

使用Python3中的gettext模块翻译Python源码以支持多语言

你写了一个Python 3程序,还想要它适用于其他语言。你能复制全部代码库,然后刻意地检查每个.py文件,替换掉所有找到的文本字符串。但这意味着你有两份你代码的独立副本,每当你要做出个改动或修复个bug,你的工作量会加倍。而且如果你想要程序还适用于其他语言,就更糟了。
幸运的是,Python给了一个解决办法,就是用gettext模块。
一个Hack解法
你应该把你自己的解决办法统一改变。例如,你可以把你程序中的每个字符串替换为一个函数调用(函数名简单些,比如像_()一样),这会返回被翻译为该正确语言的字符串。举个例子,如果你的程序原本是:
print('Hello world!')
……你可以将它改为:
print(_('Hello world!'))
……函数_()会返回'Hello world!'的翻译,它基于程序设置有的语言。比如,如果这个语言设置之前被存在一个叫LANGUAGE的全局变量中,函数_()看起来像这样:
def _(s):
spanishStrings = {'Hello world!': 'Hola Mundo!'}
frenchStrings = {'Hello world!': 'Bonjour le monde!'}
germanStrings = {'Hello world!': 'Hallo Welt!'}
if LANGUAGE == 'English':
return s
if LANGUAGE == 'Spanish':
return spanishStrings[s]
if LANGUAGE == 'French':
return frenchStrings[s]
if LANGUAGE == 'German':
return germanStrings[s]
这可以,但是你这是在重复造轮子。Python的gettext模块可以做更多。gettext是一系列工具,文件格式在20世纪90年代被发明出来,来规范软件国际化(也叫I18N)。gettext是个作为对于所有编程语言的系统化的设计,但是我们会在本篇文章中只专注于Python。
程序例子
设想你有个想要翻译的用Python3写的简单“猜数字”游戏。程序的源代码在这里。有四步来使这个程序国际化:
调整这个.py文件的源代码,这样使字符串输入进一个名为_()的函数。
用和Python一起安装的pygettext.py文本,从源代码创建一个”pot”文件。
用这个免费的跨平台Poedit软件,从pot文件创建.po和.mo文件。
再次调整你的.py文件源代码导入gettext模块的代码,设置语言。
第一步:添加 _() 函数
首先,检查你程序中的所有需要被翻译和用_()的调用来替代的字符串。针对Python使用的gettext系统用_()作为得到翻译了的字符串的通用名,因为它是个短名。
注意:用格式型字符串而不是连接型字符串会是你的程序翻译起来更简单。例如,用连接型字符串你的程序会像这样:
print('Good job, ' + myName + '! You guessed my number in ' + guessesTaken + ' guesses!')
print(_('Good job, ') + myName + _('! You guessed my number in ') + guessesTaken + _(' guesses!'))
This results in three separate strings that need to be translated, as opposed to the single string needed in the string formatting approach:
这会导致三个独立的字符串都需要翻译,然而相反的是在格式型的字符串中,只需翻译一个字符串:
print('Good job, %s! You guessed my number in %s guesses!' % (myName, guessesTaken))
print(_('Good job, %s! You guessed my number in %s guesses!') % (myName, guessesTaken))
当你改完“猜数字”源代码后,它会像这样。你并不能运行它,因为_()函数还没定义。这个变化只是让pygettext.py文本可以找到所有需要翻译的字符串。
第二步:用pygettext.py提取字符串
在你Python安装(Windows上的C:Python34Toolsi18n)中的Tools/i18n就是pygettext.py文本。对于可译字符串普通 gettext unix 命令解析 C/C++ 源码并且 xgettext unix 命令可以解析其他语言,而pygettext.py则知道怎样去解析Python源码。它会找到所有字符串并产生个”pot”文件。
在Windows上我已经运行了这个文本像这样:
C:>py -3.4 C:Python34Toolsi18npygettext.py -d guess guess.py
这创建了一个pot文件,叫guess.pot。这只是个普通纯文本文件,它列出来了全部的在源码中寻找_()的调用的要翻译的字符串。你可以在这儿看guess.pot文件.
第三步:用Poedit翻译字符串
你可以用文本编辑器填写翻译但是免费的Poedit软件会更容易从这儿下载http://poedit.net. 选择 > New from POT/PO file… 然后选择你的guess.po文件。
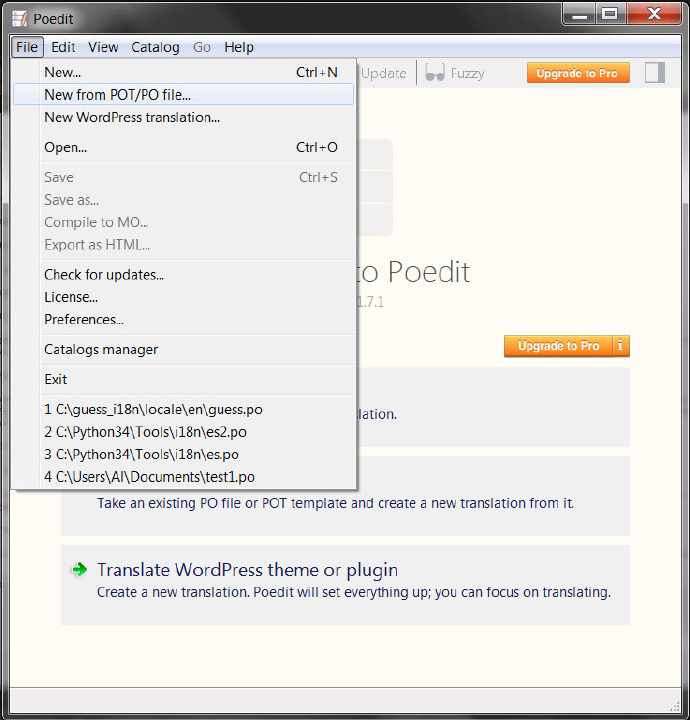
Poedit会问你想要翻译成什么语言。我们举例用西班牙语:
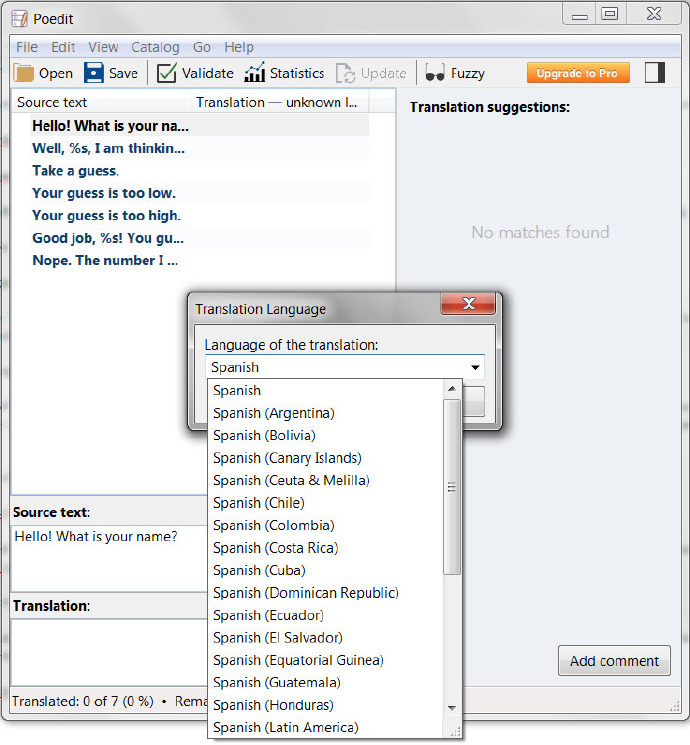
填写翻译吧。(我用 http://translate.google.com,所以对于真的使用西班牙语的人会感觉有点奇怪。)
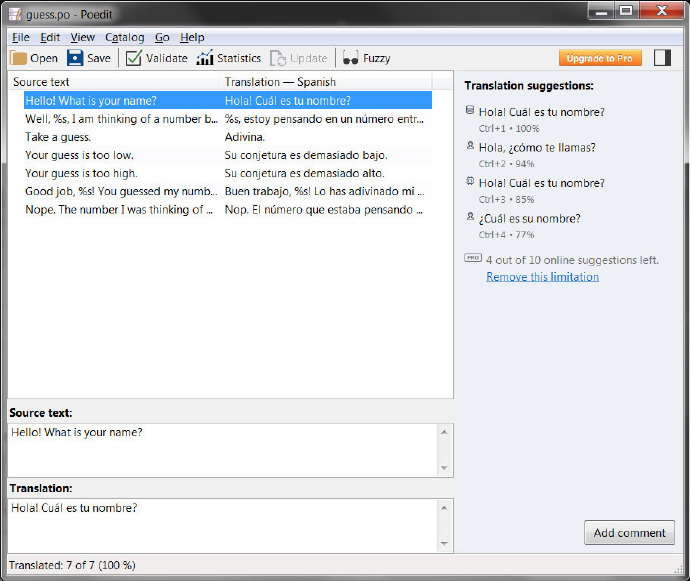
现在储存文件在它的gettext形式的文件夹里。保存会创建.po文件(一个人类可读的文本文件不同于原始.pot文件,除了是有西语翻译的)和一个.mo文件(一个gettext会读取的机器可读版本。这些文件会存在一个特定的文件夹内,为的是让gettext能够找到他们。他们看起来像这样(比如西语文件中的”es”和德语文件中”de”):
./guess.py ./guess.pot ./locale/es/LC_MESSAGES/guess.mo ./locale/es/LC_MESSAGES/guess.po ./locale/de/LC_MESSAGES/guess.mo ./locale/de/LC_MESSAGES/guess.po
这些两种性质的语言像西语中的”es”和德语中的 ”de” 被称作ISO 639-1 codes 是语言的标准缩写。你不一定要用他们,但是遵循标准是有道理的。
第四步:给你程序加上gettext代码
现在你有包含翻译的.mo文件,调整你的Python代码去用它。在你的程序中加上下面的:
import gettext
es = gettext.translation('guess', localedir='locale', languages=['es'])
es.install()
第一个 'guess' 是”定义域”,这其实是意味着guess.mo文件名中“猜”的部分。 localedir是你创建的locale文件夹的目录地址。这会是相对或绝对的路径。'es'描述在locale文件夹下面的文件。LC_MESSAGES文件夹是个标准名
install()方法会导致调用_()返回翻译为西语的字符串。如果你想回到原始的英语只需要分配一个lambda函数值给_,这会返回当时输入的字符串:
import gettext
es = gettext.translation('guess', localedir='locale', languages=['es'])
print(_('Hello! What is your name?')) # prints Spanish
_ = lambda s: s
你可以检查准备翻译的”Guess the Number”源码。如果你想要运行此程序,下载并解压这个压缩文件和它的locale文件夹和.mo安装文件。
延伸阅读
我怎样都称不上是 I18N or gettext的专家,如果我的教程讲解不够好,请一定要留言。大多数情况下,你的软件运行时不会转换语言,而是会去读LANGUAGE,LC_ALL,LC_MESSAGES,和LANG这些环境变量中的一个来确定计算机的工作地点。我会边学习边更新本教程的。

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 2小时的Python计划:一种现实的方法
Apr 11, 2025 am 12:04 AM
2小时的Python计划:一种现实的方法
Apr 11, 2025 am 12:04 AM
2小时内可以学会Python的基本编程概念和技能。1.学习变量和数据类型,2.掌握控制流(条件语句和循环),3.理解函数的定义和使用,4.通过简单示例和代码片段快速上手Python编程。
 Python:探索其主要应用程序
Apr 10, 2025 am 09:41 AM
Python:探索其主要应用程序
Apr 10, 2025 am 09:41 AM
Python在web开发、数据科学、机器学习、自动化和脚本编写等领域有广泛应用。1)在web开发中,Django和Flask框架简化了开发过程。2)数据科学和机器学习领域,NumPy、Pandas、Scikit-learn和TensorFlow库提供了强大支持。3)自动化和脚本编写方面,Python适用于自动化测试和系统管理等任务。
 Navicat查看MongoDB数据库密码的方法
Apr 08, 2025 pm 09:39 PM
Navicat查看MongoDB数据库密码的方法
Apr 08, 2025 pm 09:39 PM
直接通过 Navicat 查看 MongoDB 密码是不可能的,因为它以哈希值形式存储。取回丢失密码的方法:1. 重置密码;2. 检查配置文件(可能包含哈希值);3. 检查代码(可能硬编码密码)。
 如何将 AWS Glue 爬网程序与 Amazon Athena 结合使用
Apr 09, 2025 pm 03:09 PM
如何将 AWS Glue 爬网程序与 Amazon Athena 结合使用
Apr 09, 2025 pm 03:09 PM
作为数据专业人员,您需要处理来自各种来源的大量数据。这可能会给数据管理和分析带来挑战。幸运的是,两项 AWS 服务可以提供帮助:AWS Glue 和 Amazon Athena。
 redis怎么读取队列
Apr 10, 2025 pm 10:12 PM
redis怎么读取队列
Apr 10, 2025 pm 10:12 PM
要从 Redis 读取队列,需要获取队列名称、使用 LPOP 命令读取元素,并处理空队列。具体步骤如下:获取队列名称:以 "queue:" 前缀命名,如 "queue:my-queue"。使用 LPOP 命令:从队列头部弹出元素并返回其值,如 LPOP queue:my-queue。处理空队列:如果队列为空,LPOP 返回 nil,可先检查队列是否存在再读取元素。
 redis怎么启动服务器
Apr 10, 2025 pm 08:12 PM
redis怎么启动服务器
Apr 10, 2025 pm 08:12 PM
启动 Redis 服务器的步骤包括:根据操作系统安装 Redis。通过 redis-server(Linux/macOS)或 redis-server.exe(Windows)启动 Redis 服务。使用 redis-cli ping(Linux/macOS)或 redis-cli.exe ping(Windows)命令检查服务状态。使用 Redis 客户端,如 redis-cli、Python 或 Node.js,访问服务器。
 Redis如何查看服务器版本
Apr 10, 2025 pm 01:27 PM
Redis如何查看服务器版本
Apr 10, 2025 pm 01:27 PM
问题:如何查看 Redis 服务器版本?使用命令行工具 redis-cli --version 查看已连接服务器的版本。使用 INFO server 命令查看服务器内部版本,需解析返回信息。在集群环境下,检查每个节点的版本一致性,可使用脚本自动化检查。使用脚本自动化查看版本,例如用 Python 脚本连接并打印版本信息。
 Navicat的密码安全性如何?
Apr 08, 2025 pm 09:24 PM
Navicat的密码安全性如何?
Apr 08, 2025 pm 09:24 PM
Navicat的密码安全性依赖于对称加密、密码强度和安全措施的结合。具体措施包括:采用SSL连接(前提是数据库服务器支持并正确配置证书)、定期更新Navicat、使用更安全的方式(如SSH隧道)、限制访问权限,最重要的是,绝不记录密码。
