

Python的Urllib库的基本使用教程

1.分分钟扒一个网页下来
怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解释才呈现出来的,实质它 是一段HTML代码,加 JS、CSS,如果把网页比作一个人,那么HTML便是他的骨架,JS便是他的肌肉,CSS便是它的衣服。所以最重要的部分是存在于HTML中的,下面我 们就写个例子来扒一个网页下来。
import urllib2
response = urllib2.urlopen("http://www.baidu.com")
print response.read()
是的你没看错,真正的程序就两行,把它保存成 demo.py,进入该文件的目录,执行如下命令查看运行结果,感受一下。
python demo.py
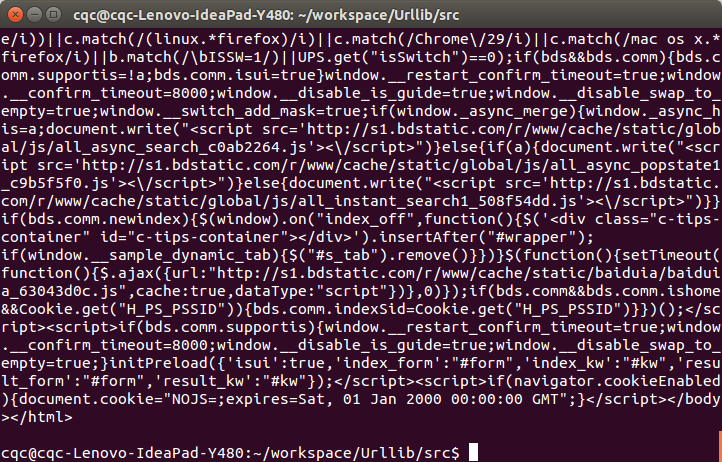
看,这个网页的源码已经被我们扒下来了,是不是很酸爽?
2.分析扒网页的方法
那么我们来分析这两行代码,第一行
response = urllib2.urlopen("http://www.baidu.com")
首先我们调用的是urllib2库里面的urlopen方法,传入一个URL,这个网址是百度首页,协议是HTTP协议,当然你也可以把HTTP换做FTP,FILE,HTTPS 等等,只是代表了一种访问控制协议,urlopen一般接受三个参数,它的参数如下:
urlopen(url, data, timeout)
第一个参数url即为URL,第二个参数data是访问URL时要传送的数据,第三个timeout是设置超时时间。
第二三个参数是可以不传送的,data默认为空None,timeout默认为 socket._GLOBAL_DEFAULT_TIMEOUT
第一个参数URL是必须要传送的,在这个例子里面我们传送了百度的URL,执行urlopen方法之后,返回一个response对象,返回信息便保存在这里面。
print response.read()
response对象有一个read方法,可以返回获取到的网页内容。
如果不加read直接打印会是什么?答案如下:
<addinfourl at 139728495260376 whose fp = <socket._fileobject object at 0x7f1513fb3ad0>>
直接打印出了该对象的描述,所以记得一定要加read方法,否则它不出来内容可就不怪我咯!
3.构造Requset
其实上面的urlopen参数可以传入一个request请求,它其实就是一个Request类的实例,构造时需要传入Url,Data等等的内容。比如上面的两行代码,我们可以这么改写
import urllib2
request = urllib2.Request("http://www.baidu.com")
response = urllib2.urlopen(request)
print response.read()
运行结果是完全一样的,只不过中间多了一个request对象,推荐大家这么写,因为在构建请求时还需要加入好多内容,通过构建一个request,服务器响应请求得到应答,这样显得逻辑上清晰明确。
4.POST和GET数据传送
上面的程序演示了最基本的网页抓取,不过,现在大多数网站都是动态网页,需要你动态地传递参数给它,它做出对应的响应。所以,在访问时,我们需要传递数据给它。最常见的情况是什么?对了,就是登录注册的时候呀。
把数据用户名和密码传送到一个URL,然后你得到服务器处理之后的响应,这个该怎么办?下面让我来为小伙伴们揭晓吧!
数据传送分为POST和GET两种方式,两种方式有什么区别呢?
最重要的区别是GET方式是直接以链接形式访问,链接中包含了所有的参数,当然如果包含了密码的话是一种不安全的选择,不过你可以直观地看到自己提交了什么内容。POST则不会在网址上显示所有的参数,不过如果你想直接查看提交了什么就不太方便了,大家可以酌情选择。
POST方式:
上面我们说了data参数是干嘛的?对了,它就是用在这里的,我们传送的数据就是这个参数data,下面演示一下POST方式。
import urllib
import urllib2
values = {"username":"1016903103@qq.com","password":"XXXX"}
data = urllib.urlencode(values)
url = "https://passport.csdn.net/account/login?from=http://my.csdn.net/my/mycsdn"
request = urllib2.Request(url,data)
response = urllib2.urlopen(request)
print response.read()
我们引入了urllib库,现在我们模拟登陆CSDN,当然上述代码可能登陆不进去,因为还要做一些设置头部header的工作,或者还有一些参数 没有设置全,还没有提及到在此就不写上去了,在此只是说明登录的原理。我们需要定义一个字典,名字为values,参数我设置了username和 password,下面利用urllib的urlencode方法将字典编码,命名为data,构建request时传入两个参数,url和data,运 行程序,即可实现登陆,返回的便是登陆后呈现的页面内容。当然你可以自己搭建一个服务器来测试一下。
注意上面字典的定义方式还有一种,下面的写法是等价的
import urllib
import urllib2
values = {}
values['username'] = "1016903103@qq.com"
values['password'] = "XXXX"
data = urllib.urlencode(values)
url = "http://passport.csdn.net/account/login?from=http://my.csdn.net/my/mycsdn"
request = urllib2.Request(url,data)
response = urllib2.urlopen(request)
print response.read()
以上方法便实现了POST方式的传送
GET方式:
至于GET方式我们可以直接把参数写到网址上面,直接构建一个带参数的URL出来即可。
import urllib
import urllib2
values={}
values['username'] = "1016903103@qq.com"
values['password']="XXXX"
data = urllib.urlencode(values)
url = "http://passport.csdn.net/account/login"
geturl = url + "?"+data
request = urllib2.Request(geturl)
response = urllib2.urlopen(request)
print response.read()
你可以print geturl,打印输出一下url,发现其实就是原来的url加?然后加编码后的参数
http://passport.csdn.net/account/login?username=1016903103%40qq.com&password=XXXX
和我们平常GET访问方式一模一样,这样就实现了数据的GET方式传送。
本节讲解了一些基本使用,可以抓取到一些基本的网页信息,小伙伴们加油!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 PHP和Python:比较两种流行的编程语言
Apr 14, 2025 am 12:13 AM
PHP和Python:比较两种流行的编程语言
Apr 14, 2025 am 12:13 AM
PHP和Python各有优势,选择依据项目需求。1.PHP适合web开发,尤其快速开发和维护网站。2.Python适用于数据科学、机器学习和人工智能,语法简洁,适合初学者。
 debian readdir如何与其他工具集成
Apr 13, 2025 am 09:42 AM
debian readdir如何与其他工具集成
Apr 13, 2025 am 09:42 AM
Debian系统中的readdir函数是用于读取目录内容的系统调用,常用于C语言编程。本文将介绍如何将readdir与其他工具集成,以增强其功能。方法一:C语言程序与管道结合首先,编写一个C程序调用readdir函数并输出结果:#include#include#includeintmain(intargc,char*argv[]){DIR*dir;structdirent*entry;if(argc!=2){
 Python和时间:充分利用您的学习时间
Apr 14, 2025 am 12:02 AM
Python和时间:充分利用您的学习时间
Apr 14, 2025 am 12:02 AM
要在有限的时间内最大化学习Python的效率,可以使用Python的datetime、time和schedule模块。1.datetime模块用于记录和规划学习时间。2.time模块帮助设置学习和休息时间。3.schedule模块自动化安排每周学习任务。
 Debian OpenSSL如何配置HTTPS服务器
Apr 13, 2025 am 11:03 AM
Debian OpenSSL如何配置HTTPS服务器
Apr 13, 2025 am 11:03 AM
在Debian系统上配置HTTPS服务器涉及几个步骤,包括安装必要的软件、生成SSL证书、配置Web服务器(如Apache或Nginx)以使用SSL证书。以下是一个基本的指南,假设你使用的是ApacheWeb服务器。1.安装必要的软件首先,确保你的系统是最新的,并安装Apache和OpenSSL:sudoaptupdatesudoaptupgradesudoaptinsta
 Nginx SSL证书更新Debian教程
Apr 13, 2025 am 07:21 AM
Nginx SSL证书更新Debian教程
Apr 13, 2025 am 07:21 AM
本文将指导您如何在Debian系统上更新NginxSSL证书。第一步:安装Certbot首先,请确保您的系统已安装certbot和python3-certbot-nginx包。若未安装,请执行以下命令:sudoapt-getupdatesudoapt-getinstallcertbotpython3-certbot-nginx第二步:获取并配置证书使用certbot命令获取Let'sEncrypt证书并配置Nginx:sudocertbot--nginx按照提示选
 Debian上GitLab的插件开发指南
Apr 13, 2025 am 08:24 AM
Debian上GitLab的插件开发指南
Apr 13, 2025 am 08:24 AM
在Debian上开发GitLab插件需要一些特定的步骤和知识。以下是一个基本的指南,帮助你开始这个过程。安装GitLab首先,你需要在Debian系统上安装GitLab。可以参考GitLab的官方安装手册。获取API访问令牌在进行API集成之前,首先需要获取GitLab的API访问令牌。打开GitLab仪表盘,在用户设置中找到“AccessTokens”选项,生成一个新的访问令牌。将生成的
 apache属于什么服务
Apr 13, 2025 pm 12:06 PM
apache属于什么服务
Apr 13, 2025 pm 12:06 PM
Apache是互联网幕后的英雄,不仅是Web服务器,更是一个支持巨大流量、提供动态内容的强大平台。它通过模块化设计提供极高的灵活性,可根据需要扩展各种功能。然而,模块化也带来配置和性能方面的挑战,需要谨慎管理。Apache适合需要高度可定制、满足复杂需求的服务器场景。

