AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本研究评估了先进多模态基础模型在10 个数据集上的多样本上下文学习,揭示了持续的性能提升。批量查询显着降低了每个示例的延迟和推理成本而不牺牲性能。这些发现表明:利用大量演示示例可以快速适应新任务和新领域,而无需传统的微调。 
- 论文地址:https://arxiv.org/abs/2405.09798
- 代码地址: https://github.com/stanfordmlgroup/ManyICL
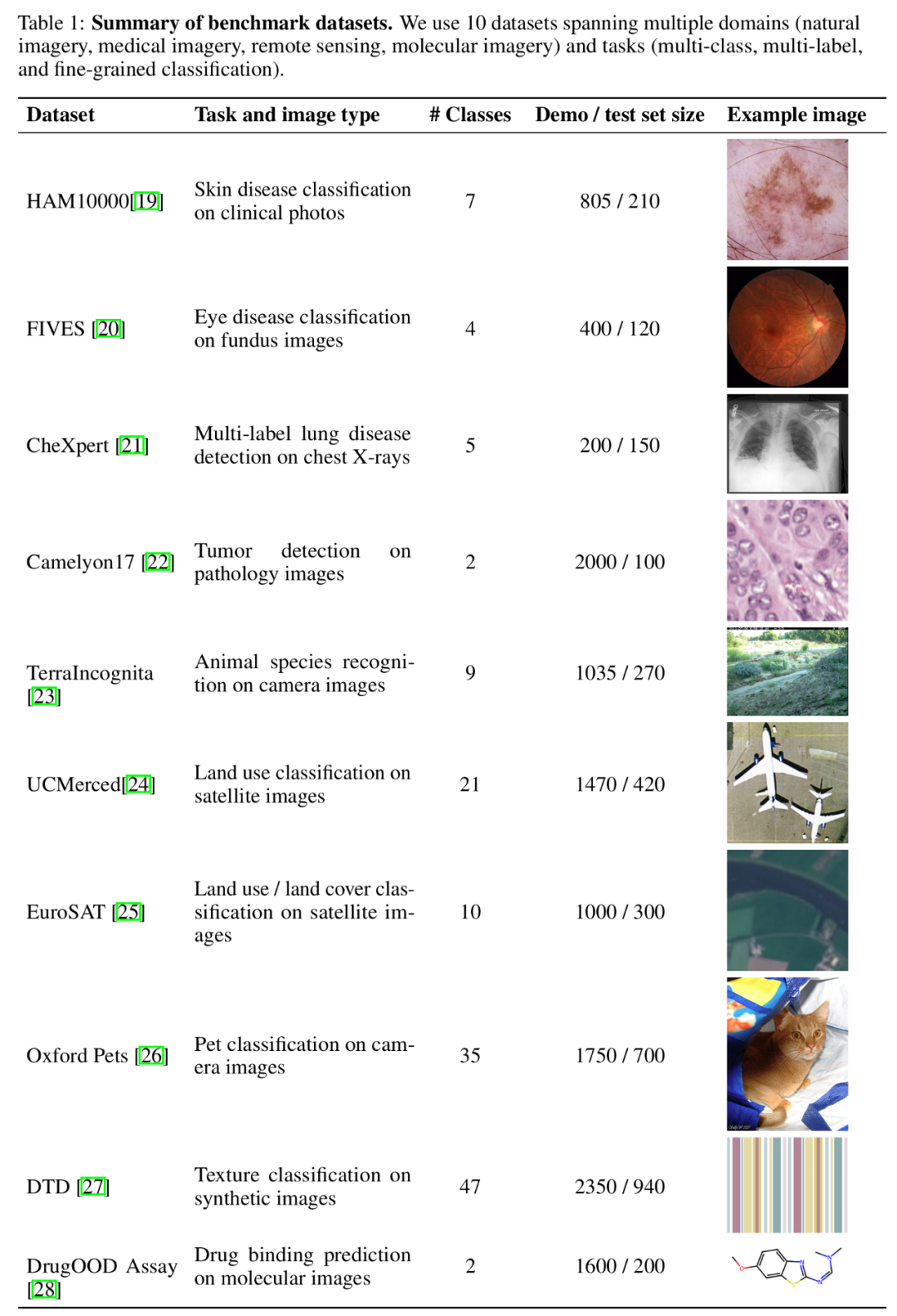
在近期的多模态基础模型(Multimodal Foundation Model)研究中,上下文学习(In-Context Learning, ICL)已被证明是提高模型性能的有效方法之一。 然而,受限于基础模型的上下文长度,尤其是对于需要大量视觉token 来表示图片的多模态基础模型,已有的相关研究只局限于在上下文中提供少量样本。 令人激动的是,最新的技术进步大大增加了模型的上下文长度,这为探索使用更多示例进行上下文学习提供了可能性。 基于此,斯坦福吴恩达团队的最新研究——ManyICL,主要评估了目前最先进的多模态基础模型在从少样本(少于100) 到多样本(最高至2000)上下文学习中的表现。通过对多个领域和任务的数据集进行测试,团队验证了多样本上下文学习在提高模型性能方面的显着效果,并探讨了批量查询对性能和成本及延迟的影响。 Many-shot ICL与零样本、少样本ICL的比较。 本研究选择了三种先进的多模态基础模型:GPT-4o、GPT4 (V)-Turbo 和Gemini 1.5 Pro。出于 GPT-4o 优越的表现,研究团队在正文中着重讨论 GPT-4o 和 Gemini 1.5 Pro, GPT4 (V)-Turbo 的相关内容请于附录中查看。 数据集方面,研究团队在10 个跨越不同领域(包括自然影像、医学影像、遥感影像和分子影像等)和任务(包括多分类、多标签分类和细粒度分类)的数据集上进行了广泛的实验。
基准数据集汇总。
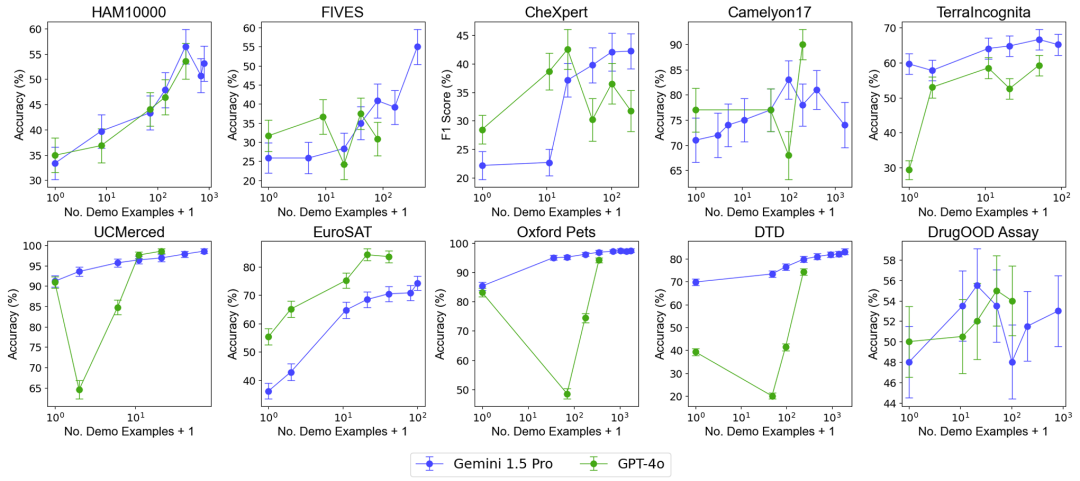
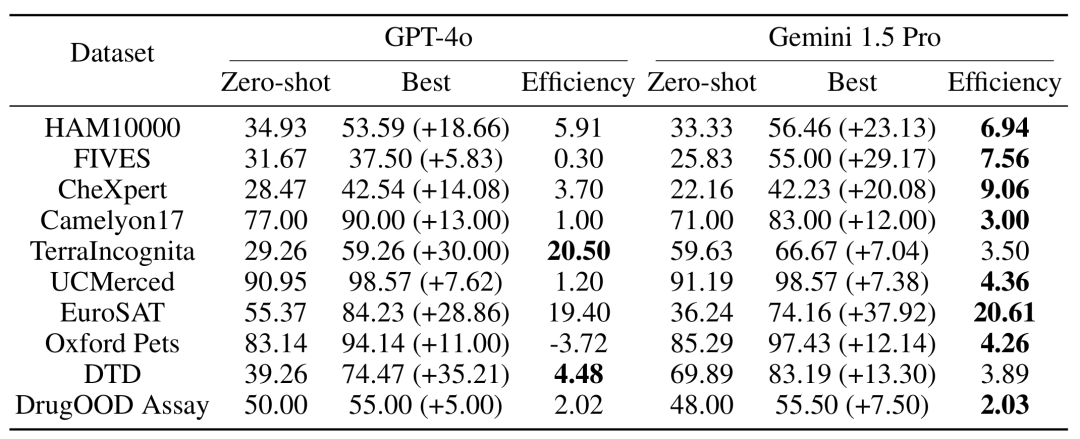
为了测试增加示例数量对模型性能的影响,研究团队逐步增加了上下文中提供的示例数量,最高达到近 2000 个示例。同时,考虑到多样本学习的高成本和高延迟,研究团队还探索了批量处理查询的影响。在这里,批量查询指的是在单次 API 调用中处理多个查询。总体表现:包含近 2000 个示例的多样本上下文学习在所有数据集上均优于少样本学习。随着示例数量的增加,Gemini 1.5 Pro 模型的性能呈现出持续的对数线性提升,而 GPT-4o 的表现则较不稳定。
数据效率:研究测量了模型的上下文学习数据效率,即模型从示例中学习的速度。结果表明,Gemini 1.5 Pro 在绝大部分数据集上显示出比 GPT-4o 更高的上下文学习数据效率,意味着它能够更有效地从示例中学习。
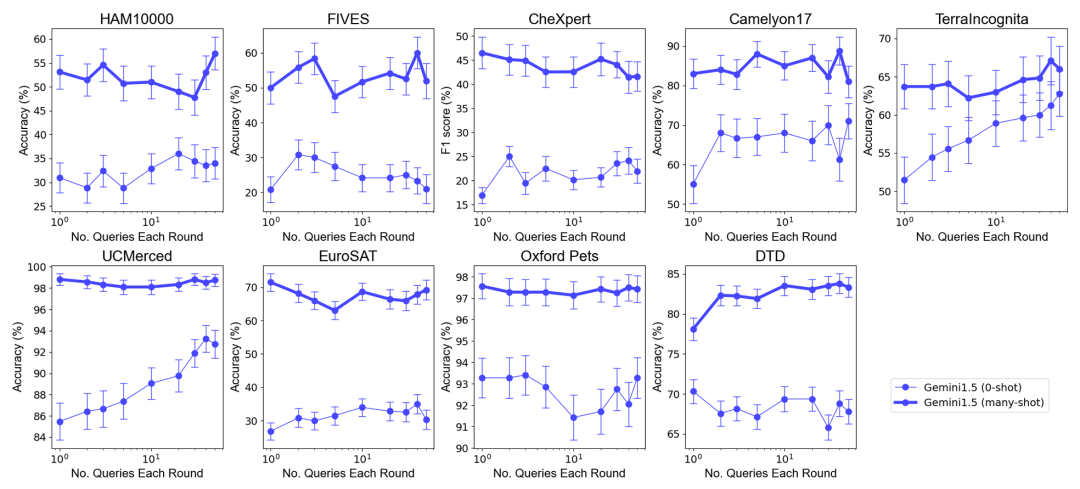
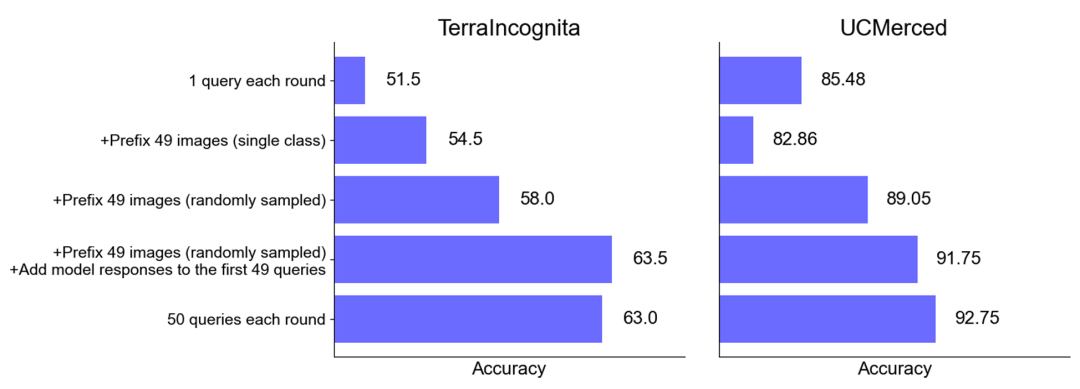
总体表现:在选择最优示例集大小下的零样本和多样本情境中,将多个查询合并为一次请求,不会降低性能。值得注意的是,在零样本场景中,单个查询在许多数据集上表现较差。相比之下,批量查询甚至可以提高性能。
零样本场景下的性能提升:对于某些数据集(如 UCMerced),批量查询在零样本场景下显著提高了性能。研究团队分析认为,这主要归因于领域校准 (domain calibration)、类别校准 (class calibration) 以及自我学习 (self-ICL)。
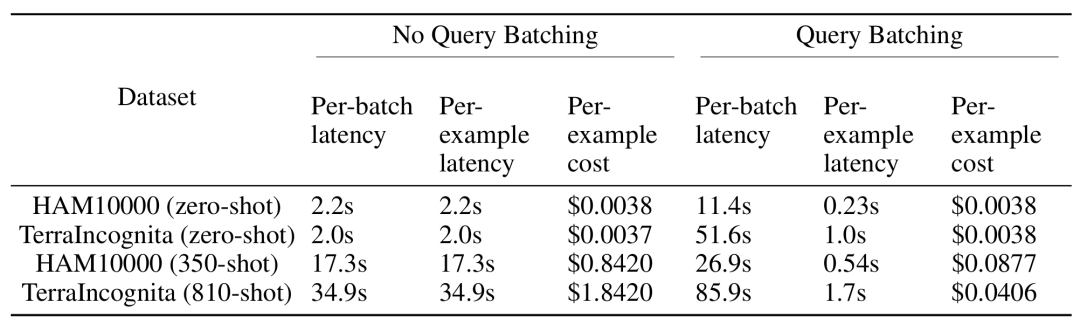
多样本上下文学习虽然在推理时需要处理更长的输入上下文,但通过批量查询可以显著降低每个示例的延迟和推理成本。例如,在 HAM10000 数据集中,使用 Gemini 1.5 Pro 模型进行 350 个示例的批量查询,延迟从 17.3 秒降至 0.54 秒,成本从每个示例 0.842 美元降至 0.0877 美元。
研究结果表明,多样本上下文学习能够显著提高多模态基础模型的表现,尤其是 Gemini 1.5 Pro 模型在多个数据集上表现出持续的性能提升,使其能够更有效地适应新任务和新领域,而无需传统的微调。其次,批量处理查询可以在相似甚至更好的模型表现的同时,降低推理成本和延迟,显示出在实际应用中的巨大潜力。总的来说,吴恩达团队的这项研究为多模态基础模型的应用开辟了新的路径,特别是在快速适应新任务和领域方面。以上是吴恩达团队新作:多模态多样本上下文学习,无需微调快速适应新任务的详细内容。更多信息请关注PHP中文网其他相关文章!