

单次支持38万字输入!腾讯混元推出256k长文模型,通过腾讯云向企业和个人开发者开放

AI大模型技术正成为推动高质生产力发展的关键力量,在与千行百业的融合中发挥着重要作用。腾讯混元大模型通过采用混合专家模型 (MoE) 结构,已将模型扩展至万亿级参数规模,增加“脑”容量提升预测性能的同时,推动了推理成本下降。作为通用模型,腾讯混元在中文表现上处于业界领先水平,尤其在文本生成、数理逻辑和多轮对话中性能表现卓越。
近日,腾讯混元大模型正式对外发布256k长文模型,并通过腾讯云向广大企业和个人开发者开放,以支持更广泛的创新和应用。腾讯混元256k模型版本具备处理超过38万字符的超长文本能力。在对话应用场景中,该模型能够“记忆”更多的对话内容,有效避免“忘记”信息等问题。此外,它还具备出色的上下文分析能力,能够为对话参与者提供更为精确和相关的反馈,从而辅助他们做出更明智的决策。
此外,该模型版本在长文档的阅读理解和大规模数据分析方面也展现出强大性能。它能够为金融、医疗、教育、出行等行业的专业人士提供强有力的工作支持,显著提高他们的工作效率。模型在推理性能上也进行了深入优化,确保了在腾讯云等平台上的实际应用中,用户能够享受到更加流畅和高效的使用体验。
减少“健忘”,让大模型更聪明
在大模型产品中,处理对话式需求是一项核心功能。但由于长文本处理能力的局限,传统大模型在对话中容易“迷失方向”或出现“记忆缺失”,随着对话长度的增加,遗忘的信息量也随之增多。
腾讯混元256k模型针对这一挑战进行了专门优化。它采用了先进的“专家混合”(MoE)架构,并融合了RoPE-NTK和Flash Attention V2等创新技术,既保持了对通用短文本(少于4,000字符)的高效处理能力,同时在长文本处理的深度和广度上实现了突破。
目前,腾讯混元大模型已经具备256k的超长上下文理解能力,单次处理字符数超过38万个,在经过严苛的“大海捞针”任务测试后,该模型在长文本处理上的准确率已达到99.99%,在国际上也处于领先地位。
持续稳定迭代,大模型应用效率提升
腾讯混元大模型在业界率先采用了混合专家模型(MoE)结构,并在此过程中积累了大量自研技术。在上一个版本32K中,该模型已显著超越市面上的开源同类模型,并在多种应用场景中展现出优异性能。
经过全新迭代,腾讯混元256k在通用领域的GSB评测中,相较于前一版本,胜出率50.72%。同时,腾讯混元256k的训练集融合了医疗、金融等多个领域的长文本数据、翻译数据和多文档问答等高质量标注数据,这使得模型在实际应用中,尤其是在需要频繁分析和处理大量长文本资料的医疗和金融行业,能够提供更为精准和高效的工作支持。
例如,当将一份央行发布的金融报告输入腾讯混元256k模型时,该模型能够迅速提炼和总结报告的要点,在处理速度和准确性上均达到了令人满意的水平。

推理性能优化,带来更强的大模型理解能力
与此同时,腾讯混元256k在推理性能上进行了深入优化。在INT8精度模式下,与FP16精度相比,模型的QPM(每秒查询率)实现了23.9%的显着提升,而首字耗时仅增加了5.7%。这些改进显着增强了模型在实际应用中的响应速度和整体效率。
以《三国演义》的分析为例,腾讯混元256k能够迅速阅读并检索这部数十万字的古典小说,不仅能够准确识别出小说中的关键人物和事件情节,甚至对于天气、角色着装等细节描述也能提供精确的信息。

AI大模型作为新质生产力的关键组成部分,对推动产业升级和实现高质量发展具有至关重要的作用。腾讯混元256k模型的推出为整个行业注入了全新活力,并开拓了更广泛的应用前景。
目前,腾讯混元256k长文模型已经通过腾讯云向广大企业和个人开发者开放,用户可通过hunyuan-standard版本256k长文模型接入。这使得更多的开发者和用户能够便捷地接入并使用腾讯混元大模型的强大功能,进而为各行各业提供智能化的解决方案,推动更多创新应用场景的实现。
以上是单次支持38万字输入!腾讯混元推出256k长文模型,通过腾讯云向企业和个人开发者开放的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 腾讯混元大模型全面降价!混元-lite即日起免费
Jun 02, 2024 pm 08:07 PM
腾讯混元大模型全面降价!混元-lite即日起免费
Jun 02, 2024 pm 08:07 PM
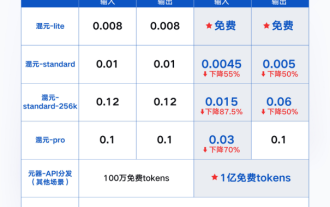
5月22日,腾讯云公布全新大模型升级方案。主力模型之一混元-lite模型,API输入输出总长度计划从目前的4k升级到256k,价格从0.008元/千tokens调整为全面免费。混元-standardAPI输入价格从0.01元/千tokens降至0.0045元/千tokens,下降55%,API输出价格从0.01元/千tokens降至0.005元/千tokens,下降50%。新上线的混元-standard-256k,具备处理超过38万字符的超长文本能力,API输入价格下调至0.015元/千toke
 来自科技进步一等奖的肯定:腾讯破解万亿参数大模型训练难题
Mar 27, 2024 pm 09:41 PM
来自科技进步一等奖的肯定:腾讯破解万亿参数大模型训练难题
Mar 27, 2024 pm 09:41 PM
中国电子学会2023科学技术奖授奖名单公布,这次,我们发现了一个熟悉的身影——腾讯Angel机器学习平台。在大模型飞速发展的当下,科学技术奖授予机器学习平台类研究和应用项目,对于模型训练平台的价值和重要性给予了充分的肯定。科学技术奖认可了机器学习平台类项目的研究和应用,特别在大型模型快速发展的背景下,对模型训练平台的价值和重要性给予了充分的认可。随着深度学习的兴起,各大公司开始认识到机器学习平台在发展人工智能技术中的重要性。谷歌、微软、英伟达等公司都推出了自己的机器学习平台,以加速
 利用vscode远程调试Linux内核
Feb 05, 2024 pm 12:30 PM
利用vscode远程调试Linux内核
Feb 05, 2024 pm 12:30 PM
前言上一遍文章介绍了利用QEMU+GDB调试Linux内核。但是,有时候直接利用GDB调试查看代码还不是很方便,所以,在这么重要的场合,怎么能少的了vscode这个神器呢。本篇文章介绍如何使用vscode远程调试内核。本文环境:windows10vscodeubuntu20.04我个人使用的是腾讯云服务器,所以就省去了安装虚拟机的过程。直接从vscode配置开始。vscode插件安装remote-ssh在插件库中找到Remote-SSH插件并且安装。安装完成后右边工具栏会多出一个功能按F1呼出对
 GPT Store都开不下去,这家国产平台怎么敢走这条路的??
Apr 19, 2024 pm 09:30 PM
GPT Store都开不下去,这家国产平台怎么敢走这条路的??
Apr 19, 2024 pm 09:30 PM
注意看,这个男人把超1000种大模型接入,让你可插拔无缝切换使用。最近还上线了可视化的AI工作流:给你一个直观的拖放界面,拖拖、拉拉、拽拽,就能在无限画布上编排自己个儿的Workflow。正所谓兵贵神速,量子位听说,这个AIWorkflow上线不到48小时,就已经有用户配出了100多个节点的个人工作流。不卖关子,今天要聊的就是LLMOps公司Dify,及其CEO张路宇。张路宇也是Dify的创始人。投身创业前,有11年的互联网从业经验。搞产品设计,懂项目管理,也对SaaS有点自己的独到见解。后来他
 家用路由器要不要开启ipv6「必看:家用路由器开启 IPV6优势」
Feb 07, 2024 am 09:03 AM
家用路由器要不要开启ipv6「必看:家用路由器开启 IPV6优势」
Feb 07, 2024 am 09:03 AM
IPv4枯竭了,IPv6被刚需,可这次升级难道就仅仅是因为被动改变吗?对于普通大众而言,IPv6究竟有何意义?全面升级IPv6的改变,能为我们网络带来多大的改变呢?01大规模的IPv6改造即将实现最近,工信部办公厅和国家广播电视总局办公厅发布了一份通知,提出了推动互联网电视业务IPv6改造的要求。中国移动、阿里云、腾讯云、百度云、京东云、华为云和网宿科技需要对互联网电视业务相关的内容分发网络(CDN)进行IPv6改造。到2020年底,基于IPv6协议的互联网电视业务服务能力将达到IPv4的85%
 腾讯混元升级模型矩阵,云上推出256k长文模型
Jun 01, 2024 pm 01:46 PM
腾讯混元升级模型矩阵,云上推出256k长文模型
Jun 01, 2024 pm 01:46 PM
大模型落地加速,“产业实用”成为发展共识。2024年5月17日,腾讯云生成式AI产业应用峰会在北京召开,公布大模型研发、应用产品的系列进展。腾讯混元大模型能力持续升级,多个版本模型hunyuan-pro、hunyuan-standard、hunyuan-lite通过腾讯云对外开放,满足企业客户、开发者在不同场景下的模型需求,落地最优性价比模型方案。腾讯云大模型知识引擎、图像创作引擎、视频创作引擎三大工具发布,打造大模型时代原生工具链,通过PaaS服务简化数据接入、模型精调、应用开发流程,助力企业
 微信链接如何制作?微信链接制作方法分享
Mar 09, 2024 pm 09:37 PM
微信链接如何制作?微信链接制作方法分享
Mar 09, 2024 pm 09:37 PM
微信,作为一款广受欢迎的社交软件,不仅为人们提供了即时通讯的便利,还融合了多种功能,丰富了用户的社交体验。其中,微信链接的制作与分享是微信功能的重要一环。微信链接的制作主要依赖于微信公众平台及其相关功能,以及第三方工具。以下是几种常见的制作微信链接的方法。微信链接如何制作?微信链接制作方法分享第一种方法,使用微信公众平台的图文编辑器。1、登录微信公众平台,进入图文编辑界面。2、在编辑器中添加文本或图片,然后利用链接按钮添加需要的链接。这种方式适合简单的文本或图片链接。第二种方法,使用HTML代d
 wordpress需要备案吗
Apr 16, 2024 pm 12:07 PM
wordpress需要备案吗
Apr 16, 2024 pm 12:07 PM
WordPress需要备案。根据我国《互联网安全管理办法》,在境内提供互联网信息服务的网站需向所在地省级互联网信息办公室备案,包括WordPress在内。备案流程包括选择服务商、准备信息、提交申请、审核公示、获取备案号等步骤。备案好处有合法合规、提升可信度、满足接入要求、确保正常访问等。备案信息需真实有效,备案后需定期更新。
