

YOLOv10来啦!真正实时端到端目标检测

过去几年里,YOLOs因在计算成本和检测性能之间实现有效平衡而成为实时目标检测领域的主流范式。研究人员针对YOLOs的结构设计、优化目标、数据增强策略等进行了深入探索,并取得了显着进展。然而,对非极大值抑制(NMS)的后处理依赖阻碍了YOLOs的端到端部署,并对推理延迟产生负面影响。此外,YOLOs中各种组件的设计缺乏全面和彻底的审查,导致明显的计算冗余并限制了模型的性能。这导致次优的效率,以及性能提升的巨大潜力。在这项工作中,我们旨在从后处理和模型架构两个方面进一步推进YOLOs的性能-效率边界。为此,我们首先提出了用于YOLOs无NMS训练的持续双重分配,该方法同时带来了竞争性的性能和较低的推理延迟。此外,我们为YOLOs引入了全面的效率-准确性驱动模型设计策略。我们从效率和准确性两个角度全面优化了YOLOs的各个组件,这大大降低了计算开销并增强了模型能力。我们的努力成果是新一代YOLO系列,专为实时端到端目标检测而设计,名为YOLOv10。广泛的实验表明,YOLOv10在各种模型规模下均达到了最先进的性能和效率。例如,在COCO数据集上,我们的YOLOv10-S在相似AP下比RT-DETR-R18快1.8倍,同时参数和浮点运算量(FLOPs)减少了2.8倍。与YOLOv9-C相比,YOLOv10-B在相同性能下延迟减少了46%,参数减少了25%。代码链接:https://github.com/THU-MIG/yolov10。
YOLOv10有哪些改进?
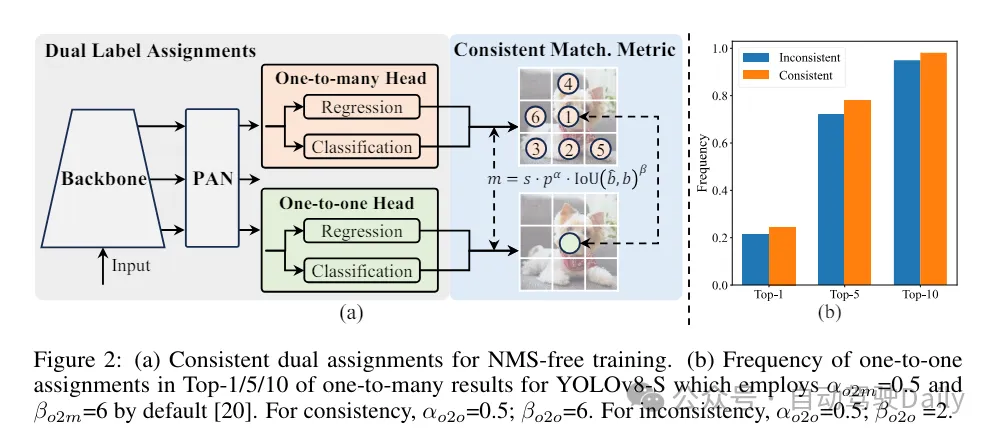
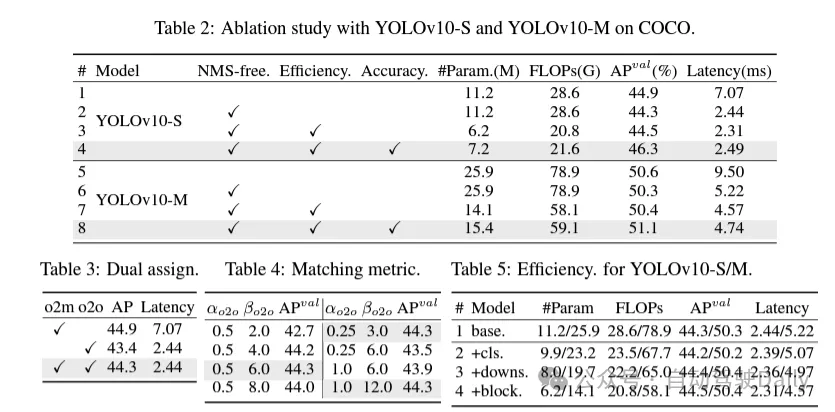
首先通过为无NMS的YOLOs提出一种持续双重分配策略来解决后处理中的冗余预测问题。该策略包括括双重标签分配和一致匹配度量。这使得模型在训练过程中能够够获得丰富而和谐的监督,同时消除了推理过程中对NMS的需求,从而在保持高效率的同时获得了竞争性的性能。
此次,为模型架构提出了全面的效率-准确度驱动模型设计策略,对YOLOs中的各个组件进行了全面检查。在效率方面,提出了轻量级分类头、空间-通道解耦下采样和rank引导block设计,以减少明显的计算冗余并实现更高效的架构。
在准确度方面,探索了大核卷积并提出了有效的部分自注意力模块,以增强模型能力,以低成本挖掘性能提升潜力。
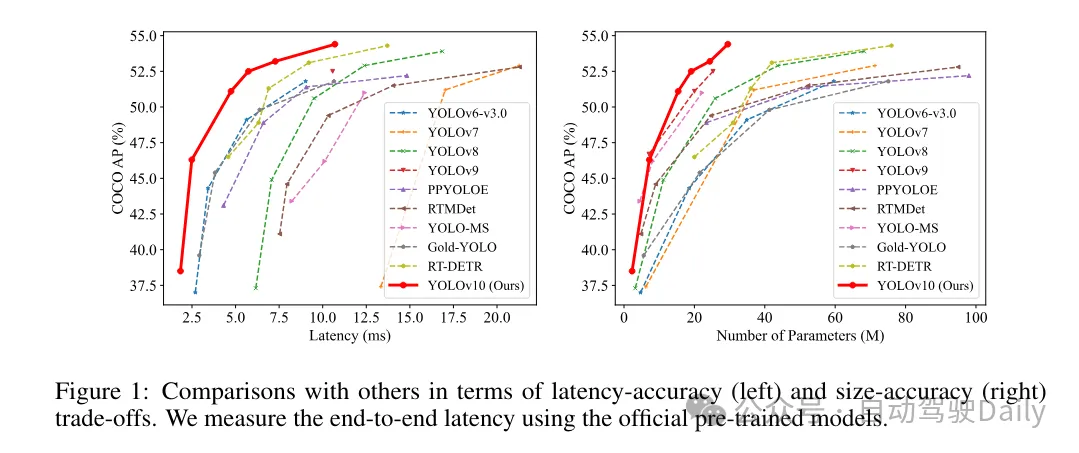
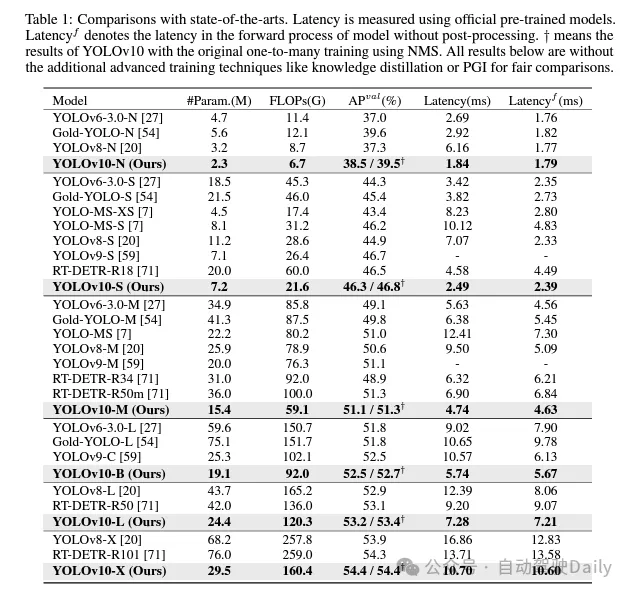
基于这些方法,作者成功地实现了一系列不同模型规模的实时端到端检测器,即YOLOv10-N / S / M / B / L / X。在标准目标检测基准上进行的广泛实验表明,YOLOv10在各种模型规模下,在计算-准确度权衡方面显示出了优于先前的最先进模型的能力。如图1所示,在类似性能下,YOLOv10-S / X分别比RT-DETR R18 / R101快1.8倍/1.3倍。与YOLOv9-C相比,YOLOv10-B在相同性能下实现了46%的延迟降低。此外,YOLOv10展现出了极高的参数利用效率。 YOLOv10-L / X在参 数数量分别减少了1.8倍和2.3倍的情况下,比YOLOv8-L / X高出0.3 AP和0.5 AP。 YOLOv10-M在参数数量分别减少了23%和31%的情况下,与YOLOv9-M / YOLO-MS实现了相似的AP。
在训练过程中,YOLOs通常利用TAL(任务分配学习)为每个实例分配多个样本。采用一对多的分配方式产生了丰富的监督信号,有助于优化并实现更强的性能。然而,这也使得YOLOs必须依赖NMS(非极大值抑制)后处理,这导致在部署时的推理效率不是最优的。虽然之前的工作探索了一对一的匹配方式来抑制冗余预测,但它们通常会增加额外的推理开销或导致次优的性能。 在这项工作中,我们提出了一种无需NMS的训练策略,该策略采用双重标签分配和一致匹配度量,实现了高效率和具有竞争力的性能。通过该策略,我们的YOLOs在训练中不再需要NMS,从而实现了高效率和具有竞争力的性能。
效率驱动的模型设计。 YOLO中的组件包括主干(stem)、下采样层、带有基本构建块的阶段和头部。主干部分的计算成本很低,因此我们对其他三个部分进行效率驱动的模型设计。
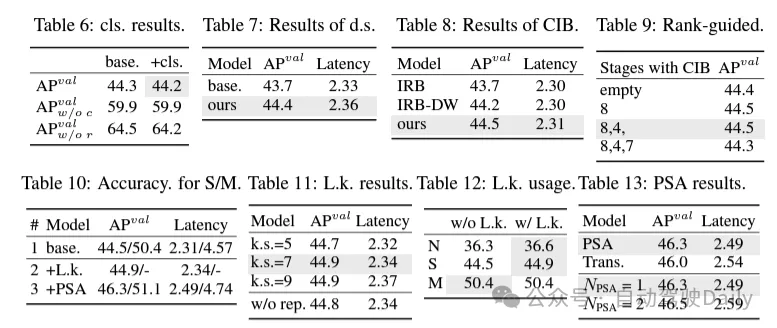
(1) Lightweight classification header. In YOLO, the classification head and regression head usually have the same architecture. However, they have significant differences in computational overhead. For example, in YOLOv8-S, the number of FLOPs and parameters of the classification head (5.95G/1.51M) and regression head (2.34G/0.64M) are 2.5 times and 2.4 times that of the regression head respectively. However, by analyzing the impact of classification errors and regression errors (see Table 6), we found that the regression head is more important to the performance of YOLO. Therefore, we can reduce the overhead of classification headers without worrying about performance harm. Therefore, we simply adopt a lightweight classification head architecture, which consists of two depthwise separable convolutions with a kernel size of 3 × 3, followed by a 1 × 1 kernel. Through the above improvements, we can simplify the architecture of a lightweight classification head, which consists of two depth-separable convolutions with a convolution kernel size of 3×3, followed by a 1×1 convolution kernel. This simplified architecture can achieve classification functions with smaller computational overhead and number of parameters.
(2) Space-channel decoupled downsampling. YOLO usually uses a regular 3×3 standard convolution with a stride of 2, while implementing spatial downsampling (from H × W to H/2 × W/2) and channel transformation (from C to 2C). This introduces a non-negligible computational cost and parameter count. Instead, we propose to decouple the space reduction and channel increase operations to achieve more efficient downsampling. Specifically, pointwise convolution is first utilized to modulate the channel dimensions, and then depthwise convolution is utilized for spatial downsampling. This reduces the computational cost to and parameter count to . At the same time, it maximizes information retention during downsampling, thereby reducing latency while maintaining competitive performance.
(3) Module design based on rank guidance. YOLOs typically use the same basic building blocks for all stages, such as the bottleneck block in YOLOv8. To thoroughly examine this isomorphic design of YOLOs, we utilize intrinsic rank to analyze the redundancy of each stage. Specifically, the numerical rank of the last convolution in the last basic block in each stage is calculated, which counts the number of singular values larger than a threshold. Figure 3(a) shows the results of YOLOv8, showing that deep stages and large models are more likely to exhibit more redundancy. This observation suggests that simply applying the same block design to all stages is suboptimal for achieving the best capacity-efficiency trade-off. To solve this problem, a rank-based module design scheme is proposed, which aims to reduce the complexity of stages that prove to be redundant through compact architectural design.
We first introduce a compact inverted block (CIB) structure, which uses cheap depthwise convolution for spatial mixing and cost-effective pointwise convolution for channel mixing, as shown in Figure 3(b) Show. It can serve as an effective basic building block, for example embedded in ELAN structures (Figure 3(b)). Then, a rank-based module allocation strategy is advocated to achieve optimal efficiency while maintaining competitive power. Specifically, given a model, order all stages according to the ascending order of their intrinsic rank. Further examine the performance changes after replacing the basic blocks of the leading stage with CIB. If there is no performance degradation compared to the given model, we proceed to the next stage with replacement, otherwise we stop the process. As a result, we can implement adaptive compact block designs at different stages and model sizes, achieving greater efficiency without compromising performance.
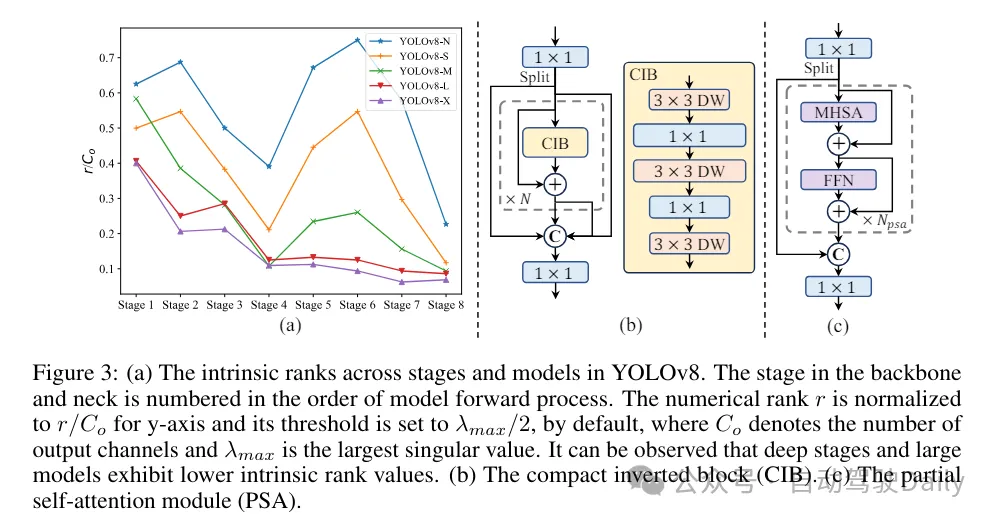
#Based on precision-oriented model design. The paper further explores large-core convolution and self-attention mechanisms to achieve precision-based design, aiming to improve performance at minimal cost.
(1) Large kernel convolution. Adopting large-kernel deep convolutions is an effective way to expand the receptive field and enhance the model's capabilities. However, simply exploiting them in all stages may introduce contamination in the shallow features used to detect small objects, while also introducing significant I/O overhead and latency in the high-resolution stage. Therefore, the authors propose to utilize large-kernel deep convolutions in the inter-stage information block (CIB) of the deep stage. Here the kernel size of the second 3×3 depthwise convolution in CIB is increased to 7×7. In addition, structural reparameterization technology is adopted to introduce another 3×3 depth convolution branch to alleviate the optimization problem without increasing inference overhead. Furthermore, as the model size increases, its receptive field naturally expands, and the benefits of using large kernel convolutions gradually diminish. Therefore, large-kernel convolutions are only employed at small model scales.
(2) Partial self-attention (PSA). The self-attention mechanism is widely used in various visual tasks due to its excellent global modeling capabilities. However, it exhibits high computational complexity and memory footprint. In order to solve this problem, in view of the ubiquitous attention head redundancy, the author proposes an efficient partial self-attention (PSA) module design, as shown in Figure 3.(c). Specifically, the features are evenly divided into two parts by channels after 1×1 convolution. Only a part of the features are input into the NPSA block consisting of multi-head self-attention module (MHSA) and feed-forward network (FFN). Then, the two parts of features are spliced and fused through 1×1 convolution. Additionally, set the dimensions of queries and keys in MHSA to half of the values, and replace LayerNorm with BatchNorm for fast inference. PSA is only placed after stage 4 with the lowest resolution to avoid excessive overhead caused by the quadratic computational complexity of self-attention. In this way, global representation learning capabilities can be incorporated into YOLOs at low computational cost, thus well enhancing the model's capabilities and improving performance.
Experimental Comparison
I won’t introduce too much here, just the results! ! ! Latency is reduced and performance continues to increase.
以上是YOLOv10来啦!真正实时端到端目标检测的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 端到端是什么意思
Sep 27, 2021 pm 12:10 PM
端到端是什么意思
Sep 27, 2021 pm 12:10 PM
端到端是指“网络连接”。网络要通信,必须建立连接,不管有多远,中间有多少机器,都必须在两头间建立连接,一旦连接建立起来,就说已经是端到端连接了,即端到端是逻辑链路。
 用于精确目标检测的多网格冗余边界框标注
Jun 01, 2024 pm 09:46 PM
用于精确目标检测的多网格冗余边界框标注
Jun 01, 2024 pm 09:46 PM
一、前言目前领先的目标检测器是基于深度CNN的主干分类器网络重新调整用途的两级或单级网络。YOLOv3就是这样一种众所周知的最先进的单级检测器,它接收输入图像并将其划分为大小相等的网格矩阵。具有目标中心的网格单元负责检测特定目标。今天分享的,就是提出了一种新的数学方法,该方法为每个目标分配多个网格,以实现精确的tight-fit边界框预测。研究者还提出了一种有效的离线复制粘贴数据增强来进行目标检测。新提出的方法显着优于一些当前最先进的目标检测器,并有望获得更好的性能。二、背景目标检测网络旨在使用
 聊聊端到端与下一代自动驾驶系统,以及端到端自动驾驶的一些误区?
Apr 15, 2024 pm 04:13 PM
聊聊端到端与下一代自动驾驶系统,以及端到端自动驾驶的一些误区?
Apr 15, 2024 pm 04:13 PM
最近一个月由于众所周知的一些原因,非常密集地和行业内的各种老师同学进行了交流。交流中必不可免的一个话题自然是端到端与火爆的特斯拉FSDV12。想借此机会,整理一下在当下这个时刻的一些想法和观点,供大家参考和讨论。如何定义端到端的自动驾驶系统,应该期望端到端解决什么问题?按照最传统的定义,端到端的系统指的是一套系统,输入传感器的原始信息,直接输出任务关心的变量。例如,在图像识别中,CNN相对于传统的特征提取器+分类器的方法就可以称之为端到端。在自动驾驶任务中,输入各种传感器的数据(相机/LiDAR
 目标检测新SOTA:YOLOv9问世,新架构让传统卷积重焕生机
Feb 23, 2024 pm 12:49 PM
目标检测新SOTA:YOLOv9问世,新架构让传统卷积重焕生机
Feb 23, 2024 pm 12:49 PM
在目标检测领域,YOLOv9在实现过程中不断进步,通过采用新架构和方法,有效提高了传统卷积的参数利用率,这使得其性能远超前代产品。继2023年1月YOLOv8正式发布一年多以后,YOLOv9终于来了!自2015年JosephRedmon和AliFarhadi等人提出了第一代YOLO模型以来,目标检测领域的研究者们对其进行了多次更新和迭代。 YOLO是一种基于图像全局信息的预测系统,其模型性能不断得到增强。通过不断改进算法和技术,研究人员取得了显着的成果,使得YOLO在目标检测任务中表现出越来越强大
 nuScenes最新SOTA | SparseAD:稀疏查询助力高效端到端自动驾驶!
Apr 17, 2024 pm 06:22 PM
nuScenes最新SOTA | SparseAD:稀疏查询助力高效端到端自动驾驶!
Apr 17, 2024 pm 06:22 PM
写在前面&出发点端到端的范式使用统一的框架在自动驾驶系统中实现多任务。尽管这种范式具有简单性和清晰性,但端到端的自动驾驶方法在子任务上的性能仍然远远落后于单任务方法。同时,先前端到端方法中广泛使用的密集鸟瞰图(BEV)特征使得扩展到更多模态或任务变得困难。这里提出了一种稀疏查找为中心的端到端自动驾驶范式(SparseAD),其中稀疏查找完全代表整个驾驶场景,包括空间、时间和任务,无需任何密集的BEV表示。具体来说,设计了一个统一的稀疏架构,用于包括检测、跟踪和在线地图绘制在内的任务感知。此外,重
 如何利用C++进行高性能的图像追踪和目标检测?
Aug 26, 2023 pm 03:25 PM
如何利用C++进行高性能的图像追踪和目标检测?
Aug 26, 2023 pm 03:25 PM
如何利用C++进行高性能的图像追踪和目标检测?摘要:随着人工智能和计算机视觉技术的快速发展,图像追踪和目标检测成为了重要的研究领域。本文将通过使用C++语言和一些开源库,介绍如何实现高性能的图像追踪和目标检测,并提供代码示例。引言:图像追踪和目标检测是计算机视觉领域中的两个重要任务。它们在许多领域中都有着广泛的应用,如视频监控、自动驾驶、智能交通系统等。为了
 多个SOTA !OV-Uni3DETR:提高3D检测在类别、场景和模态之间的普遍性(清华&港大)
Apr 11, 2024 pm 07:46 PM
多个SOTA !OV-Uni3DETR:提高3D检测在类别、场景和模态之间的普遍性(清华&港大)
Apr 11, 2024 pm 07:46 PM
这篇论文讨论了3D目标检测的领域,特别是针对Open-Vocabulary的3D目标检测。在传统的3D目标检测任务中,系统需要在预测真实场景中物体的定位3D边界框和语义类别标签,这通常依赖于点云或RGB图像。尽管2D目标检测技术因其普遍性和速度展现出色,但相关研究表明,3D通用检测的发展相比之下显得滞后。当前,大多数3D目标检测方法仍依赖于完全监督学习,并受到特定输入模式下完全标注数据的限制,只能识别经过训练过程中出现的类别,无论是在室内还是室外场景。这篇论文指出,3D通用目标检测面临的挑战主要
 2024年,端到端自动驾驶在国内是否会有实质性的突破和进展?
May 08, 2024 pm 02:49 PM
2024年,端到端自动驾驶在国内是否会有实质性的突破和进展?
May 08, 2024 pm 02:49 PM
并非所有人都能理解TeslaV12在北美大范围推送以及凭借其优良的表现开启获得越来越多用户认同的局面,端到端自动驾驶也成为自动驾驶行业里大家最为关注的技术方向。最近有机会和很多行业中的一流工程师、产品经理、投资者、媒体人进行了一些交流,发现大家对端到端自动驾驶很感兴趣,但甚至在一些对端到端自动驾驶的基本理解上还存在着这样那样的误区。作为有幸体验过国内一线品牌有图无图城市功能,同时又体验过FSDV11和V12两个版本的人,在这里我想结合自己专业背景和对TeslaFSD常年的进展跟踪,谈谈几个现阶段
