在刚刚结束的全球开发者大会上,苹果宣布了 Apple intelligence, 这是一款深度集成于 iOS 18、iPadOS 18 和 macOS Sequoia 的全新个性化智能系统。

苹果+智能由多种高度智能的生成模型组成,这些模型专为用户的日常任务设计。在苹果刚刚更新的博客中,他们详细介绍了其中两款模型。
一个拥有约 30 亿参数的设备端语言模型;
一个更大的基于服务器的语言模型,该模型通过私有云计算在苹果服务器上运行。
这两个基础模型是苹果生成模型家族的一部分,苹果表示,他们会在不久的将来分享更多关于这一模型家族的信息。
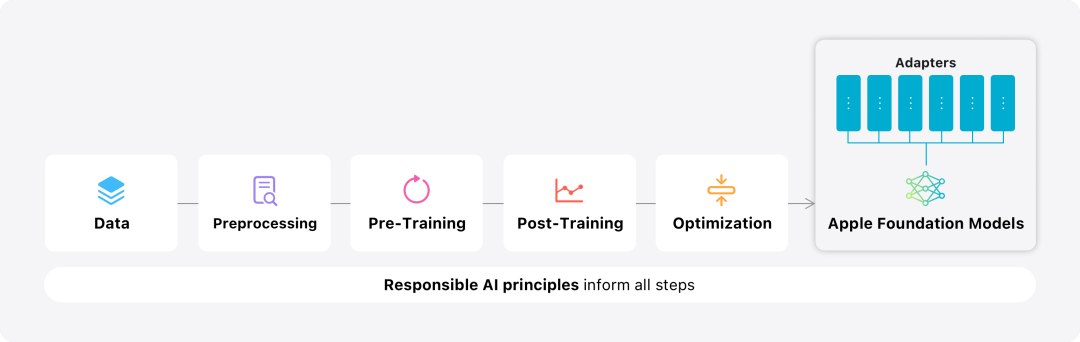
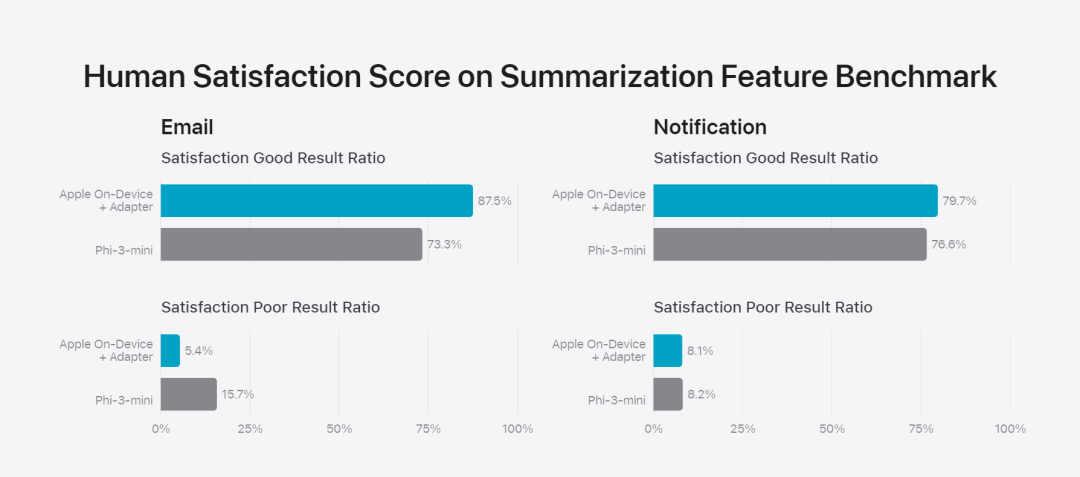
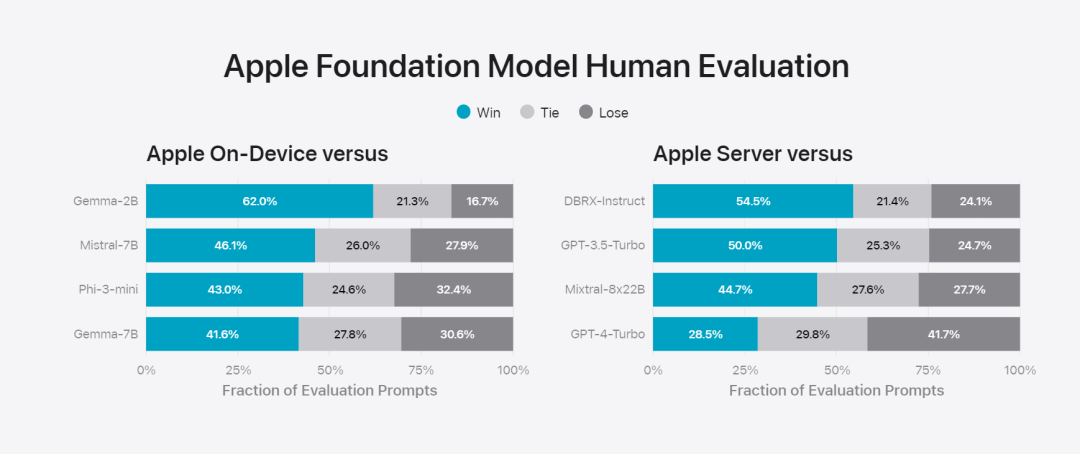
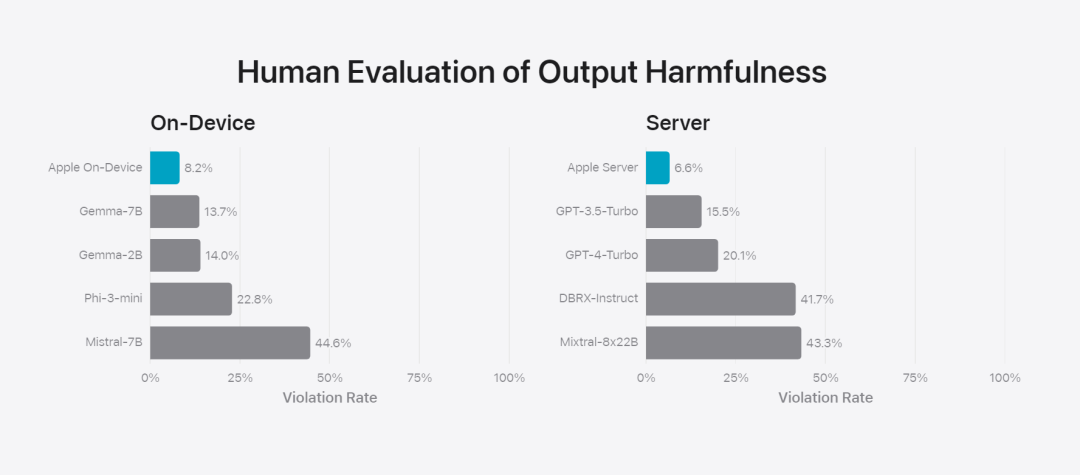
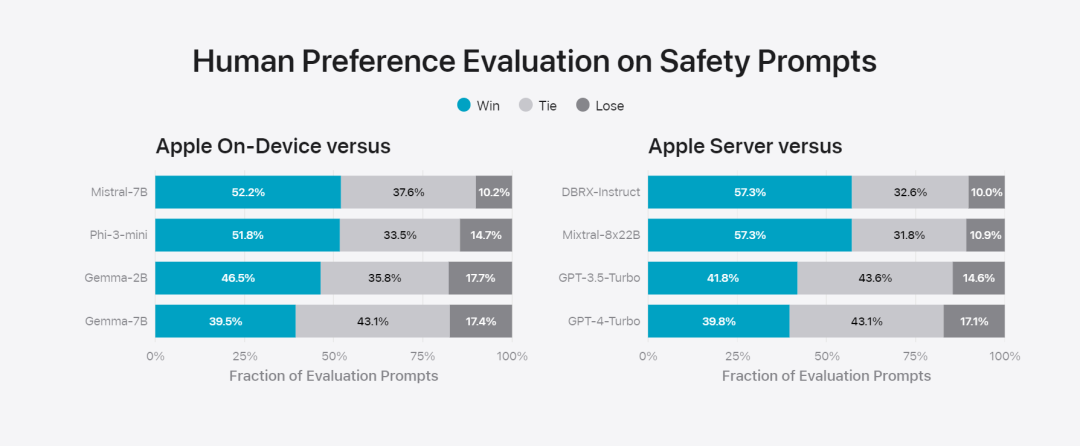
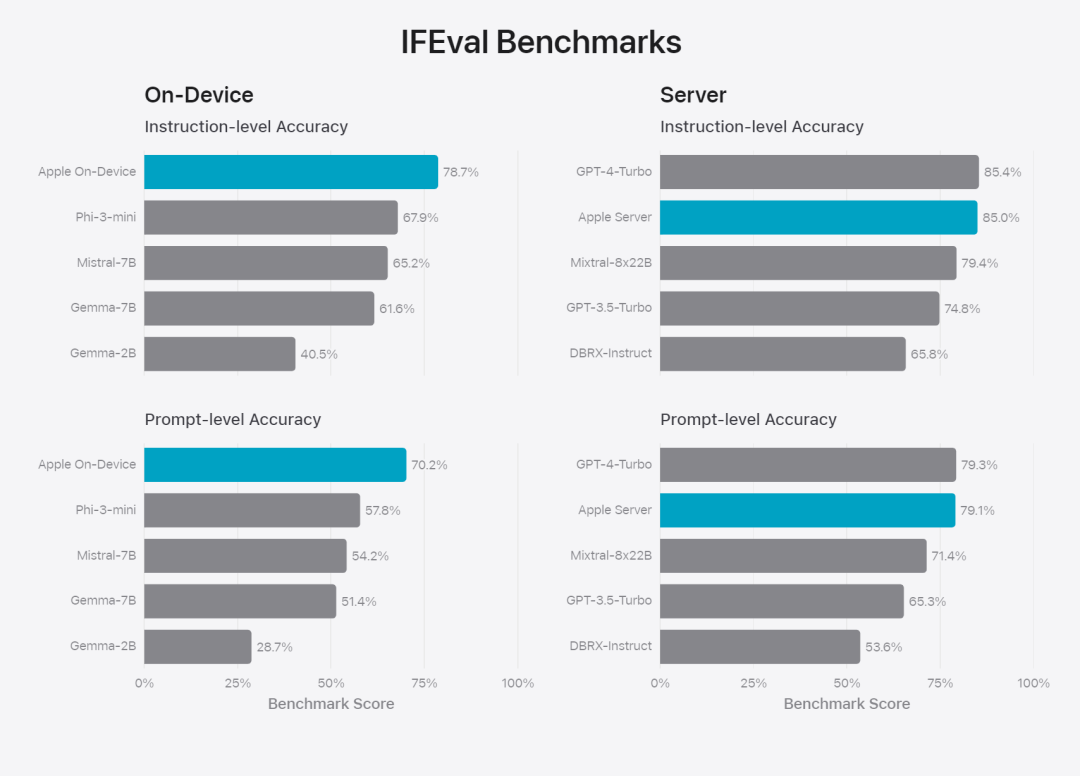
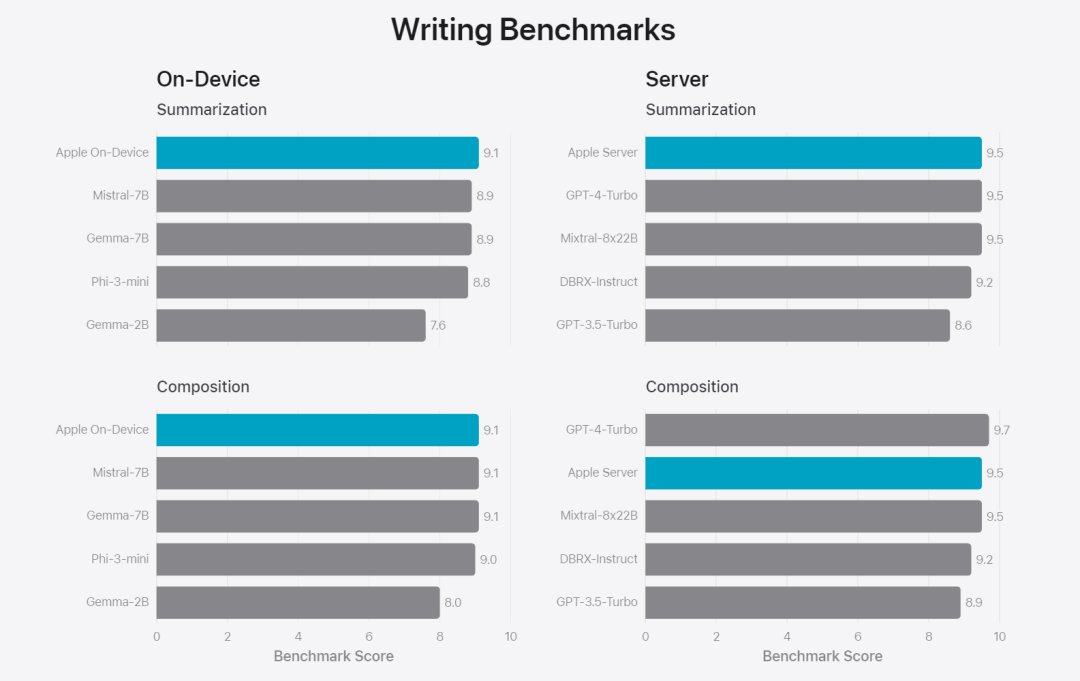
在这篇博客中,苹果用大量篇幅介绍了他们是如何开发高性能、快速且节能的模型;如何进行这些模型的训练;如何为特定用户需求微调适配器;以及如何评估模型在提供帮助和避免意外伤害方面的表现。 基础模型是在 AXLearn 框架上训练而成的,这是苹果在 2023 年发布的一个开源项目。该框架建立在 JAX 和 XLA 之上,使得用户能够在各种硬件和云平台上高效且可扩展地训练模型,包括 TPU 以及云端和本地的 GPU。此外,苹果使用数据并行、张量并行、序列并行和 FSDP 等技术,沿着多个维度(如数据、模型和序列长度)扩展训练。苹果在训练其基础模型时,使用了经过授权的数据,这些数据包括为了增强某些特定功能而特别选择的数据,以及由苹果的网页爬虫 AppleBot 从公开的网络上收集的数据。网页内容的发布者可以通过设置数据使用控制,选择不让他们的网页内容被用来训练 Apple Intelligence。 苹果在训练其基础模型时,从不使用用户的私人数据。为了保护隐私,他们会使用过滤器去除公开在互联网上的个人可识别信息,比如信用卡号码。此外,他们还会过滤掉粗俗语言和其他低质量的内容,以防这些内容进入训练数据集。除了这些过滤措施之外,Apple 还会进行数据提取和去重,并使用基于模型的分类器来识别并选择高质量的文档用于训练。 苹果发现数据质量对模型至关重要,因此在训练流程中采用了混合数据策略,即人工标注数据和合成数据,并进行全面的数据管理和过滤程序。苹果在后训练阶段开发了两种新算法:(1) 带有「teacher committee」的拒绝采样微调算法,(2) 使用带有镜像下降策略优化以及留一优势估计器的从人类反馈中进行强化学习(RLHF)算法。这两种算法显著提高了模型的指令跟随质量。 除了保证生成模型本身的高性能,Apple 还采用了多种创新技术,在设备端和私有云上对模型进行优化,以提升速度和效率。特别是,他们对模型在生成第一个 token(单个字符或词语的基本单位)和后续 token 的推理过程都进行了大量优化,以确保模型的快速响应和高效运行。 苹果在设备端模型和服务器模型中都采用了分组查询注意力机制,以提高效率。为了减少内存需求和推理成本,他们使用了共享的输入和输出词汇嵌入表,这些表在映射时没有重复。设备端模型的词汇量为 49,000,而服务器模型的词汇量为 100,000。对于设备端推理,苹果使用了低位 palletization,这是一个关键的优化技术,能够满足必要的内存、功耗和性能要求。为了保持模型质量,苹果还开发了一个新的框架,使用 LoRA 适配器,结合了混合的 2 位和 4 位配置策略 —— 平均每个权重 3.5 位 —— 以实现与未压缩模型相同的准确率。 此外,苹果还使用交互式模型延迟和功耗分析工具 Talaria,以及激活量化和嵌入量化,并开发了一种在神经引擎上实现高效键值 (KV) 缓存更新的方法。通过这一系列优化,在 iPhone 15 Pro 上, 当模型接收到一个提示词时,从接收到这个提示词到生成第一个 token 所需的时间约为 0.6 毫秒,这个延迟时间非常短,表明模型在生成响应时非常快速生成速率为每秒 30 个 token。苹果将基础模型针对用户的日常活动进行了微调,并且可以动态地专门针对当前的任务。研究团队利用适配器(可以插入预训练模型各个层的小型神经网络模块)来针对特定任务微调模型。具体来说,研究团队调整了注意力矩阵、注意力投影矩阵和逐点(point-wise)前馈网络中的全连接层。通过仅微调适配器层,预训练基础模型的原始参数保持不变,保留模型的一般知识,同时定制适配器层以支持特定任务。图 2:适配器是覆盖在公共基础模型上的模型权重的小型集合。它们可以动态加载和交换 —— 使基础模型能够动态地专门处理当前的任务。Apple Intelligence 包括一组广泛的适配器,每个适配器都针对特定功能进行了微调。这是扩展其基础模型功能的有效方法。研究团队使用 16 bit 表征适配器参数的值,对于约 30 亿参数的设备模型,16 适配器的参数通常需要 10 兆字节。适配器模型可以动态加载、临时缓存在内存中以及交换。这使基础模型能够动态地专门处理当前的任务,同时有效地管理内存并保证操作系统的响应能力。为了促进适配器的训练,苹果创建了一个高效的基础设施,以在基本模型或训练数据更新时快速重新训练、测试和部署适配器。苹果在对模型进行基准测试时,专注于人类评估,因为人类评估的结果与产品的用户体验高度相关。为了评估特定于产品的摘要功能,研究团队使用了针对每个用例仔细采样的一组 750 个响应。评估数据集强调产品功能在生产中可能面临的各种输入,并包括不同内容类型和长度的单个文档和堆叠文档的分层混合。实验结果发现带有适配器的模型能够比类似模型生成更好的摘要。作为负责任开发的一部分,苹果识别并评估了摘要固有的特定风险。例如,摘要有时会删除重要的细微差别或其他细节。然而,研究团队发现摘要适配器没有放大超过 99% 的目标对抗样本中的敏感内容。除了评估基础模型和适配器支持的特定功能之外,研究团队还评估了设备上模型和基于服务器的模型的一般功能。具体来说,研究团队采用一组全面的现实世界 prompt 来测试模型功能,涵盖了头脑风暴、分类、封闭式问答、编码、提取、数学推理、开放式问答、重写、安全、总结和写作等任务。研究团队将模型与开源模型(Phi-3、Gemma、Mistral、DBRX)和规模相当的商业模型(GPT-3.5-Turbo、GPT-4-Turbo)进行比较。结果发现,与大多数同类竞争模型相比,苹果的模型更受人类评估者青睐。例如,苹果的设备上模型具有约 3B 参数,其性能优于较大的模型,包括 Phi-3-mini、Mistral-7B 和 Gemma-7B;服务器模型与 DBRX-Instruct、Mixtral-8x22B 和 GPT-3.5-Turbo 相比毫不逊色,同时效率很高。 图 4:苹果基础模型与可比较模型的评估中首选响应比例。研究团队还使用一组不同的对抗性 prompt 来测试模型在有害内容、敏感主题和事实方面的性能,测量了人类评估者评估的模型违规率,数字越低越好。面对对抗性 prompt,设备上模型和服务器模型都很强大,其违规率低于开源和商业模型。 图 5:有害内容、敏感主题和事实性的违规响应比例(越低越好)。当面对对抗性 prompt 时,苹果的模型非常稳健。考虑到大型语言模型的广泛功能,苹果正在积极与内部和外部团队进行手动和自动红队合作,以进一步评估模型的安全性。 图 6:在安全 prompt 方面,苹果基础模型与同类模型的并行评估中首选响应的比例。人类评估者发现苹果基础模型的响应更安全、更有帮助。为了进一步评估模型,研究团队使用指令跟踪评估 (IFEval) 基准来将其指令跟踪能力与同等大小的模型进行比较。结果表明,设备上模型和服务器模型都比同等规模的开源模型和商业模型更好地遵循详细指令。 图 7:苹果基础模型和类似规模模型的指令跟踪能力(使用 IFEval 基准)。最后,我们看一下苹果对于 Apple Intelligence 背后技术的介绍视频。参考链接:https://machinelearning.apple.com/research/introducing-apple-foundation-models 以上是苹果智能背后模型公布:3B模型优于Gemma-7B,服务器模型媲美GPT-3.5-Turbo的详细内容。更多信息请关注PHP中文网其他相关文章!



 参考链接:https://machinelearning.apple.com/research/introducing-apple-foundation-models
参考链接:https://machinelearning.apple.com/research/introducing-apple-foundation-models 





















