

php采集入门教程,教你如何写采集

php采集入门教程,教你如何写采集
我们第一步是采集所有的连接,我们这个可不是简单的采集一篇文章哦,我们要做的是采集整本书,并且保存到一个文本,因为现在MP3普及了,都可以看电子书了。
一本书要怎么保存呢,当然是要用书名保存便于查找拉,我们先来采集这本书的标题,
先来看一下原形:
规律是:
我们来写一下正则表达式吧,不要告诉我不会,不会就来湖南拉,嘿嘿很多大鸟的。
正则表达式:
下面开始开工拉!我们首先要获得资源,这里需要用到一个函数:
file_get_contents()
介绍:
主要功能:将整个文件读入一个字符串
原形是:string file_get_contents
( string filename [, bool use_include_path [, resource context [, int offset [, int maxlen]]]] )
具体什么意思呢,其实就是告诉你在某个资源内搜索符合规定的字符串并赋予给一个变量
上边是开始需要用到的,我们了解一点就开始写一点那样更能够深刻的理解并且能记住,我来分析下写程序的思路:
我们采集一个地址,不会是就采集一本书把所以我们的采集地址是变化的,变化的用什么呢?这个时候一个硕大的粉笔扔了过来,我不是告诉你了吗?变量,一个严厉的王建军老师,用尽了全身力气,汇集在粉笔上对我无情的扔了过来,我想哭。。。。。。。老师打人了!!!!!!!!打家来看啊。
用变量好的,那就用变量,我们获取地址,代码如下:
$url = "http://book.sina.com.cn/nzt/lit/zhuxian2/index.shtml";// 图书地址
有了上边讲的,现在应该可以完全写出来了,开始代码:
//****************************************************************
$url = "http://book.sina.com.cn/nzt/lit/zhuxian2/index.shtml";// 图书地址
$ver = "old"; //新旧版本
//因为图书他的页面又两种板式,所以我们要在这里区别一下
//****************************************************************
// 获取页面代码 file_get_contents() 把文件读入一个字符串,下边的时候需要用到
$r = file_get_contents($url);
//在上边获取的字符串中搜索标题,并赋值给变量$booktitle,$booktitle是数组,/is就凑活理解成开始吧!
preg_match("//is",$r,$booktitle);
//把第一个出现捕获的标题赋值给变量bookname。
$bookname = $booktitle[1]; //书名
//print_r ($booktitle);die();不理解的输出这个看看,嘿嘿,帮助大家理解
/*************************************************************************************
*原形:
*规律是:
*ISU是正则的一种模式,该模式是非贪婪模式,也就是说只要匹配上就结束
*************************************************************************************/
$preg = '/
/********************************************************************************
*preg_match_all进行全局正则表达式匹配
*原形:
*
int preg_match_all
*
( string pattern, string subject, array matches [, int flags] )
*意思是:在全局搜索资源变量$preg,得到一个数组赋值给一个变量$zj,这个变量也就是数组了。
*取得其中的资源的时候用标示就可以,不会的看下数组哦!
*汪老师说了,不会数组的给我出去啃书,什么时候会了进来
**********************************************************************************/
preg_match_all($preg, $r, $zj);
//print_r ($zj);die();不理解的输出这个看看,嘿嘿,帮助大家理解
// 计算标题数量,我是问了最后提示大家看又多少章节,采集了多少
$bookzj = count($zj[1]);
//判断你要采集的板式是那种哦,因为内容开始不一样哦,其实可以自动判断的,我也写成了,但是不发布,因为很简单
if ($ver=="new"){
$content_start = "";
$content_end = "";
}
if ($ver=="old"){
$content_start = "";
$content_end = "
";
}
//采集后的文件,然后那来进行处理.这个是设置编码的,为什么是这个呢,因为你看下网站源码,嘿嘿!!!
header("Content-Type:text/html;charset=gb2312");
/*****************************************************************************************
*从1到136页的内容一次合并.这个是最爽的...打个版权,以免有人侵权,嘿嘿,好像我就在侵权哦!!!
*某某一定想杀人,这句意思就是写个版权,创建文件。
*****************************************************************************************/
writer($bookname." 共".$bookzj."节rn帅哥刘并于".date("D M j G:i:s T Y")."为了毕业而设计小说整理收集rn", "./ljy/".$bookname.".txt","w+");
/*****************************************************************************************
*从1到136页的内容一次合并.这个是最爽的...打个版权,以免有人侵权,嘿嘿,好像我就在侵权哦!!!
*某某一定想杀人,这句意思就是写个版权,创建文件。
*****************************************************************************************/
for ($i=0;$i
//echo "http://book.sina.com.cn".$zj[1][$i]".shtml";die();
$str = file_get_contents("http://book.sina.com.cn".$zj[1][$i].".shtml");
preg_match("/(
$title = str_replace("_读书频道_新浪网","",preg_replace("//s","",$title[2]));
/***************************************************************************
*preg_replace执行正则表达式的搜索和替换
*str_replace用法真的不好说,就看例子吧!其实就是一个替换
* str = "abcabc".replace(/a/g, "d"); //结果为 dbcdbc
* str = "abcabc".replace(/a/, "d"); //结果为 dbcabc
***************************************************************************/
preg_match("/(".$content_start.")(.*?)(".$content_end.")/is",$str,$content);
$content = preg_replace("//s","",str_replace("
$content = str_replace("
","",preg_replace("/^[s]*n/is","",$content));
$content = str_replace(" ? "," ",preg_replace("/^[s]*n/is","",$content));
$result = " rn第".($i+1)."节--------".$title."_汪老师就是帅 --------- rn".$content;
//var_dump ($result);die();
writer($result, "./ailaopo/".$bookname.".txt","a+");
echo "小说".$bookname."共".$bookzj."节,现在整理到第".$i."节 _".$title."
";
}
echo "小说".$bookname."共".$bookzj."节 已全部整理完成!";
function writer($content,$url,$mode)
{
$fp = fopen($url, $mode);
fwrite($fp, $content);
fclose($fp);
}
?>

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 解决方法:您的组织要求您更改 PIN 码
Oct 04, 2023 pm 05:45 PM
解决方法:您的组织要求您更改 PIN 码
Oct 04, 2023 pm 05:45 PM
“你的组织要求你更改PIN消息”将显示在登录屏幕上。当在使用基于组织的帐户设置的电脑上达到PIN过期限制时,就会发生这种情况,在该电脑上,他们可以控制个人设备。但是,如果您使用个人帐户设置了Windows,则理想情况下不应显示错误消息。虽然情况并非总是如此。大多数遇到错误的用户使用个人帐户报告。为什么我的组织要求我在Windows11上更改我的PIN?可能是您的帐户与组织相关联,您的主要方法应该是验证这一点。联系域管理员会有所帮助!此外,配置错误的本地策略设置或不正确的注册表项也可能导致错误。即
 Windows 11 上调整窗口边框设置的方法:更改颜色和大小
Sep 22, 2023 am 11:37 AM
Windows 11 上调整窗口边框设置的方法:更改颜色和大小
Sep 22, 2023 am 11:37 AM
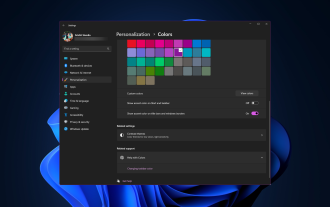
Windows11将清新优雅的设计带到了最前沿;现代界面允许您个性化和更改最精细的细节,例如窗口边框。在本指南中,我们将讨论分步说明,以帮助您在Windows操作系统中创建反映您的风格的环境。如何更改窗口边框设置?按+打开“设置”应用。WindowsI转到个性化,然后单击颜色设置。颜色更改窗口边框设置窗口11“宽度=”643“高度=”500“>找到在标题栏和窗口边框上显示强调色选项,然后切换它旁边的开关。若要在“开始”菜单和任务栏上显示主题色,请打开“在开始”菜单和任务栏上显示主题
 如何在 Windows 11 上更改标题栏颜色?
Sep 14, 2023 pm 03:33 PM
如何在 Windows 11 上更改标题栏颜色?
Sep 14, 2023 pm 03:33 PM
默认情况下,Windows11上的标题栏颜色取决于您选择的深色/浅色主题。但是,您可以将其更改为所需的任何颜色。在本指南中,我们将讨论三种方法的分步说明,以更改它并个性化您的桌面体验,使其具有视觉吸引力。是否可以更改活动和非活动窗口的标题栏颜色?是的,您可以使用“设置”应用更改活动窗口的标题栏颜色,也可以使用注册表编辑器更改非活动窗口的标题栏颜色。若要了解这些步骤,请转到下一部分。如何在Windows11中更改标题栏的颜色?1.使用“设置”应用按+打开设置窗口。WindowsI前往“个性化”,然
 OOBELANGUAGE错误Windows 11 / 10修复中出现问题的问题
Jul 16, 2023 pm 03:29 PM
OOBELANGUAGE错误Windows 11 / 10修复中出现问题的问题
Jul 16, 2023 pm 03:29 PM
您是否在Windows安装程序页面上看到“出现问题”以及“OOBELANGUAGE”语句?Windows的安装有时会因此类错误而停止。OOBE表示开箱即用的体验。正如错误提示所表示的那样,这是与OOBE语言选择相关的问题。没有什么可担心的,你可以通过OOBE屏幕本身的漂亮注册表编辑来解决这个问题。快速修复–1.单击OOBE应用底部的“重试”按钮。这将继续进行该过程,而不会再打嗝。2.使用电源按钮强制关闭系统。系统重新启动后,OOBE应继续。3.断开系统与互联网的连接。在脱机模式下完成OOBE的所
 Windows 11 上启用或禁用任务栏缩略图预览的方法
Sep 15, 2023 pm 03:57 PM
Windows 11 上启用或禁用任务栏缩略图预览的方法
Sep 15, 2023 pm 03:57 PM
任务栏缩略图可能很有趣,但它们也可能分散注意力或烦人。考虑到您将鼠标悬停在该区域的频率,您可能无意中关闭了重要窗口几次。另一个缺点是它使用更多的系统资源,因此,如果您一直在寻找一种提高资源效率的方法,我们将向您展示如何禁用它。不过,如果您的硬件规格可以处理它并且您喜欢预览版,则可以启用它。如何在Windows11中启用任务栏缩略图预览?1.使用“设置”应用点击键并单击设置。Windows单击系统,然后选择关于。点击高级系统设置。导航到“高级”选项卡,然后选择“性能”下的“设置”。在“视觉效果”选
 Windows 11 上的显示缩放比例调整指南
Sep 19, 2023 pm 06:45 PM
Windows 11 上的显示缩放比例调整指南
Sep 19, 2023 pm 06:45 PM
在Windows11上的显示缩放方面,我们都有不同的偏好。有些人喜欢大图标,有些人喜欢小图标。但是,我们都同意拥有正确的缩放比例很重要。字体缩放不良或图像过度缩放可能是工作时真正的生产力杀手,因此您需要知道如何对其进行自定义以充分利用系统功能。自定义缩放的优点:对于难以阅读屏幕上的文本的人来说,这是一个有用的功能。它可以帮助您一次在屏幕上查看更多内容。您可以创建仅适用于某些监视器和应用程序的自定义扩展配置文件。可以帮助提高低端硬件的性能。它使您可以更好地控制屏幕上的内容。如何在Windows11
 10种在 Windows 11 上调整亮度的方法
Dec 18, 2023 pm 02:21 PM
10种在 Windows 11 上调整亮度的方法
Dec 18, 2023 pm 02:21 PM
屏幕亮度是使用现代计算设备不可或缺的一部分,尤其是当您长时间注视屏幕时。它可以帮助您减轻眼睛疲劳,提高易读性,并轻松有效地查看内容。但是,根据您的设置,有时很难管理亮度,尤其是在具有新UI更改的Windows11上。如果您在调整亮度时遇到问题,以下是在Windows11上管理亮度的所有方法。如何在Windows11上更改亮度[10种方式解释]单显示器用户可以使用以下方法在Windows11上调整亮度。这包括使用单个显示器的台式机系统以及笔记本电脑。让我们开始吧。方法1:使用操作中心操作中心是访问
 如何修复Windows服务器中的激活错误代码0xc004f069
Jul 22, 2023 am 09:49 AM
如何修复Windows服务器中的激活错误代码0xc004f069
Jul 22, 2023 am 09:49 AM
Windows上的激活过程有时会突然转向显示包含此错误代码0xc004f069的错误消息。虽然激活过程已经联机,但一些运行WindowsServer的旧系统可能会遇到此问题。通过这些初步检查,如果这些检查不能帮助您激活系统,请跳转到主要解决方案以解决问题。解决方法–关闭错误消息和激活窗口。然后,重新启动计算机。再次从头开始重试Windows激活过程。修复1–从终端激活从cmd终端激活WindowsServerEdition系统。阶段–1检查Windows服务器版本您必须检查您使用的是哪种类型的W
