

工业知识图谱进阶实战

一、背景简介
首先来介绍一下云问科技的发展历程。

云问科技公...
2023年,正是大模型盛行的时期,很多企业认为已经大模型之后图谱的重要性大大降低了,之前研究的预置的信息化系统也都不重要了。不过随着 RAG 的推广、数据治理的盛行,我们发现更高效的数据治理和高质量的数据是提升私有化大模型效果的重要前提,因此越来越多的企业开始重视知识建设的相关内容。这也推动了知识的构建和加工开始向更高水平发展,其中有很多技巧和方法可以挖掘。可见一个新技术的出现,并不是将所有的旧技术打败,也有可能将新技术和旧技术相互融合后,会实现更好的结果。我们要站在巨人的肩膀上不断向前扩展。
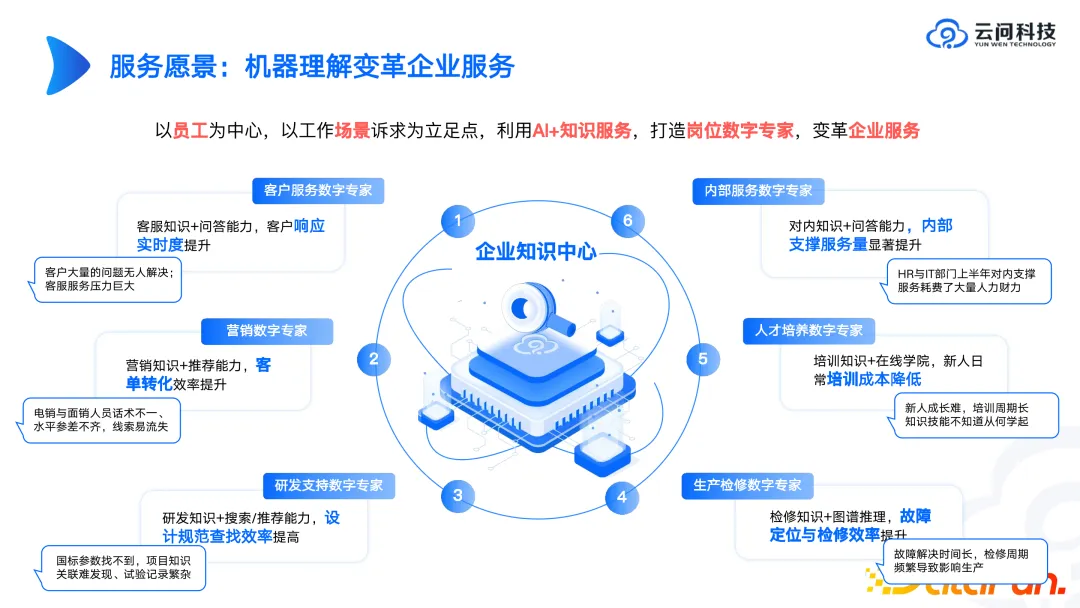
云问科技为什么会聚焦在企业知识中心这方面内容呢?因为我们在过去的一些案例中发现,当面对很多复杂场景时,比如风控、药物检测等,直接让大模型去做这些复杂任务,在短期内很难取得理想效果,很难打造出一个标准化产品进行交付。而在企业知识管理或办公相关的业务管理场景中则可以较为快速地进入试运行,并可能获得理想效果。所以我们今年在同企业共创私有化大模型时,都会把企业的知识管理,包括基于企业知识管理的问答或搜索纳入其中,作为一个重点课题。对于企业来说,自身的私有化知识和知识中心的建设是十分重要的。
基于这些原因,如果有小伙伴想要研究知识图谱方向,我们的建议是从知识的全生命周期去考虑,思考要解决的问题和具体的落地点。比如有企业利用现有的一些文档生成考试、培训、面试相关的内容,虽然这些技术热词那么火热,但是这样的私有化模型会比 GPT3.5 或者 GPT4 的效果更好,因为在这个场景里面已经经过了一些场景预制。因此我们认为更专、更精的模型将是未来发展的一大趋势。
二、图谱产品形态
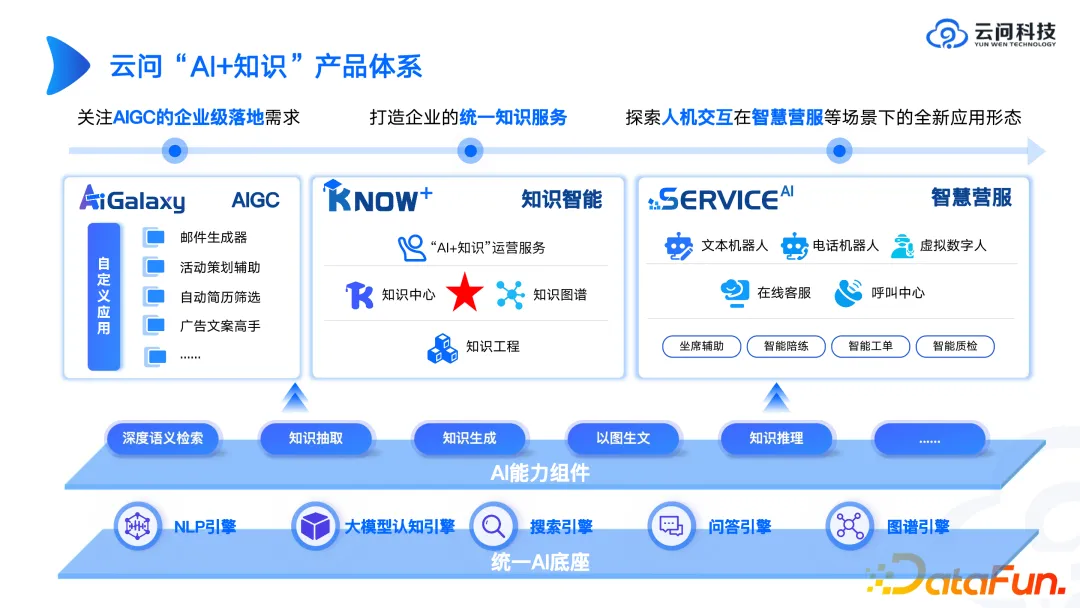
在上述背景下,图谱产品形态会是什么样子呢?接下来以云问科技的“AI+知识”产品体系为例来进行介绍。
首先要有统一的 AI 底座,这并不是靠一个团队、甚至一家公司就能做好的。可以利用大模型引擎的第三方 API 或者 SDK,很多时候不一定要从零到一去造轮子,因为很可能花了数月造出的轮子的效果还不如刚刚发布的一个开源模型的效果。所以 AI 底座部分建议更多地思考如何结合第三方技术,如果自己研发就要想清楚优势在哪,当然发挥平台价值二者兼顾是最好的。
关于 AI 能力组件,从我们的一些交付经验里发现,这些AI 能力组件往往会比产品更好卖。因为很多企业都希望可以利用专业技术公司搭建的组件去构建自己的上层应用。在大模型时代下卖 AI 能力组件就像是卖铲子,而金矿还由大企业自己去挖掘。
在上层应用方面,我们会从 AIGC 本身的应用、知识智能和智能营服这三个方向落地。探索在哪个方向上会有更大的价值。而知识图谱被我们划归为整个知识智能里面的一个核心环节。需要注意的是,知识图谱是核心但不是唯一。我们之前遇到很多场景,客户有大量的关系型数据库和大量的非结构化文档,希望我们可以将这些知识体系和知识资产全部纳入到知识图谱中去,这样做的代价是非常大的。我们认为未来的知识架构应该是异构的,既有一部分知识在文档中,也有一部分知识在关系数据库中,还有一部分知识可能来自于图谱网络,而最终大模型要做的是基于多源异构数据做综合分析。比如一个情报,可以从关系型数据库中提取一些数值指标,在文档中找到一些建议,从工单中搜索出一些历史信息,再将所有内容整理在一起进行分析。这就是我们认为大模型和知识图谱的一种结合方式。在一个整体架构中,大模型做最终的分析,而知识图谱通过其知识表示体系帮助大模型更快速、更准确地找到背后隐藏的知识。
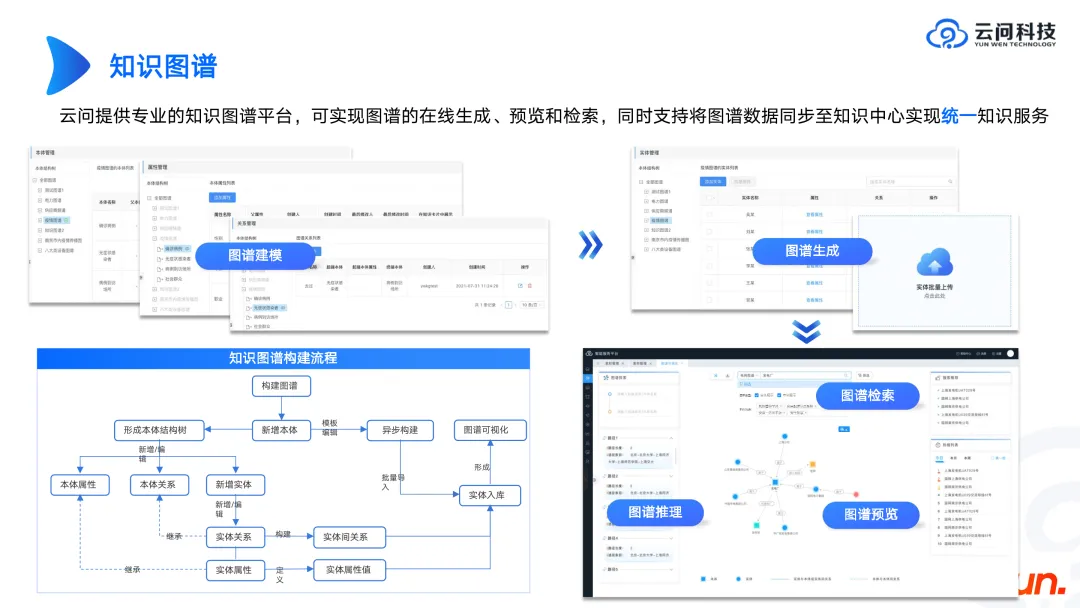
前面探讨了大模型和图谱之间的关系,接下来回顾一下图谱本身需要有些什么。
首先,图谱的背后是一个图数据库,比如开源的 Neo4j、Genius Graph,还有一些国产的数据库品牌。知识图谱和图数据库是两个不同的概念,打造一个知识图谱产品,相当于在图数据库的上层做了一个封装,以实现快速的图谱建模和可视化。
要打造知识图谱产品时,可以先参考 Neo4j 或国内一些大厂的知识图谱产品的产品形态,这样就能大概了解到知识图谱产品需要实现哪些功能和环节。更重要的是要知道如何搭建一个知识图谱,这看起来是个业务问题,因为不同企业、不同场景,图谱都是不一样的。作为技术人员,如果不了解电力、设备、工业等等,就不可能搭建出一个令业务满意的图谱。需要与业务不断沟通,经过不断迭代才能最终得到一个结果。讨论的过程其实可以回归到 schema 的本质,把图谱的一套本体理论和逻辑概念全部呈现出来,这些内容是非常重要的。当 schema 定好后,后续就可以让更多的相关人员参与进来将内容丰富,进一步完善产品。这是我们目前的一些经验。

下面介绍一下图谱的总体特征。目前知识图谱还是以三元组为主,在此基础上构建实体、属性、关系等多颗粒度多层次的语义关系。在工业界,我们经常会遇到一些三元组无法解决的问题,当我们用设定好的实体属性值去刻画真实物理世界时会出现很多问题。这时候我们就会将带约束的条件,以 CVT 的方式来实现。所以大家在构建知识图谱的时候要先论证三元组能解决当前的问题。
需要指出的一点是,在构建图谱时一定要按需构建,因为世界是无穷的,里面的知识内容也是无穷的。在刚开始,我们常常会有一个愿景,就是将所有的物理世界中存在的实体都刻划到我们的计算机世界。这么做会带来的问题就是最后构建的整套schema 过于复杂,对于真实业务没有帮助。比如,地球绕着太阳转这个事实,我可以把它构建在三元组中。但这个三元组能并不能解决我当下面对的实际问题,所以一定要按需构建三元组。
那么常识类的问题怎么处理呢?很多问题确实需要常识类的三元组。我们认为这可以交由大模型来做。我们更希望知识图谱能够发掘专业性,把真正相关联的知识构建在图谱中。然后大模型可以基于常识,再结合以知识图谱提供的在开放领域中无法获取的先验知识,来实现更好的效果。

知识图谱的构建需要业务人员和运营人员共同去设计,包括本体、关系、属性和实体的定义,以及如何可视化。最终会涉及到一个问题,就是从产品形态上呈现哪些内容给用户。如果用户是最终的消费者,那么只需要呈现可视化搜索和问答就可以了。因为这类客户并不关心图谱是如何构建的,是自动化还是手工。
这里又涉及另一个很重要的问题,就是即使在大模型场景下,也不是所有的图谱都能够自动化构建。图谱的构建成本非常高,我们与其花费大量的精力在图谱的建模上,还不如把精力花在消费上。如果想达到业务接受的效果,就可能要依赖手工构建。比如一个格式确定的表格,如果跨表很复杂,我们可以尝试是否可以用大模型来寻求一个 baseline。这样就可以把精力从构建转移到消费上。比如一个项目周期有 100 天,我们花了 70 天来构建图谱,最后的 30 天来思考这个图谱的应用场景,或者因为前期构建时间延长,造成没有时间来思考有价值的消费场景,就可能带来很大的问题。根据我们的经验,应该在构建上花费少量的时间,或者是默认为手工构建。然后花大量的时间来思考如何让构建好的图谱发挥最大的价值。

上图展示了知识图谱构建的流程。在构建本体的时候我们一定要接受本体是变化的,就像数据库本身的表结构也可能会更新。所以在设计时,一定要考虑其鲁棒性和扩展性。比如,我们在做某一类设备的图谱时,应该考虑到整套设备的体系。未来可能要通过这个体系来搜索设备,并且也应该了解到这个体系下其它设备还没有构建图谱,未来可以去建。通过整个大的体系为用户带来更大的价值。
我们经常听到的一个问题是,我可以通过 FAQ 也可以通过大模型来找到答案,为什么还要用图谱呢?我们的回答是,如果我们把当前的知识和图谱做关联后,看到的世界就不再是一维的,而是一个网状的世界,这是图谱在消费端可以实现的一个价值,而其他技术很难实现。目前大家的关注点往往会放在量级以及使用了什么高级的算法等,但其实更应该从消费和解决问题的方向出发来思考图谱的构建。

在大模型盛行的当下,我们需要考虑大模型和图谱的结合。可以认为图谱是上层应用,而大模型是底层能力。我们可以从不同场景去理解大模型对图谱带来了什么帮助。
在图谱构建时,可以通过一些文档和提示词进行信息抽取,来替代原来的 UIE、NER 等相关技术,从而使抽取能力进一步提高。也要考虑在 zero-shot,few-shot 和充足数据训练的情况下究竟是大模型好还是小模型好。这种问题并没有单一的答案,不同场景、不同数据集会有不同的方案。这是一个全新的知识构建的路径。目前来看,在 zero-shot 的场景下,大模型的抽取能力更优。不过一旦样本量增加后,小模型从性价比和推理速度上都更具优势。
在消费端,对于运用图谱解决推理类问题,比如政策类的判断,例如判断一个企业是否能满足某个政策,能不能享受到政策中谈及的福利。先前的做法是通过图谱、规则和语句表达式来进行判断。现在的做法就像 Graph RAG 一样,通过用户的问句找到与当前企业相类似的三元组或者多元组,运用大模型来获取答案,得出结论。因此很多图谱推理类的问题、图谱构建的问题,都可以通过大模型技术解决。
图谱存储类的问题,图数据库和图谱本身的数据结构是很重要的,大模型短期内还无法处理长文本或整个图谱,所以图谱的存储是一个很重要的方向。它和向量数据库一样,会成为未来大模型生态圈里一个非常重要的组件。上层的应用会决定是否要使用这个组件来解决实际问题。

图谱可视化是偏前端的问题,需要根据场景和要解决的问题来进行设计。我们更希望可以把技术做成中台,提供某个能力,来满足未来不同的交互形态,比如移动端、PC、手持设备等等。我们只需要提供一个结构,前端如何渲染和呈现可以根据实际需求来确定。大模型也会是调用此类结构的一个方式。当大模型或 agent 可以基于需求来判定如何调用图谱,就可以打通闭环。图谱需要能封装更好的 API 来适配未来各种应用的调用。中台的概念正逐步被重视,一个独立的解耦的服务,能更加广泛地被各方使用。
比如有时需要找到某些遗留在文档中某个表格里的某个数值,通过搜索或者大模型技术很难去定位其位置,如果利用图谱的结构化能力将内容呈现出来,就可以通过在应用系统里调用某个接口来获得这个图谱的值,并把其所在的文档,或者大模型的分析结果呈现出来。这种可视化方式对于用户来说才是最高效的。这也是目前流行的 Copilot 的方式,即通过调用图谱、搜索或其它的应用能力,最后用大模型做“最后一公里”的生成来共同解决问题,达到提高效率的目的。

当下我们经常会做知识库和图谱的各种融合,今年有很多知识类项目出现。之前,知识主要供人搜索和消费。随着大模型的出现,大家发现也可以将知识供给大模型来消费。所以大家对知识的贡献和构建更加关注。我们本身有大量的知识,还需要第三方知识图谱系统,是因为我们的知识都是非结构化的,其中会有很多非常重要的知识,比如工单、设备维修的案例等,需要把这些知识以结构化的内容来存储,这些内容之前都是供搜索使用的,现在可以供大模型做 SFT。
知识库和图谱是天生可以结合的,当结合后,就可以对外统一提供一套知识服务类产品。这种知识服务类产品的生命力是十分旺盛的,无论在 OA、ERP、MIS,还是 PRM 系统中都会对知识有需求。
在融合的时候,要十分注意如何区分知识和数据。客户会提供大量数据,但这些数据可能并不是知识。我们需要从需求侧出发来定义知识。比如对于一个设备,我们通常需要了解什么内容,比如设备运行时的数据波动,这些都是数据,而这个设备的出厂时间、上次维修时间等等,这些则是知识。如何定义知识是十分重要的,需要在业务的参与和指导下共同构建。
三、工业图谱进阶

在数字化转型过程中,调度、设备、营销和分析等场景中都会用到 AI 与图谱的技术。尤其是在调度场景,无论是交通调度、能源调度还是人力调度,都是以任务下发的方式开展。比如出现火灾,要派多少人、多少车等等,在进行调度时需要查询一些相关数据,目前的问题往往不是找不到结果,而是返回的内容太多了,但不能给出真正有用的解决方案。因为对知识的消费形态还停留在关键词检索,所有包含“火灾”这个词的文档都会呈现出来。要获得更好的呈现,就可以通过图谱。比如在设计“火灾”这个本体时,它的上位本体是灾难,针对“火灾”这个实体可以设计它的注意事项、保护措施和经验案例。通过这些内容把知识进行分拆。这样当用户输入“火灾”时,就会呈现一个相关的图谱脉络和下一步应该做的事。
在调度相关场景中,应关注 Agent 这个方向。Agent 对于调度十分重要,因为调度本身是一个多任务场景。图谱返回的结果会更精确、更丰富。
智能设备方面也有很多应用场景。设备的信息会存储在不同的系统中,比如出厂信息存储在产品手册中,维修信息存储在维修工单中,运行状态存储于设备管理系统中,而巡检状态则存储在工业巡检系统中。工业上面对的一大问题就是系统太多。如果想要查询一个设备的信息,需要从多个系统中查询,并且这些系统中的数据是互不相通的。这时就需要一个系统可以打通连接,将所有内容关联映射起来。以知识图谱为核心的知识库就可以解决这个问题。
知识图谱可以通过本体将其相关的属性、字段、字段来源等等囊括进来,可以从底层刻画和关联各个系统之间的串并联关系。不过在构建图谱时,要牢记按需设计和构建图谱。很多企业在构建图谱时会将数据中台的数据通过 D2R 技术全部转移过来,这个图谱其实没有任何意义。在构建图谱时一定要考虑好动态图谱和静态图谱的关联。
在智能营销和多场景能源 AI 领域也有很多应用场景和设计技巧,在此不做展开,可以后续再进行探讨。

在构建图谱时,架构设计是非常重要的。如何将底层的库和工艺流程与图谱构建和消费结合起来。最终如何交付有很多细节需要思考。可以参考上图中列出的环节来进行设计和实践。
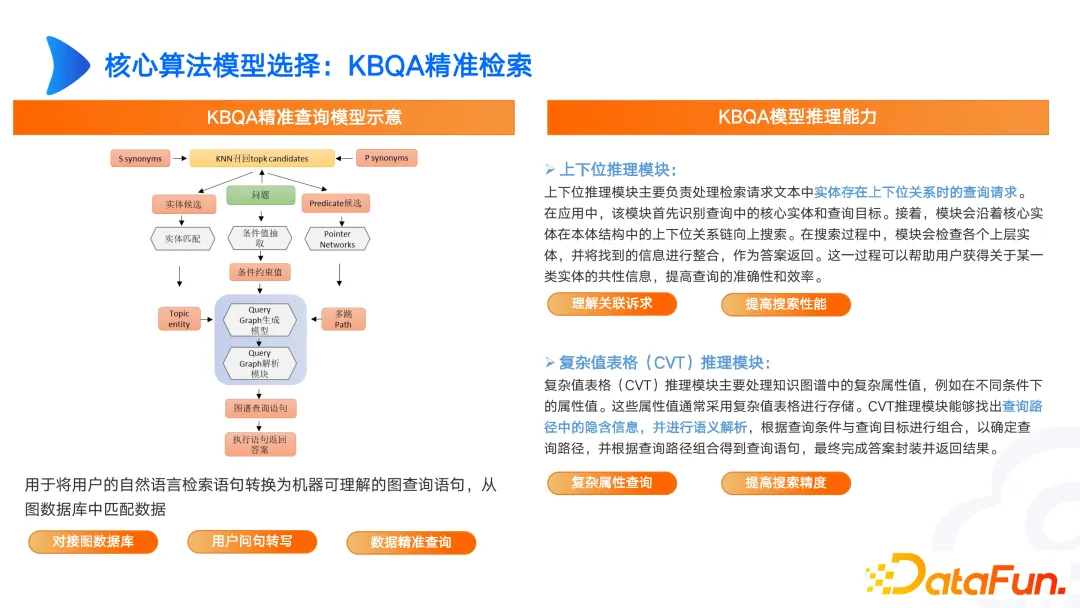
在图谱 KBQA 中我们也做了一些研究,比如上下位、图谱 CVT 查询等。比如医疗场景中,发烧和头疼对应的上位都是身体表征异常,知识库中不会对于发烧或者头疼进行单独存储,在原始文档中都是以身体轻微异常来存储。当用户表述和专业表述有差异时,我们就可以通过上下位的推理 CVT 来解决。
当前搭建的图谱可能只是 SPO 或多跳或 TransE 等实体对齐。但是在实际复杂场景下就需要 CVT 结合上下位来实现。还有很多论文在英文数据集上表现很好,但是在中文数据集上效果就不太理想。所以我们需要结合自己的需求来设计,并不断迭代,才能达到好的效果。
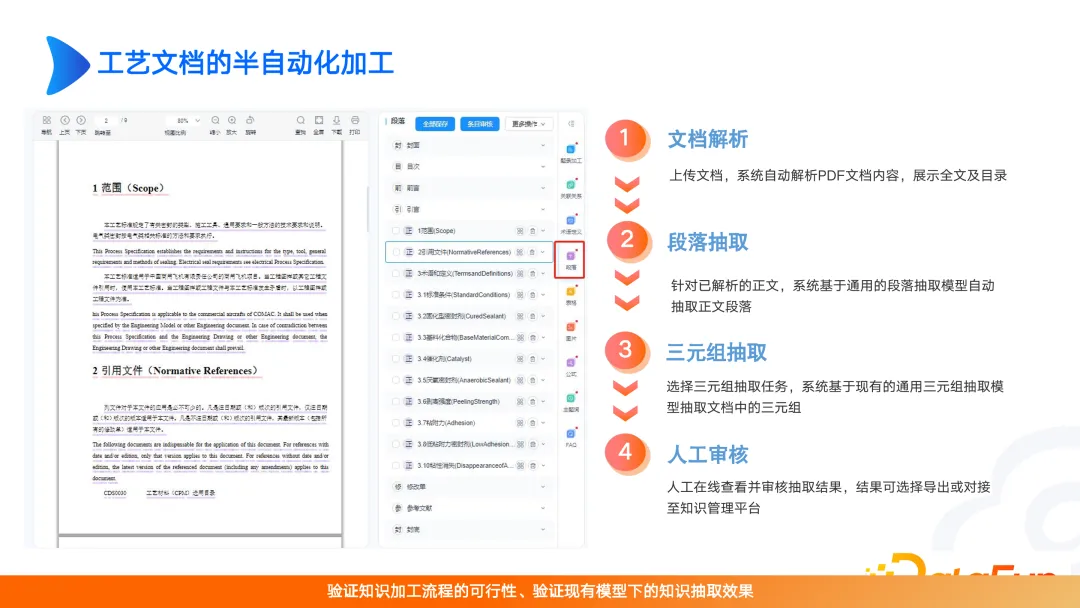
半自动化文档加工,包含文档解析、段落抽取、三元组抽取和人工审核。人工审核这一步常常会被忽略,尤其是在大模型到来后,大家更不关注人工审核。其实如果进行数据加工和数据治理,对于模型效果会有很大的提升。因此我们要考虑最终想要解决的场景要具备高价值,同时也要关注投入的资源在哪里,是在图谱的构建,还是在大模型的优化。如果没有这些考虑,那么产品将很容易被取代或挑战。

上图展示的是云问科技的一款设备生命周期管理产品。这类场景通过轻量化中间模块,通过不同场景进行上层应用搭建实现。这些模块的生命力远比知识图谱系统本身的生命力更旺盛。单卖或只卖中间件在图谱领域并不适用,尤其在工业场景中。很多工业问题在客户视角上看是很复杂的问题,图谱和大模型都无法解决。我们需要做的是从效果说服客户。

在工业智改数转过程中,研发设计、生产管理、供应管理、售前营销和综合服务中都有很多应用点。

上图是故障设备图谱的应用场景举例。在这个场景中我们并没有把所有图谱元素加入其中,比如设备运行状态和关系型数据库中的简单数据。我们认为对于设备维修来说,主要关注三类数据,第一类是设备基本信息,比如出厂时间,生产厂家,投入运行多久;第二类是故障,比如故障的名称、上下级,此类故障会导致什么缺陷,什么缺陷会导致哪类故障等;第三类是工单,描述在什么设备发生了什么故障。通过这三种数据的连接,我们可以构建一个小型闭环的图谱。未来也可以根据动态数据进行延伸。所以在构建图谱时,我们更倾向于去做一个小而美的、场景可闭环的图谱。而并非一味追求量级的高大上,但却无法满足消费端需求的图谱。
因此在构建工业知识图谱时,要从具体场景着手,通过分析场景需求来构建图谱,才能实现更好地落地和应用。
以上是工业知识图谱进阶实战的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 大模型App腾讯元宝上线!混元再升级,打造可随身携带的全能AI助理
Jun 09, 2024 pm 10:38 PM
大模型App腾讯元宝上线!混元再升级,打造可随身携带的全能AI助理
Jun 09, 2024 pm 10:38 PM
5月30日,腾讯宣布旗下混元大模型全面升级,基于混元大模型的App“腾讯元宝”正式上线,苹果及安卓应用商店均可下载。相比此前测试阶段的混元小程序版本,面向工作效率场景,腾讯元宝提供了AI搜索、AI总结、AI写作等核心能力;面向日常生活场景,元宝的玩法也更加丰富,提供了多个特色AI应用,并新增了创建个人智能体等玩法。“腾讯做大模型不争一时之先。”腾讯云副总裁、腾讯混元大模型负责人刘煜宏表示:“过去的一年,我们持续推进腾讯混元大模型的能力爬坡,在丰富、海量的业务场景中打磨技术,同时洞察用户的真实需求
 字节跳动豆包大模型发布,火山引擎全栈 AI 服务助力企业智能化转型
Jun 05, 2024 pm 07:59 PM
字节跳动豆包大模型发布,火山引擎全栈 AI 服务助力企业智能化转型
Jun 05, 2024 pm 07:59 PM
火山引擎总裁谭待企业要做好大模型落地,面临模型效果、推理成本、落地难度的三大关键挑战:既要有好的基础大模型做支撑,解决复杂难题,也要有低成本的推理服务让大模型被广泛应用,还要更多工具、平台和应用帮助企业做好场景落地。——谭待火山引擎总裁01.豆包大模型首次亮相大使用量打磨好模型模型效果是AI落地最关键的挑战。谭待指出,只有大的使用量,才能打磨出好模型。目前,豆包大模型日均处理1,200亿tokens文本、生成3,000万张图片。为助力企业做好大模型场景落地,字节跳动自主研发的豆包大模型将通过火山
 揭秘NVIDIA大模型推理框架:TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
揭秘NVIDIA大模型推理框架:TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
一、TensorRT-LLM的产品定位TensorRT-LLM是NVIDIA为大型语言模型(LLM)开发的可扩展推理方案。它基于TensorRT深度学习编译框架构建、编译和执行计算图,并借鉴了FastTransformer中高效的Kernels实现。此外,它还利用NCCL实现设备间的通信。开发者可以根据技术发展和需求差异,定制算子以满足特定需求,例如基于cutlass开发定制的GEMM。TensorRT-LLM是NVIDIA官方推理方案,致力于提供高性能并不断完善其实用性。TensorRT-LL
 工业知识图谱进阶实战
Jun 13, 2024 am 11:59 AM
工业知识图谱进阶实战
Jun 13, 2024 am 11:59 AM
一、背景简介首先来介绍一下云问科技的发展历程。云问科技公...2023年,正是大模型盛行的时期,很多企业认为已经大模型之后图谱的重要性大大降低了,之前研究的预置的信息化系统也都不重要了。不过随着RAG的推广、数据治理的盛行,我们发现更高效的数据治理和高质量的数据是提升私有化大模型效果的重要前提,因此越来越多的企业开始重视知识建设的相关内容。这也推动了知识的构建和加工开始向更高水平发展,其中有很多技巧和方法可以挖掘。可见一个新技术的出现,并不是将所有的旧技术打败,也有可能将新技术和旧技术相互融合后
 对标GPT-4!中国移动九天大模型通过双备案
Apr 04, 2024 am 09:31 AM
对标GPT-4!中国移动九天大模型通过双备案
Apr 04, 2024 am 09:31 AM
4月4日消息,日前,国家网信办公布已备案大模型清单,中国移动“九天自然语言交互大模型”名列其中,标志着中国移动九天AI大模型可正式对外提供生成式人工智能服务。中国移动表示,这是同时通过国家“生成式人工智能服务备案”和“境内深度合成服务算法备案”双备案的首个央企研发的大模型。据介绍,九天自然语言交互大模型具有行业能力增强、安全可信、支持全栈国产化等特点,已形成90亿、139亿、570亿、千亿等多种参数量版本,可灵活部署于云、边、端不同场
 GPT Store都开不下去,这家国产平台怎么敢走这条路的??
Apr 19, 2024 pm 09:30 PM
GPT Store都开不下去,这家国产平台怎么敢走这条路的??
Apr 19, 2024 pm 09:30 PM
注意看,这个男人把超1000种大模型接入,让你可插拔无缝切换使用。最近还上线了可视化的AI工作流:给你一个直观的拖放界面,拖拖、拉拉、拽拽,就能在无限画布上编排自己个儿的Workflow。正所谓兵贵神速,量子位听说,这个AIWorkflow上线不到48小时,就已经有用户配出了100多个节点的个人工作流。不卖关子,今天要聊的就是LLMOps公司Dify,及其CEO张路宇。张路宇也是Dify的创始人。投身创业前,有11年的互联网从业经验。搞产品设计,懂项目管理,也对SaaS有点自己的独到见解。后来他
 新测试基准发布,最强开源Llama 3尴尬了
Apr 23, 2024 pm 12:13 PM
新测试基准发布,最强开源Llama 3尴尬了
Apr 23, 2024 pm 12:13 PM
如果试题太简单,学霸和学渣都能考90分,拉不开差距……随着Claude3、Llama3甚至之后GPT-5等更强模型发布,业界急需一款更难、更有区分度的基准测试。大模型竞技场背后组织LMSYS推出下一代基准测试Arena-Hard,引起广泛关注。Llama3的两个指令微调版本实力到底如何,也有了最新参考。与之前大家分数都相近的MTBench相比,Arena-Hard区分度从22.6%提升到87.4%,孰强孰弱一目了然。Arena-Hard利用竞技场实时人类数据构建,与人类偏好一致率也高达89.1%
 利用升腾AI技术,秦岭·秦川交通大模型助力西安打造智慧交通创新中心
Oct 15, 2023 am 08:17 AM
利用升腾AI技术,秦岭·秦川交通大模型助力西安打造智慧交通创新中心
Oct 15, 2023 am 08:17 AM
“高度复杂、碎片化程度高、跨领域”一直是交通行业数智化升级路上的首要痛点。近日,由中科视语、西安市雁塔区政府、西安未来人工智能计算中心联合打造的参数规模千亿级的“秦岭·秦川交通大模型”,面向智慧交通领域,为西安及其周边地区打造智慧交通创新支点。 “秦岭·秦川交通大模型”结合西安当地海量开放场景下的交通生态数据、中科视语自研的原创先进算法以及西安未来人工智能计算中心升腾AI的强大算力,为路网监测、应急指挥、养护管理、公众出行等智慧交通全场景带来数智化变革。交通管理在不同城市有不同的特点,不同道路的交
