 4 0 1 1 1 0 1 1 1 3 1 1 1 2 0 1 </code>
其中 2 1 0 3 0 4 0 我们很容易看出来。
当 wordId 和 docId 不变时,每条 hit 会储存一个 pos 的偏差。
当 wordId 不变, docId 改变时,我们会先储存一个0, 然后偏差重新开始计算。
当 wordId 改变时, 把存在 m_dDoclist 中的关于 docId 变化的信息储存起来。
一个变化储存四条元信息:docId 变化偏差, m_iGroupID,m_iTimestamp, spi 文件内的偏差。
在 spi 文件中,我们可以得到下面的序列
<code>1 7 3 4 1 </code>
这里的代码实际上也分为两部分。
第一部分是 wordId 的偏差。 然后三个元信息是这个 wordId 的信息, 上面已经提过了,这里就不说了
依次扫面这个 2 1 0 3 0 4 0, 我们可以恢复 pos 字段 2 3 3 4.
而且 2 3 的 wordId 和 docID 相同。
| wordId | docId | pos |
|---|---|---|
| 2 | ||
| 3 | ||
| 3 | ||
| 4 |
根据 索引信息 1 7 3 4 得到这样的信息: wordId 偏移1,长度偏移数7 ,记录变化数3, hit数4.
于是先决定前四个 wordId。
| wordId | docId | pos |
|---|---|---|
| 1 | 2 | |
| 1 | 3 | |
| 1 | 3 | |
| 1 | 4 |
长度偏移数7 信息可以知道接下来的数据就是数据的第二部分了。
又由于之前遇到 3 个0, 所以有三组数据:, ,
根据 我们可以知道前两个 docId 了。
| wordId | docId | pos |
|---|---|---|
| 1 | 1 | 2 |
| 1 | 1 | 3 |
| 1 | 3 | |
| 1 | 4 |
然后根据 可以知道第三个 docId。 偏移为1, 加上上个 docId 的值,就是 docId = 2 了。
| wordId | docId | pos |
|---|---|---|
| 1 | 1 | 2 |
| 1 | 1 | 3 |
| 1 | 2 | 3 |
| 1 | 4 |
最后就是 决定第四个 docId 是 3 了。
| wordId | docId | pos |
|---|---|---|
| 1 | 1 | 2 |
| 1 | 1 | 3 |
| 1 | 2 | 3 |
| 1 | 3 | 4 |
看到这里,大家发现最后一个信息没有储存或者储存不完整,也不能解析出来。
所以在最后 sphinx 会调用 一个 下面的代码
<code>//加入结束符 CSphFatHit tFlush; tFlush.m_iDocID = 0; tFlush.m_iGroupID = 0; tFlush.m_iWordID = 0; tFlush.m_iWordPos =0; cidxHit ( &tFlush ); //填充 m_tHeader 和 cidxPagesDir 信息。 cidxDone (); </code>
然后我们实际的输出时这个样子:
<code>data: 2 1 0 3 0 4 0 1 1 1 0 1 1 1 3 1 1 1 2 0 1 0 1 1 1 20 0 index: 1 7 3 4 1 15 1 1 0 </code>
接着上面的输出就是 索引是 0 1 0 1 1 1 20, 数据时 1 15 1 1.
0 是 分词的间隔,所以从第二个开始。
决定 了 pos 值为 1.
决定了 wordId 值为 1 + 1 = 2.
决定了 docId 值为 1.
| wordId | docId | pos |
|---|---|---|
| 1 | 1 | 2 |
| 1 | 1 | 3 |
| 1 | 2 | 3 |
| 1 | 3 | 4 |
| 2 | 1 | 1 |
最后还有一个0.
决定了解析索引结束。
| wordId | docId | pos |
|---|---|---|
| 1 | 1 | 2 |
| 1 | 1 | 3 |
| 1 | 2 | 3 |
| 1 | 3 | 4 |
| 2 | 1 | 1 |
| 0 | 0 | 0 |
测试代码可以参考这里 .
推理 - 搜索信息
假设我们又上面的压缩的信息了。
我们要搜索一个词时,会如何工作呢?
假设我们已经得到这个词的 wordId 了,只需要二分一下,就可以再 O(log(1024)) 的时间内得到 wordId 在那个块内。
找到一个块内,出现一个问题,我们不能再次二分查找来找到对应的分词列表。 因为这个 index 储存的是和上一个分词的相对偏移量,那只好全部读入内存,扫描一遍对偏移量求和,然后才能找到对应的词。
这个过程中我们进行了两次 IO 操作。
第一次读取块列表信息 cidxPagesDir。
第二次读取选中的那一块的所有数据。
虽然储存偏移量节省了一些磁盘储存,但是却是用扫描整块数据为代价的。我们本来可以直接二分整块数据的。
不管怎样,我们在索引中找到了需要查找的那个分词的位置。
然后我们可以在数据文件内读取对应的信息,然后得到对应记录的id了。
当然,上面这个只是我的推理,下面我们来看看 sphinx 是怎么搜索的吧。
sphinx 搜索方法
看 sphinx 的搜索方法,只需要看 CSphIndex_VLN 的 QueryEx 函数即可。
首先对查询的语句进行分词,然后读取索引头 m_tHeader, 读取分块信息 cidxPagesDir。
然后就对分词进行搜索了。
为了防止相同的分词重复查找,这里采用二层循环,先来判断这个分词之前是否搜索过,搜索过就记下搜索过的那个词的位置。
没搜索过,就搜索。
核心代码
<code>// lookup this wordlist page
// offset might be -1 if page is totally empty
SphOffset_t iWordlistOffset = cidxPagesDir [ qwords[i].m_iWordID >> SPH_CLOG_BITS_PAGE ];
if ( iWordlistOffset>0 ){
// set doclist files
qwords[i].m_rdDoclist.SetFile ( tDoclist.m_iFD );
qwords[i].m_rdHitlist.SetFile ( tDoclist.m_iFD );
// read wordlist
rdIndex.SeekTo ( iWordlistOffset );
// restart delta decoding
wordID = 0;
SphOffset_t iDoclistOffset = 0;
for ( ;; ){
// unpack next word ID
DWORD iDeltaWord = rdIndex.UnzipInt();
if ( !iDeltaWord ) break;// wordlist chunk is over
wordID += iDeltaWord;
// unpack next offset
SphOffset_t iDeltaOffset = rdIndex.UnzipOffset ();
iDoclistOffset += iDeltaOffset;
assert ( iDeltaOffset );
// unpack doc/hit count
int iDocs = rdIndex.UnzipInt ();
int iHits = rdIndex.UnzipInt ();
assert ( iDocs );
assert ( iHits );
// break on match or list end
if ( wordID>=qwords[i].m_iWordID ){
if ( wordID==qwords[i].m_iWordID ){
qwords[i].m_rdDoclist.SeekTo ( iDoclistOffset );
qwords[i].m_iDocs = iDocs;
qwords[i].m_iHits = iHits;
}
break;
}
}
}
</code>看了这个代码,和我想的有点出入,但是总体思路还是一样的。
它是把所有的 cidxPagesDir 全储存起来了,这样直接定位到指定的位置了。少了一个二分搜索。
定位到某个块之后, 果然采用暴力循环来一个一个的增加偏移,然后查找对应的分词。
找到了记录对应的位置的四大元信息。
再然后由于数据量已经很小了,就把匹配的数据取出来即可。
当然,取数据的时候会进行布尔操作,而且会加上权值计算,这样就搜索满足条件的前若干条了。
原文地址:sphinx 源码阅读之 分词,压缩索引,倒排, 感谢原作者分享。

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题
 7651
7651
 15
1392
52
91
11
73
19
36
110
15
1392
52
91
11
73
19
36
110

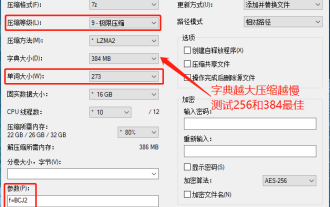 7-zip最大压缩率设置,7zip如何压缩到最小
Jun 18, 2024 pm 06:12 PM
7-zip最大压缩率设置,7zip如何压缩到最小
Jun 18, 2024 pm 06:12 PM
发现某下载网站下载的压缩包,解压后再打包会比原来的压缩包大一些,小的几十Kb的差别,大的几十Mb的差别,如果上传到云盘或付费空间,文件少无所谓,文件多的话,大大的增加储存成本。特意研究了下,有需要的可以借鉴。压缩等级:9-极限压缩字典大小:256或384,字典越压缩越慢,256MB之前压缩率差别较大,384MB后压缩率无差别单词大小:最大273参数:f=BCJ2,测试加参数压缩率会高一些
 oracle索引类型有哪些
Nov 16, 2023 am 09:59 AM
oracle索引类型有哪些
Nov 16, 2023 am 09:59 AM
oracle索引类型有:1、B-Tree索引;2、位图索引;3、函数索引;4、哈希索引;5、反向键索引;6、局部索引;7、全局索引;8、域索引;9、位图连接索引;10、复合索引。详细介绍:1、B-Tree索引,是一种自平衡的、可以高效地支持并发操作的树形数据结构,在Oracle数据库中,B-Tree索引是最常用的一种索引类型;2、位图索引,是一种基于位图算法的索引类型等等。
 减小win10录屏文件大小的建议
Jan 04, 2024 pm 12:05 PM
减小win10录屏文件大小的建议
Jan 04, 2024 pm 12:05 PM
许多的小伙伴都需要录屏进行办公或者传输文件,但是有时候会出现文件过大的问题制造了很多麻烦,下面就给大家带来了文件过大的解决方法,一起看看吧。win10录屏文件太大怎么办:1、下载软件格式工厂来进行压缩文件。下载地址>>2、进入主页面,点击“视频-MP4”选项。3、在转换格式页面中点击“添加文件”,选择要压缩的MP4文件。4、点击页面“输出配置”,通过输出质量来压缩文件。5、下拉配置列表选择“低质量和大小”点击“确定”。6、点击“确定”完成视频文件的导入。7、点击“开始”进行转化。8、完成后即可
 如何在沉浸式阅读器中使用Microsoft Reader Coach
Mar 09, 2024 am 09:34 AM
如何在沉浸式阅读器中使用Microsoft Reader Coach
Mar 09, 2024 am 09:34 AM
在这篇文章中,我们将向你展示如何在WindowsPC上的沉浸式阅读器中使用Microsoft阅读教练。阅读指导功能帮助学生或个人练习阅读并培养他们的识字技能。你从阅读支持的应用程序中的一段或一份文档开始,基于此,你的阅读报告由阅读教练工具生成。阅读报告显示了阅读的准确性、阅读所用的时间、每分钟的正确单词数,以及你在阅读时发现最具挑战性的单词。你还将能够练习这些单词,这总体上有助于培养你的阅读技能。目前,仅有Office或Microsoft365(包括OneNoteforWeb和WordforWe
 PHP代码在浏览器中如何显示源码而不被解释执行?
Mar 11, 2024 am 10:54 AM
PHP代码在浏览器中如何显示源码而不被解释执行?
Mar 11, 2024 am 10:54 AM
PHP代码在浏览器中如何显示源码而不被解释执行?PHP是一种服务器端脚本语言,通常用于开发动态网页。当PHP文件在服务器上被请求时,服务器会解释执行其中的PHP代码,并将最终的HTML内容发送到浏览器以供显示。然而,有时我们希望在浏览器中直接展示PHP文件的源代码,而不是被执行。本文将介绍如何在浏览器中显示PHP代码的源码,而不被解释执行。在PHP中,可以使
 wps怎么压缩文件夹打包发送
Mar 20, 2024 pm 12:58 PM
wps怎么压缩文件夹打包发送
Mar 20, 2024 pm 12:58 PM
办公人员在工作中使用wps软件进行操作的频率特别地多,有时一天会输入多个文件,然后发送给领导或发送到指定位置,那么wps软件如何压缩文件夹打包发送呢,下面小编就教大家这个操作步骤。首先,将要发送的文件和文件夹整理到同一个文件夹中。如果有很多文件,最好对每个文件进行命名,这样在发送时更易识别。 第二步,这个时候单击这个大的文件夹,然后点击鼠标右键。选择“添加到压缩文件”。 第三步,这个时候软件会自动帮我们打包我们的文件,选项“压缩到XX.zip”,这个zip就是打包的格式,然后点击立即压缩。
 【Python NLTK】教程:轻松入门,玩转自然语言处理
Feb 25, 2024 am 10:13 AM
【Python NLTK】教程:轻松入门,玩转自然语言处理
Feb 25, 2024 am 10:13 AM
1.NLTK简介NLTK是python编程语言的一个自然语言处理工具包,由StevenBird和EdwardLoper于2001年创建。NLTK提供了广泛的文本处理工具,包括文本预处理、分词、词性标注、句法分析、语义分析等,可以帮助开发者轻松地处理自然语言数据。2.NLTK安装NLTK可以通过以下命令安装:fromnltk.tokenizeimportWord_tokenizetext="Hello,world!Thisisasampletext."tokens=word_tokenize(te
 网站在线看源码
Jan 10, 2024 pm 03:31 PM
网站在线看源码
Jan 10, 2024 pm 03:31 PM
可以使用浏览器的开发者工具来查看网站的源代码,在Google Chrome浏览器中:1、打开 Chrome 浏览器,访问要查看源代码的网站;2、右键单击网页上的任何位置,然后选择“检查”或按下快捷键 Ctrl + Shift + I打开开发者工具;3、在开发者工具的顶部菜单栏中,选择“Elements”选项卡;4、看到网站的 HTML 和 CSS 代码即可。
