
在软件技术的前沿,UIUC张令明组携手BigCode组织的研究者,近日公布了StarCoder2-15B-Instruct代码大模型。
这一创新成果在代码生成任务取得了显着突破,成功超越CodeLlama-70B-Instruct,登上代码生成性能榜单之巅。

StarCoder2-15B-Instruct的独特之处在于其纯自对齐策略,整个训练流程公开透明,且完全自主可控。
该模型通过StarCoder2-15B生成了数千个指令,响应对StarCoder-15B基座模型进行微调,无需依赖昂贵的人工标注数据,也无需从GPT4等商业大模型中获取数据,避免了潜在的版权问题。
在HumanEval测试中,StarCoder2-15B-Instruct以72.6%的Pass@1成绩脱颖而出,较CodeLlama-70B-Instruct的72.0%有所提升。
在LiveCodeBench数据集的评估中,这一自对齐模型的表现甚至超过了基于GPT-4生成数据训练的同类模型。这一成果证明了通过自身分布内的数据,大模型同样能够有效地学习如何与人类类似对齐,而无需依赖外部教师大模型的偏移分布。
该项目的成功实施得到了美国东北大学Arjun Guha课题组、加州大学伯克利分校、ServiceNow和Hugging Face等机构的鼎力支持。
StarCoder2-Instruct的数据生成流程主要包括三个核心步骤:
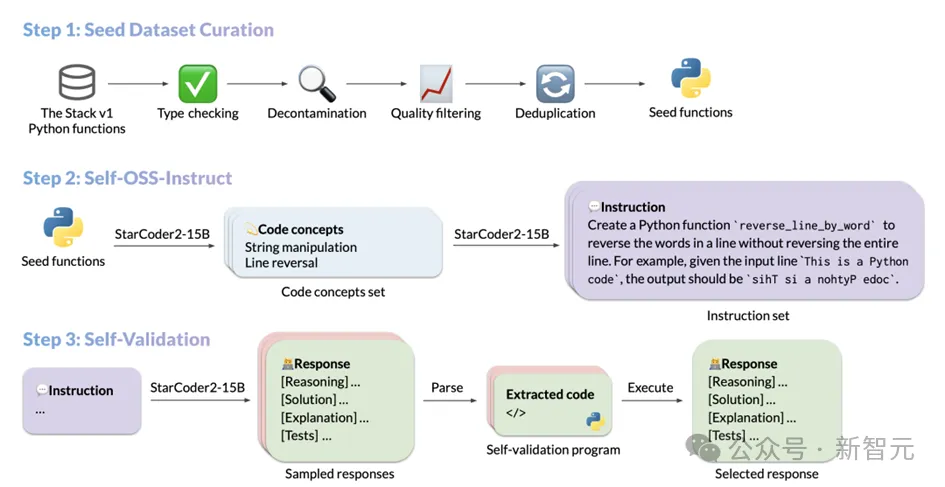
1. 种子代码片段的采集:团队从The Stack v1中筛选出高质量、多样化的种子函数,这些函数来自海量的获得许可的源代码语料库。通过严格的过滤和筛选,确保了种子代码的质量和多样性;
2. 多样化指令的生成:基于种子函数中的不同编程概念,StarCoder2-15B-Instruct能够创建出多样化且真实的代码指令。这些指令涵盖了从数据反序列化到列表连接、递归等丰富的编程场景;
3. 高质量响应的生成:对于每个指令,模型采用编译运行引导的自我验证方式,确保生成的响应是准确且高质量的。
每个步骤的具体操作如下:
为了提升代码模型在遵循指令方面的能力,模型需要广泛接触和学习不同的编程原理与实际操作。 StarCoder2-15B-Instruct受到OSS-Instruct的启发,从开源代码片段中汲取灵感,尤其是The Stack V1中那些格式规范、结构清晰的Python种子函数。
在构建其基础数据集时,StarCoder2-15B-Instruct对The Stack V1进行了深度挖掘,选取了所有配备文档说明的Python函数,并借助autoimport功能自动分析并推断了这些函数所需的依赖项。
为了确保数据集的纯净性和高质量,StarCoder2-15B-Instruct对所有选取的函数进行了精细的过滤和筛选。
首先,通过Pyright类型检查器进行严格的类型检查,排除了所有可能产生静态错误的函数,从而保证了数据的准确性和可靠性。
接着,通过精确的字符串匹配技术,识别和剔除了与评估数据集存在潜在关联的代码和提示,以避免数据污染。在文档质量方面,StarCoder2-15B-Instruct更是采用了独特的筛选机制。
它利用自身的评估能力,通过向模型展示7个样本提示,让模型自行判断每个函数的文档质量是否达标,从而决定是否将其纳入最终的数据集。
这种基于模型自我判断的方法,不仅提高了数据筛选的效率和准确性,也确保了数据集的高质量和一致性。
最后,为了避免数据冗余和重复,StarCoder2-15B-Instruct采用了MinHash和局部敏感哈希算法,对数据集中的函数进行了去重处理。通过设定0.5的Jaccard相似度阈值,有效去除了相似度较高的重复函数,确保了数据集的独特性和多样性。
经过这一系列的精细筛选和过滤,StarCoder2-15B-Instruct最终从500万个带有文档的Python函数中,精选出了25万个高质量的函数作为其种子数据集。这一方法深受MultiPL-T数据收集流程的启发。
当StarCoder2-15B-Instruct完成了种子函数的收集后,它运用了Self-OSS-Instruct技术来创造多样化的编程指令。这一技术的核心在于通过上下文学习,让StarCoder2-15B基座模型能够自主地为给定的种子代码片段生成相应的指令。
为实现这一目标,StarCoder2-15B-Instruct精心设计了16个范例,每个范例都遵循(代码片段,概念,指令)的结构。指令的生成过程被细分为两个阶段:
代码概念识别:在这一阶段,StarCoder2-15B会针对每一个种子函数进行深入分析,并生成一个包含该函数中关键代码概念的列表。这些概念广泛涵盖了编程领域的基本原理和技术,如模式匹配、数据类型转换等,这些对于开发者而言具有极高的实用价值。
指令创建:基于识别出的代码概念,StarCoder2-15B会进一步生成与之对应的编码任务指令。这一过程旨在确保生成的指令能够准确地反映代码片段的核心功能和要求。
通过上述流程,StarCoder2-15B-Instruct最终成功生成了高达238k个指令,极大地丰富了其训练数据集,并为其在编程任务中的表现提供了强有力的支持。
在获取Self-OSS-Instruct生成的指令后,StarCoder2-15B-Instruct的关键任务是为每个指令匹配高质量的响应。
传统上,人们倾向于依赖如GPT-4等更强大的教师模型来获取这些响应,但这种方式不仅可能面临版权许可的难题,而且外部模型并非总是触手可及或准确无误。更重要的是,依赖外部模型可能引入教师与学生之间的分布差异,这可能会影响到最终结果的准确性。
为了克服这些挑战,StarCoder2-15B-Instruct引入了一种自我验证机制。这一机制的核心思想是,让StarCoder2-15B模型在生成自然语言响应后,自行创建对应的测试用例。这一过程类似于开发人员编写代码后的自测流程。
具体而言,对于每一个指令,StarCoder2-15B会生成10个包含自然语言响应和对应测试用例的样本。随后,StarCoder2-15B-Instruct会在一个沙盒环境中执行这些测试用例,以验证响应的有效性。任何在执行测试中失败的样本都会被过滤掉。
经过这一严格的筛选过程,StarCoder2-15B-Instruct会从每个指令的通过测试的响应中随机选取一个,加入最终的SFT数据集。整个过程中,StarCoder2-15B-Instruct为238k个指令生成了总计240万个响应样本(每个指令10个样本)。在采用0.7的采样策略后,有50万个样本成功通过了执行测试。
为了确保数据集的多样性和质量,StarCoder2-15B-Instruct还进行了去重处理。最终,剩下5万个指令,每个指令都配有一个随机选取的、经过测试验证的高质量响应。这些响应构成了StarCoder2-15B-Instruct最终的SFT数据集,为模型的后续训练和应用提供了坚实的基础。
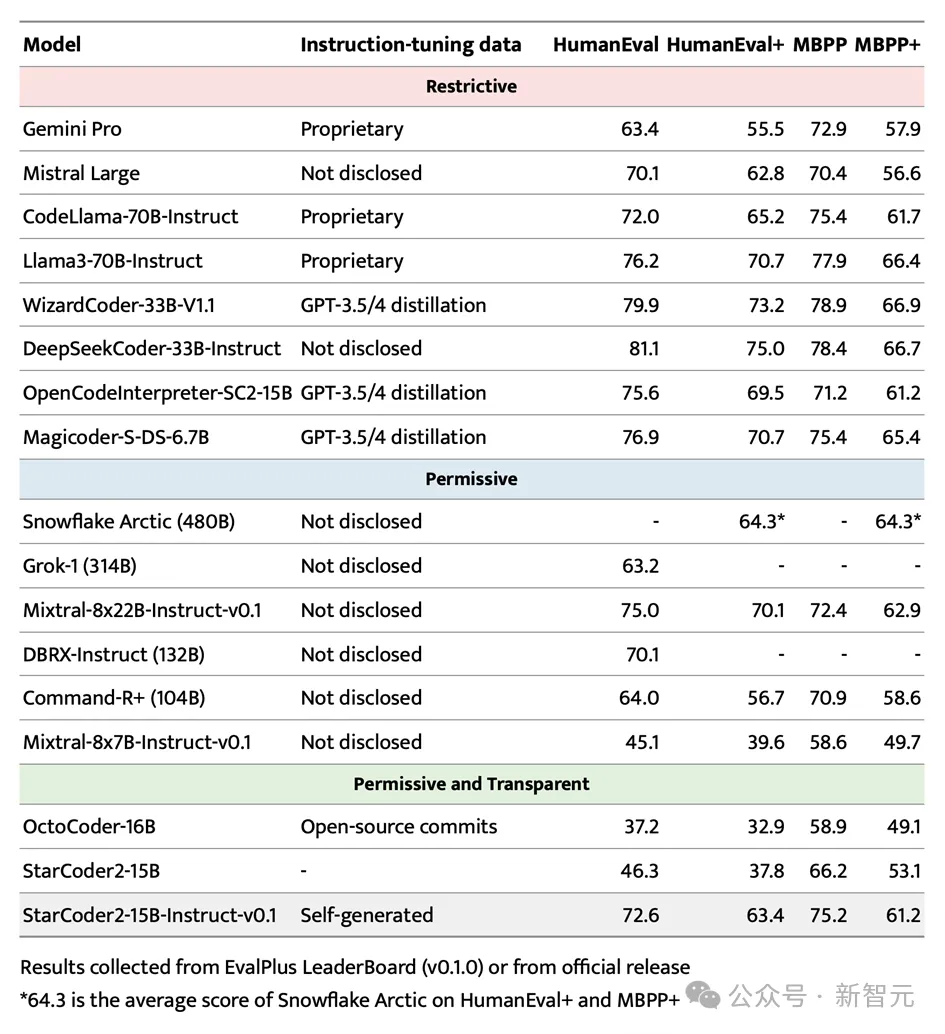
在备受瞩目的EvalPlus基准测试中,StarCoder2-15B-Instruct凭借其规模化优势,成功脱颖而出,成为表现最出色的自主可控大型模型。
它不仅超越了规模更大的Grok-1 Command-R+和DBRX,还与Snowflake Arctic 480B和Mixtral-8x22B-Instruct等业界翘楚性能相当。
值得一提的是,StarCoder2-15B-Instruct是首个在HumanEval基准上达到70+得分的自主代码大模型,其训练过程完全透明,数据和方法的使用均符合法律法规。
在自主可控代码大模型领域,StarCoder2-15B-Instruct显着超越了之前的佼佼者OctoCoder,证明了其在该领域的领先地位。
即便与拥有限制性许可的大型强力模型如Gemini Pro和Mistral Large相比,StarCoder2-15B-Instruct依然展现出卓越的性能,并与CodeLlama-70B-Instruct平分秋色。更令人瞩目的是,StarCoder2-15B-Instruct完全依赖于自生成数据进行训练,其性能却能与基于GPT-3.5/4数据微调的OpenCodeInterpreter-SC2-15B相媲美。
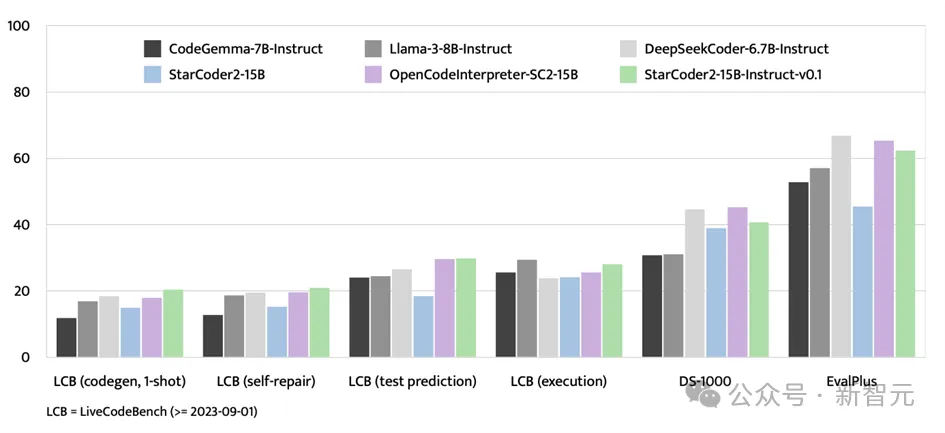
除了EvalPlus基准测试,StarCoder2-15B-Instruct在LiveCodeBench和DS-1000等评估平台上也展现出了强大的实力。
LiveCodeBench专注于评估2023年9月1日之后出现的编码挑战,而StarCoder2-15B-Instruct在该基准测试中取得了最优成绩,并且始终领先于使用GPT-4数据进行微调的OpenCodeInterpreter-SC2-15B
尽管DS-1000专注于数据科学任务,StarCoder2-15B-Instruct在训练数据中涉及的数据科学问题相对较少,但其在该基准测试中的表现依然强劲,显示出广泛的适应性和竞争力。
StarCoder2-15B-Instruct-v0.1的发布,标志着研究者们在代码模型自我调优领域迈出了重要一步。这款模型的成功实践,打破了以往必须依赖如GPT-4等强大外部教师模型的限制,展示了通过自我调优同样能够构建出性能卓越的代码模型。
StarCoder2-15B-Instruct-v0.1的核心在于其自我对齐策略在代码学习领域的成功应用。这一策略不仅提升了模型的性能,更重要的是,它赋予了模型更高的透明度和可解释性。这一点与Snowflake-Arctic、Grok-1、Mixtral-8x22B、DBRX和CommandR+等其他大型模型形成了鲜明对比,这些模型虽然强大,但往往因缺乏透明度而限制了其应用范围和可信赖度。
更令人欣喜的是,StarCoder2-15B-Instruct-v0.1已经将其数据集和整个训练流程——包括数据收集和训练过程——完全开源。这一举措不仅彰显了研究者的开放精神,也为未来该领域的研究和发展奠定了坚实的基础。
有理由相信,StarCoder2-15B-Instruct-v0.1的成功实践将激发更多研究者投入到代码模型自我调优领域的研究中,推动该领域的技术进步和应用拓展。同时,也期待这一领域的更多创新成果能够不断涌现,为人类社会的智能化发展注入新的动力。
UIUC的张令明老师是一位在软件工程、程序语言和机器学习交叉领域具有深厚造诣的学者。他领导的课题组长期致力于基于AI大模型的自动软件合成、修复和验证研究,以及机器学习系统的可靠性提升。
近期,团队发布了多个创新性的代码大模型和测试基准数据集,并率先提出了一系列基于大模型的软件测试和修复技术。同时,在多个真实软件系统中成功挖掘出上千个新缺陷和漏洞,为提升软件质量做出了显着贡献。
以上是无需OpenAI数据,跻身代码大模型榜单!UIUC发布StarCoder-15B-Instruct的详细内容。更多信息请关注PHP中文网其他相关文章!






















