

Ilya离职后第一个动作:点赞了这篇论文,网友抢着传看

自Ilya Sutskever官宣离职OpenAI后,他的下一步动作成了大家关注焦点。
甚至有人密切关注着他的一举一动。
这不,Ilya前脚刚刚点赞❤️了一篇新论文——
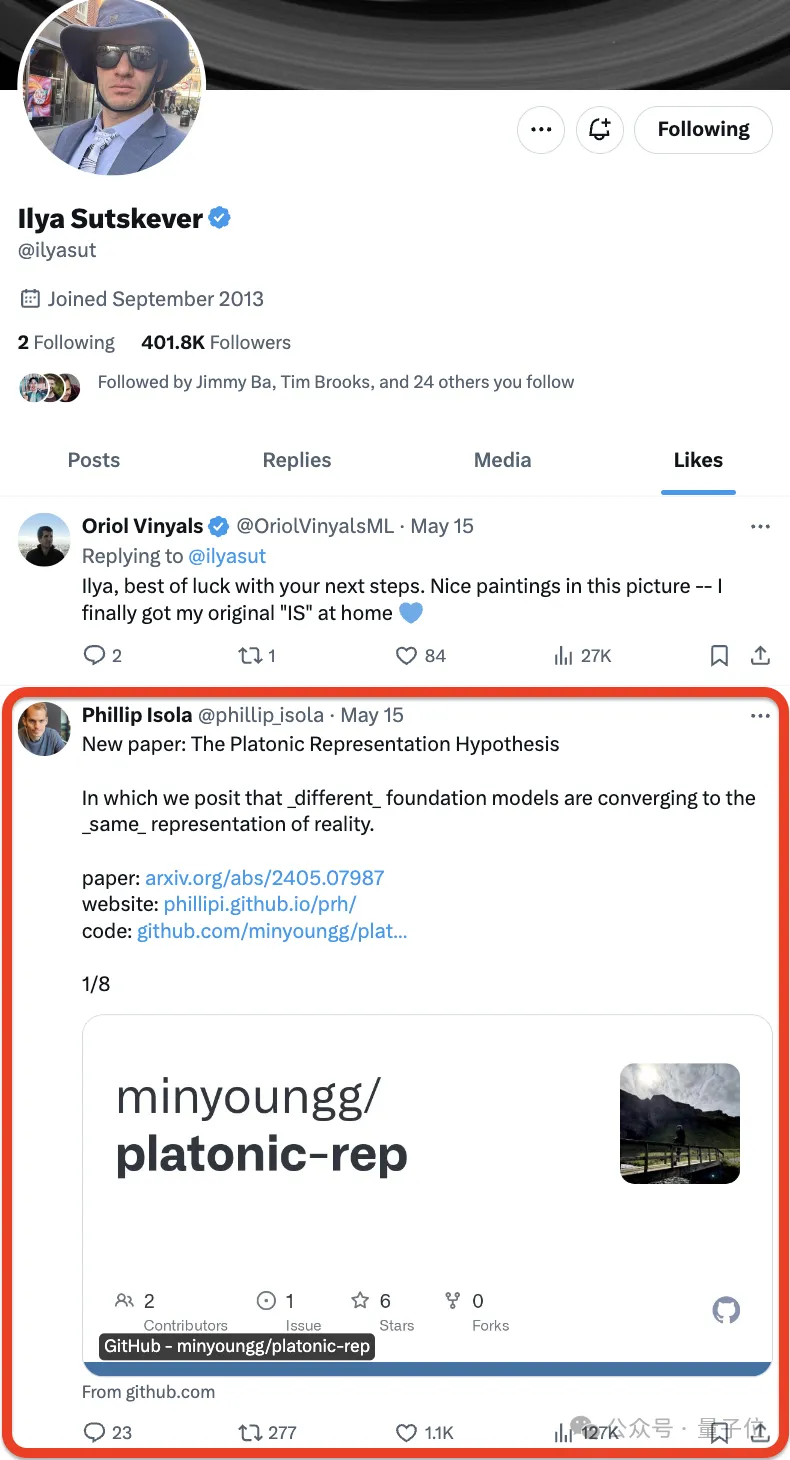
——网友们后脚就抢着都看上了:

论文来自MIT,作者提出了一个假说,用一句话总结是这样婶儿的:
神经网络在不同的数据和模态上以不同目标进行训练,正趋向于在其表示空间中形成一个共享的现实世界统计模型。

他们将这种推测起名为柏拉图表示假说,参考了柏拉图的洞穴寓言以及其关于理想现实本质的观念。

Ilya甄选还是有保障的,有网友看过后将其称为是今年看到的最好的论文:

还有网友真的有才,看完后化用《安娜·卡列尼娜》开篇的一句话来总结:所有幸福的语言模型都是相似的,每个不幸的语言模型都有自己的不幸。

化用怀特海名言:所有机器学习都是柏拉图的注脚。

俺们也来看了一下,大概内容是:
作者分析了AI系统的表征收敛(Representational Convergence),即不同神经网络模型中的数据点表征方式正变得越来越相似,这种相似性跨不同的模型架构、训练目标乃至数据模态。
是什么推动了这种收敛?这种趋势会持续下去吗?它的最终归宿在哪里?
经过一系列分析和实验,研究人员推测这种收敛确实有一个终点,并且有一个驱动原则:不同模型都在努力达到对现实的准确表征。
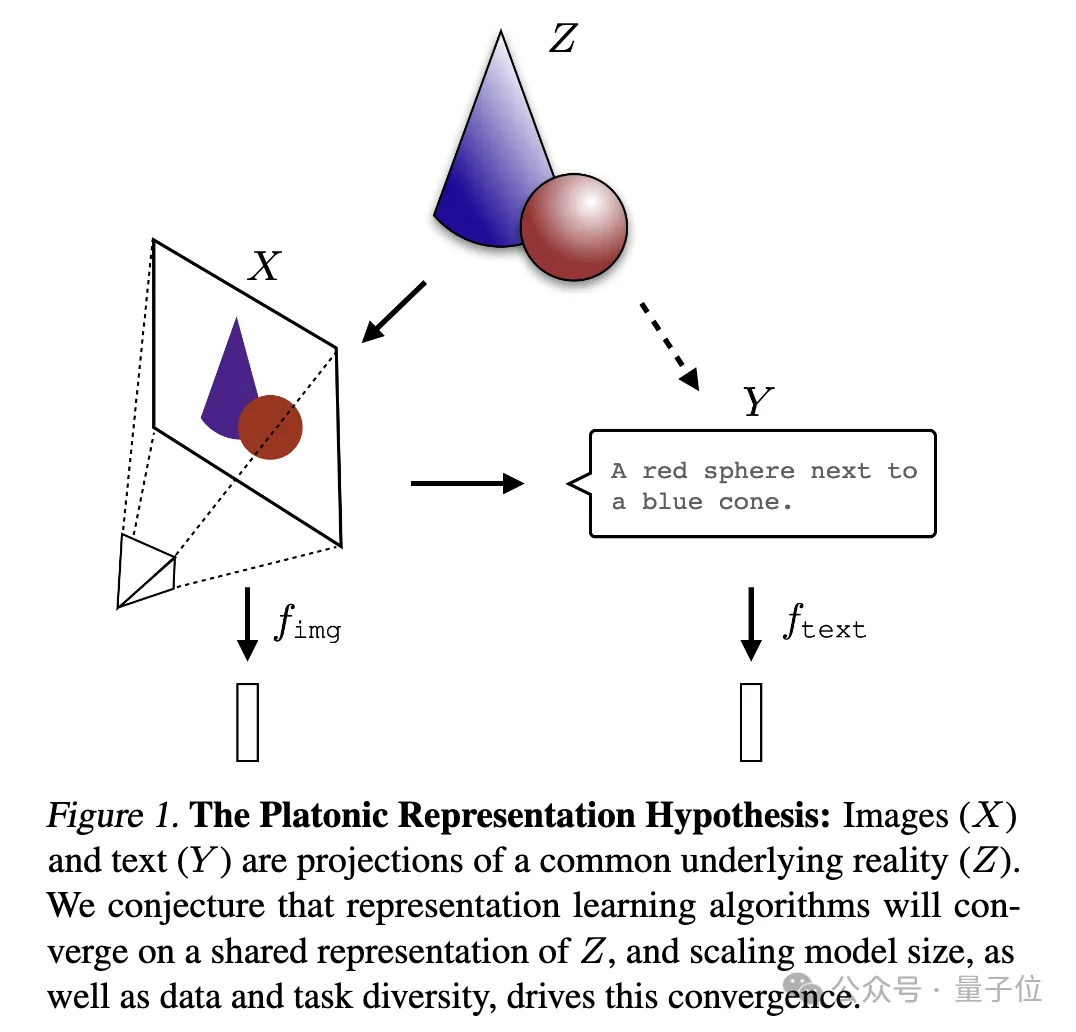
一张图来解释:
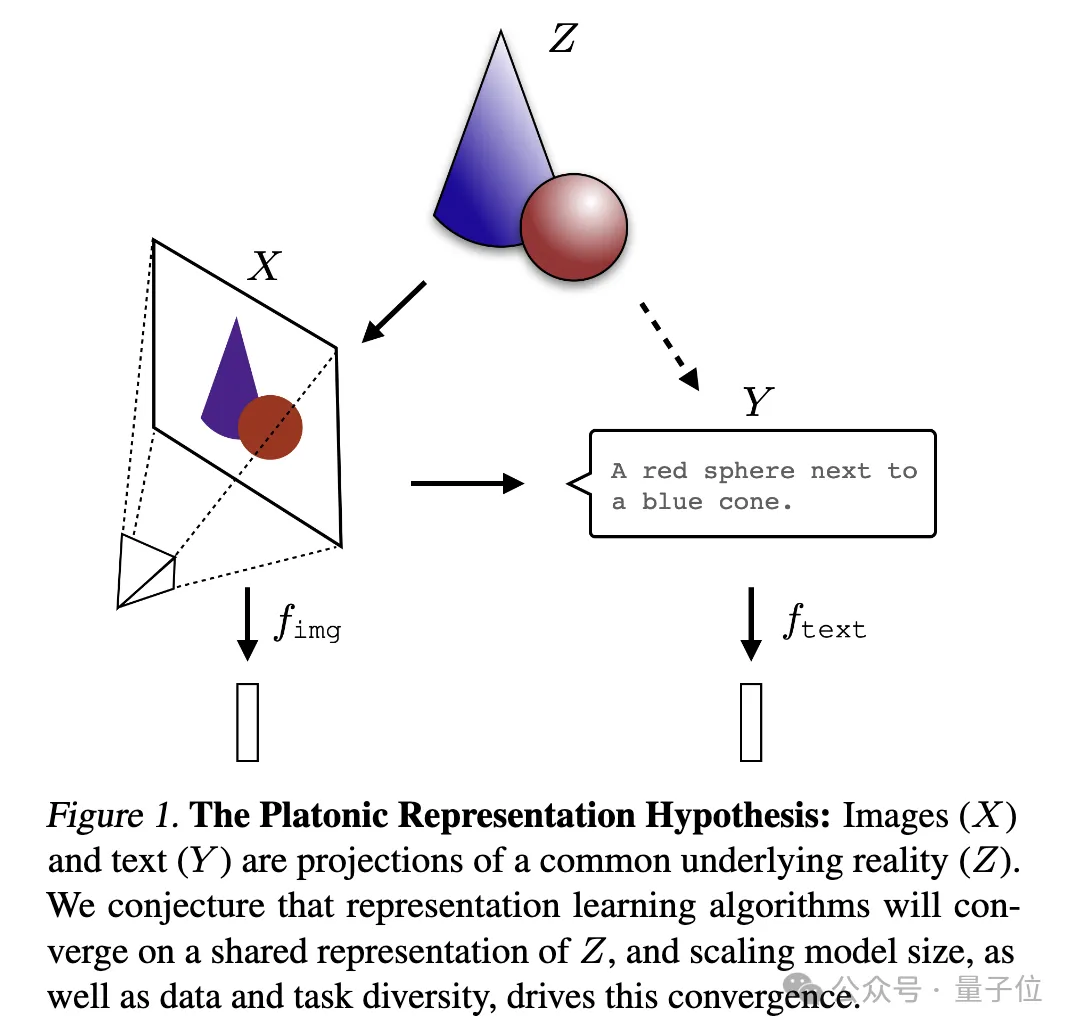
其中图像(X)和文本(Y)是共同底层现实(Z)的不同投影。研究人员推测,表征学习算法将收敛到对Z的统一表征上,而模型规模的增加、数据和任务的多样性是推动这种收敛的关键因素。
只能说,不愧是Ilya感兴趣的问题,太深奥了,俺们也不太懂,下面请AI帮忙解读了一下给大家分享~

表征收敛的证据
首先,作者分析了大量先前的相关研究,同时也自己上手做了实验,拿出了一系列表征收敛的证据,展示了不同模型的收敛、规模与性能、跨模态的收敛。
Ps:这项研究重点关注向量嵌入表征,即数据被转化成向量形式,通过核函数描述数据点之间的相似性或距离。文中“表征对齐”概念,即如果两种不同的表征方法揭示了类似的数据结构,那么这两种表征被视为是对齐的。
1、不同模型的收敛,不同架构和目标的模型在底层表示上趋于一致。
目前基于预训练基础模型构建的系统数量逐渐增加,一些模型正成为多任务的标准核心架构。这种在多种应用上的广泛适用性体现了它们在数据表征方式上具有一定通用性。
虽然这种趋势表明AI系统正朝着一组较小的基础模型集合收敛,但并不能证明不同的基础模型会形成相同的表征。
不过,最近一些与模型拼接(model stitching)相关的研究发现,即使在不同数据集上训练,图像分类模型的中间层表征也可以很好地对齐。
比如有研究发现,在ImageNet和Places365数据集上训练的卷积网络的早期层可以互换,表明它们学习到了相似的初始视觉表征。还有研究发现了大量“罗塞塔神经元”(Rosetta Neurons),即在不同视觉模型中被激活的模式高度相似的神经元……
2、模型规模和性能越大,表征对齐程度越高。
研究人员在Places-365数据集上使用相互最近邻方法衡量了78个模型的对齐情况,并评估了它们在视觉任务适应基准VTAB的下游任务表现。
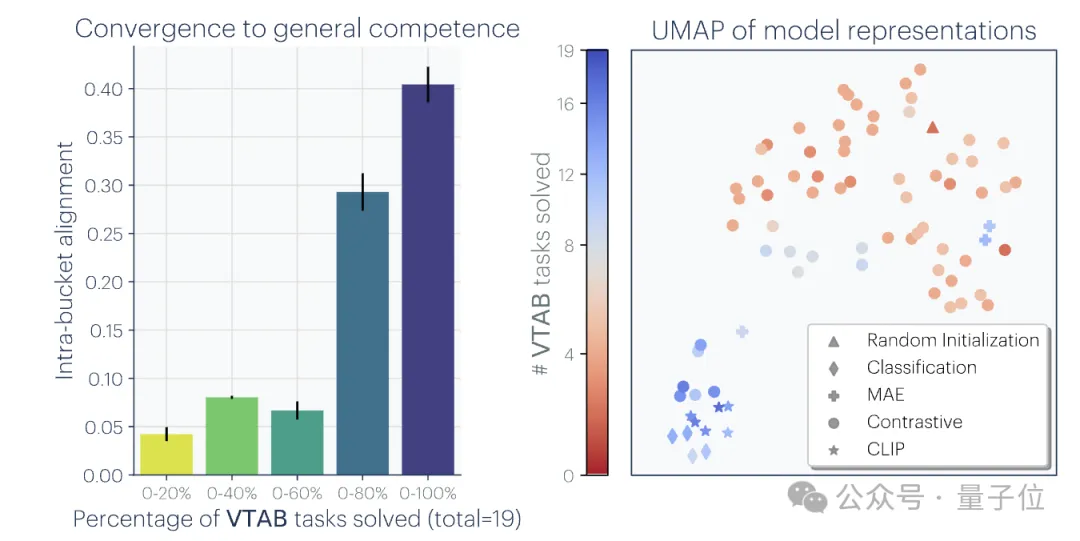
结果发现,泛化能力更强的模型集群之间的表征对齐度明显更高。
之前还有研究观察到,较大模型之间的CKA内核对齐度更高。在理论上也有研究证明了输出性能相似的模型内部激活也必然相似。
3、不同模态的模型表征收敛。
研究人员在维基百科图像数据集WIT上使用相互最近邻方法来测量对齐度。
结果揭示了语言-视觉对齐度与语言建模分数之间存在线性关系,一般趋势是能力更强的语言模型与能力更强的视觉模型对齐得更好。

4、模型与大脑表征也显示出一定程度的一致性,可能由于面临相似的数据和任务约束。
2014年就有研究发现,神经网络的中间层激活与大脑视觉区的激活模式高度相关,可能是由于面临相似的视觉任务和数据约束。
此后有研究进一步发现,使用不同训练数据会影响大脑和模型表征的对齐程度。心理学研究也发现人类感知视觉相似性的方式与神经网络模型高度一致。
5、模型表征的对齐程度与下游任务的性能呈正相关。
研究人员使用了两个下游任务来评估模型的性能:Hellaswag(常识推理)和GSM8K(数学)。并使用DINOv2模型作为参考,来衡量其他语言模型与视觉模型的对齐程度。
实验结果显示,与视觉模型对齐程度更高的语言模型在Hellaswag和GSM8K任务上的性能也更好。可视化结果显示,对齐程度与下游任务性能之间存在明显的正相关。
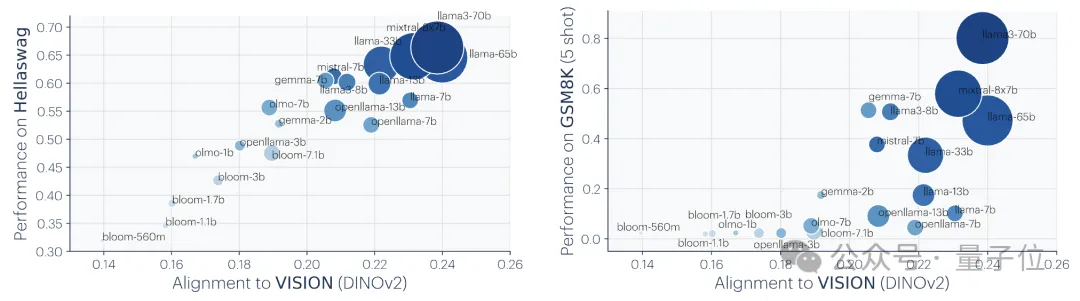
之前的研究这里就不展开说了,感兴趣的家人们可查看原论文。
收敛的原因
接着,研究团队通过理论分析和实验观察,提出了表征收敛的潜在原因,并讨论了这些因素如何共同作用,导致不同模型在表示现实世界时趋于一致。
机器学习领域,模型的训练目标需减少在训练数据上的预测误差。为了防止模型过拟合,通常会在训练过程中加入正则化项。正则化可以是隐式,也可以是显式。
研究人员在这部分阐述了这个优化过程中,下图每个彩色部分如何可能在促进表征收敛中发挥作用。

1、任务通用性导致收敛(Convergence via Task Generality)
随着模型被训练来解决更多任务,它们需要找到能够满足所有任务需求的表征:
能够胜任N个任务的表征数量少于能够胜任M个(M

此前也有过过类似的原理被提出,图解是这样婶儿的:

而且,容易的任务有多种解决方案,而困难的任务解决方案较少。因此,随着任务难度的增加,模型的表征趋于收敛到更优的、数量更少的解决方案上。
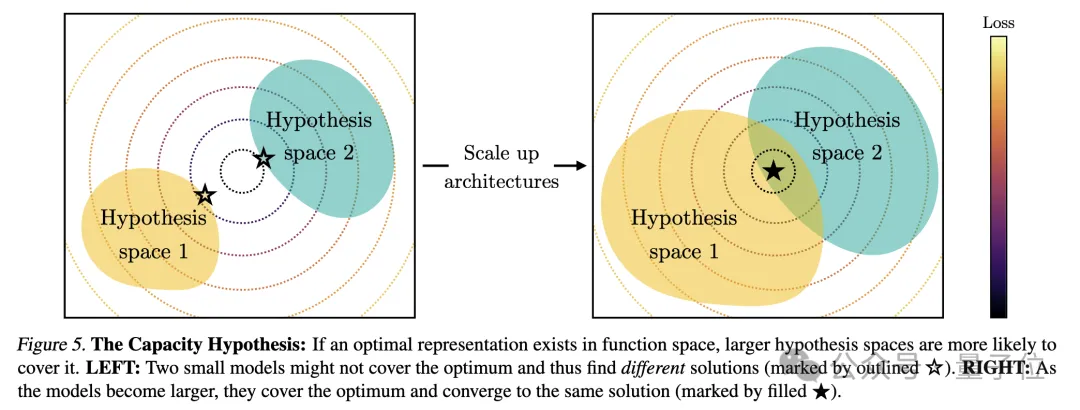
2、模型容量导致收敛(Convergence via Model Capacity)
研究人员指出了容量假设,如果存在一个全局最优的表征,那么在数据足够的条件下,更大的模型更有可能逼近这个最优解。
因此,使用相同训练目标的较大模型,无论其架构如何,都会趋向于这一最优解的收敛。当不同的训练目标有相似的最小值时,较大的模型更能有效地找到这些最小值,并在各训练任务中趋于相似的解决方案。

图解是这样婶儿的:
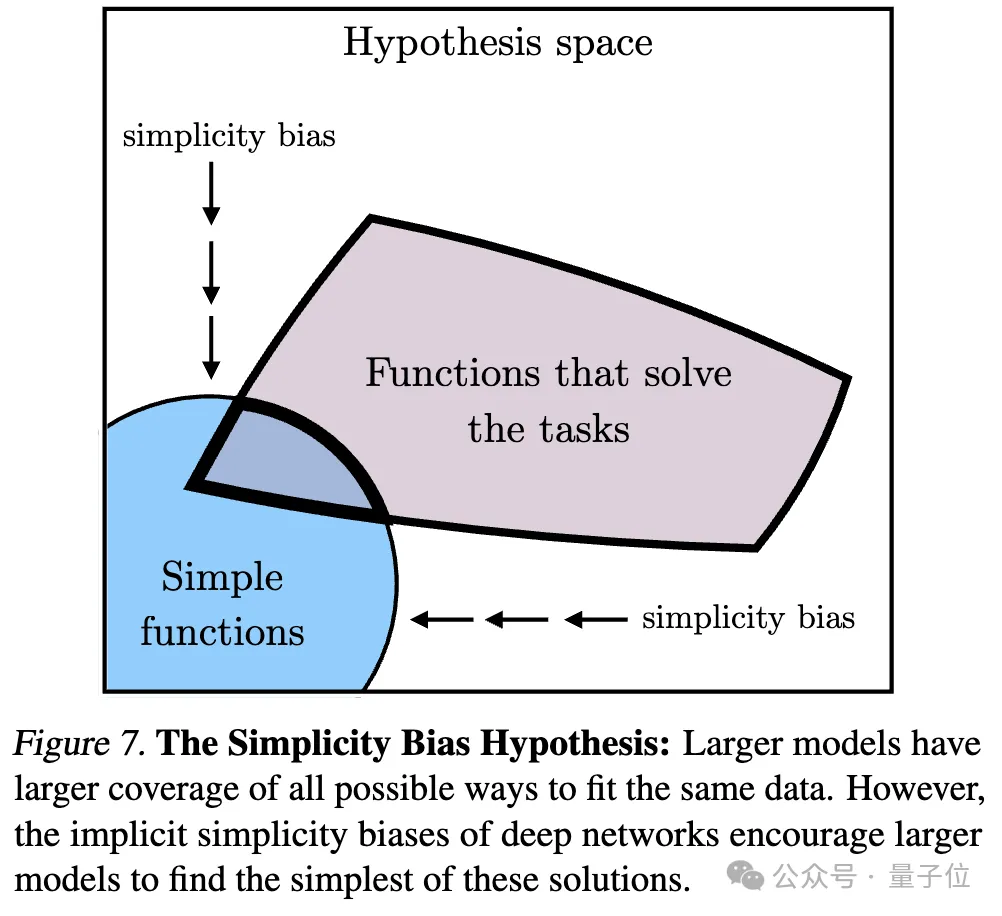
3、简单性偏差导致收敛(Convergence via Simplicity Bias)
关于收敛的原因,研究人员还提出了一种假设。深度网络倾向于寻找数据的简单拟合,这种内在的简单性偏差使得大模型在表示上趋于简化,从而导致收敛。

也就是说,较大的模型拥有更广泛的覆盖范围,能够以所有可能的方式拟合相同的数据。然而,深度网络的隐性简单性偏好鼓励较大的模型找到这些解决方案中最简单的一个。
收敛的终点
经过一系列分析与实验,如开头所述,研究人员提出了柏拉图表示假说,推测了这种收敛的终点。
即不同的AI模型,尽管在不同的数据和目标上训练,它们的表示空间正在收敛于一个共同的统计模型,这个模型代表了生成我们观察到的数据的现实世界。
他们首先构建了一个理想化的离散事件世界模型。该世界包含一系列离散事件Z,每个事件都是从某未知分布P(Z)中采样得到的。每个事件可以通过观测函数obs以不同方式被观测,如像素、声音、文字等。
接下来,作者考虑了一类对比学习算法,这类算法试图学习一个表征fX,使得fX(xa)和fX(xb)的内积近似于xa和xb作为正样本对(来自临近观测)的对数odds与作为负样本对(随机采样)的对数odds之比。

经过数学推导,作者发现如果数据足够平滑,这类算法将收敛到一个核函数是xa和xb的点互信息(PMI)核的表征fX。

由于研究考虑的是一个理想化的离散世界,观测函数obs是双射的,因此xa和xb的PMI核等于相应事件za和zb的PMI核。

这就意味着,无论是从视觉数据X还是语言数据Y中学习表征,最终都会收敛到表示P(Z)的相同核函数,即事件对之间的PMI核。

研究人员通过一个关于颜色的实证研究来验证这一理论。无论是从图像的像素共现统计中还是从文本的词语共现统计中学习颜色表征,得到的颜色距离都与人类感知相似,并且随着模型规模增大,这种相似性也越来越高。
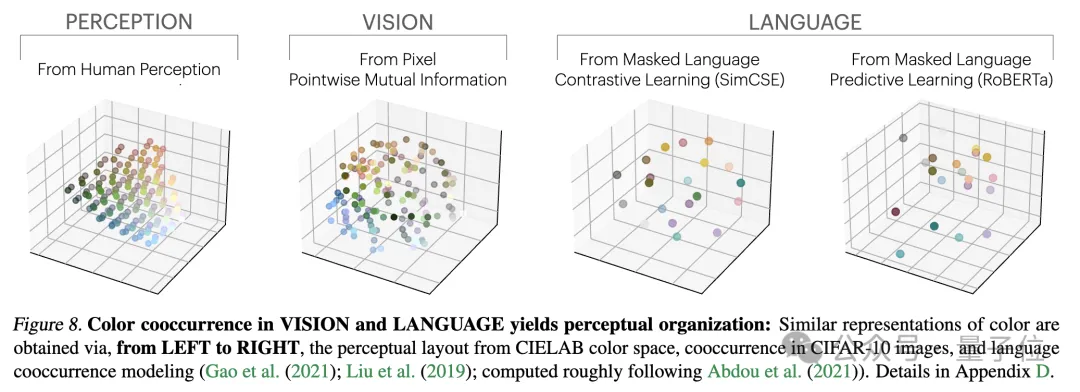
这符合了理论分析,即更大的模型能力可以更准确地建模观测数据的统计量,进而得到更接近理想事件表征的PMI核。
最后的一些思考
论文最后,作者总结了表征收敛对AI领域和未来研究方向的潜在影响,以及柏拉图式表征假设的潜在限制和例外情况。
他们指出,随着模型规模的增加,表示的收敛可能会带来的影响包括但不限于:
- 虽然简单扩大规模可以提高性能,但不同方法在扩展效率上存在差异。
- 如果存在模态无关的柏拉图式表征,那么不同模态的数据应当被联合训练以找到这种共享表征。这解释了为什么将视觉数据加入语言模型训练是有益的,反之亦然。
- 对齐的表征之间的转换应相对简单,这可能解释了:有条件生成比无条件生成更容易、无配对数据也可实现跨模态转换。
- 模型规模扩大可能会减少语言模型的虚构内容倾向和某些偏差,使其更准确反映训练数据中的偏差,而非加剧偏差。
作者强调,上述影响的前提是,未来模型的训练数据要足够多样和无损,才能真正收敛到反映实际世界统计规律的表征。
同时,作者也表示,不同模态的数据可能包含独特的信息,可能导致即使在模型规模增加的情况下,也难以实现完全的表示收敛。此外,目前并非所有表征都在收敛,例如机器人领域还没有标准化的状态表征方式。研究者和社区的偏好可能导致模型向人类表征方式收敛,从而忽略了其他可能的智能形式。
而且专门设计用于特定任务的智能系统,可能不会与通用智能收敛到相同的表征。
作者还强调了测量表示对齐的方法存在争议,不同的度量方法可能会导致不同的结论。即使不同模型的表征相似,但还有差距有待解释,目前无法确定这种差距是否重要。
更多细节及论证方法,给大噶把论文放这儿了~
论文链接:https://arxiv.org/abs/2405.07987
以上是Ilya离职后第一个动作:点赞了这篇论文,网友抢着传看的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)







 谷歌狂喜:JAX性能超越Pytorch、TensorFlow!或成GPU推理训练最快选择
Apr 01, 2024 pm 07:46 PM
谷歌狂喜:JAX性能超越Pytorch、TensorFlow!或成GPU推理训练最快选择
Apr 01, 2024 pm 07:46 PM
谷歌狂喜:JAX性能超越Pytorch、TensorFlow!或成GPU推理训练最快选择

 快手版Sora「可灵」开放测试:生成超120s视频,更懂物理,复杂运动也能精准建模
Jun 11, 2024 am 09:51 AM
快手版Sora「可灵」开放测试:生成超120s视频,更懂物理,复杂运动也能精准建模
Jun 11, 2024 am 09:51 AM
快手版Sora「可灵」开放测试:生成超120s视频,更懂物理,复杂运动也能精准建模
 美国空军高调展示首个AI战斗机!部长亲自试驾全程未干预,10万行代码试飞21次
May 07, 2024 pm 05:00 PM
美国空军高调展示首个AI战斗机!部长亲自试驾全程未干预,10万行代码试飞21次
May 07, 2024 pm 05:00 PM
美国空军高调展示首个AI战斗机!部长亲自试驾全程未干预,10万行代码试飞21次
