
分子描述符的应用与挑战
分子描述符广泛应用于分子建模。然而,在 AI 辅助分子发现领域,缺乏自然适用、完整且原始的分子表征,影响模型性能和可解释性。
t-SMILES 框架的提出
基于片段的多尺度分子表征框架 t-SMILES 解决分子表征问题。该框架使用 SMILES 类型的字符串描述分子,支持序列模型作为生成模型。
t-SMILES 的代码算法
t-SMILES 具有三种代码算法:TSSA、TSDY 和 TSID。
实验结果
实验表明,t-SMILES 模型生成分子具有 100% 理论有效性和高新颖性,优于基于 SOTA SMILES 的模型。
此外,t-SMILES 模型避免过拟合,在标记的低资源数据集上保持相似性,同时实现更高新颖性。
发表信息
该研究以「t-SMILES: a fragment-based molecular representation framework for de novo ligand design」为题,于 6 月 11 日发表在《Nature Communications》上。

基于 SMILES 的分子表征法研究
分子的有效表征是影响人工智能模型性能的关键因素。
图神经网络(GNN)因其能生成 100% 有效的分子而流行,但其表达能力受限。
简化分子线性输入规范(SMILES)作为一种线性表示法,易产生化学无效字符串。DeepSMILES 和 SELFIES 作为替代方案虽有所改进,但仍存在问题。
此外,研究表明语言模型 (LM) 在学习大型复杂分子方面可能优于大多数 GNN。最近,基于 Transformers 的 LM 已经展示了它们生成与人类书写极为相似的文本的能力。
受这些想法启发,研究者选择 SMILES 作为片段描述的起始选择,并结合先进的自然语言处理技术来处理基于片段的分子建模任务,这可以融合图模型更注重分子拓扑结构和 LM 的强大学习能力的优势。
生成 100% 有效的新分子,优于 SOTA
因此,湖南大学团队提出了一种基于碎片化分子的新型分子描述框架 t-SMILES(基于树的 SMILES)。该框架包含三种 t-SMILES 编码算法:TSSA(具有共享原子的 t-SMILES),TSDY(具有虚拟原子但不具有 ID 的 t-SMILES)和 TSID(具有 ID 和虚拟原子的 t-SMILES)。

新提出的 t-SMILES 框架
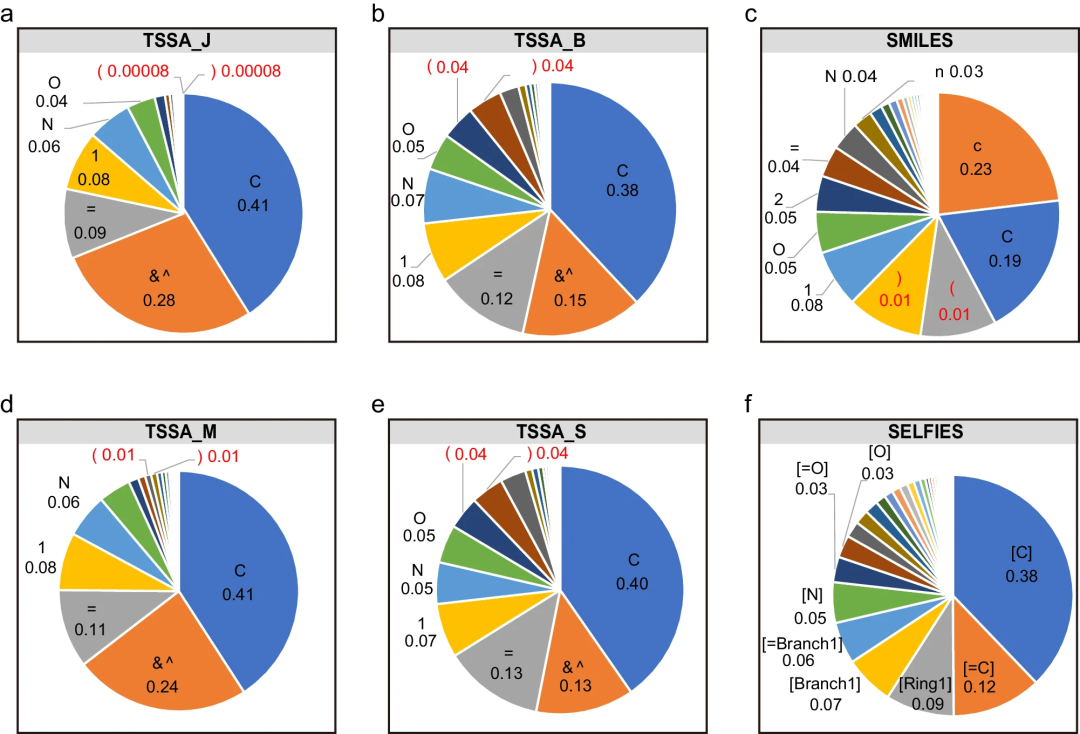
与 SMILES 相比
t-SMILES 仅引入了两个新符号「&」和「^」,编码多尺度和分层的分子拓扑。
t-SMILES 算法
提供了一个可扩展且适应性强的框架,理论上能够支持广泛的子结构方案。
基于 t-SMILES 的模型
能够在处理详细子结构信息的同时学习高级拓扑结构信息。
多代码系统
t-SMILES 算法可以构建一个用于分子描述的多代码系统,其中:
首先,研究人员通过深入研究其独特的特征来系统地评估 t-SMILES。随后,使用 TSSA 和 TSDY 对两个标记的低资源数据集 JNK332 和 AID170633 进行了实验。
研究重点是 t-SMILES 及其替代品的局限性,这些局限性是通过利用标准、数据增强和预训练微调模型实现的。使用 TSDY、TSSA 和 TSID 并行评估了 ChEMBL 上的 20 个目标导向任务。还对 ChEMBL、Zinc 和 QM9 进行了彻底的实验,通过使用类似的设置比较 t-SMILES 及其替代品。此外,比较了各种基于片段的基线模型和 SOTA GNN 模型。
最后,进行了一项消融研究,以确认基于带重建的 SMILES 的生成模型的有效性。为了评估 t-SMILES 算法的适应性和灵活性,使用了四种先前发表的碎片算法来分解分子,包括 JTVAE、BRICS、MMPA 和 Scaffold。不同实验采用了三种指标:分布学习基准、目标导向基准和物理化学性质的 Wasserstein 距离指标。
详细的对比实验表明,t-SMILES 模型生成的新分子 100% 理论有效,优于基于 SOTA SMILES 的模型。与 SMILES、DSMILES 和 SELFIES 相比,t-SMILES 的整体解决方案可以避免过拟合问题,并显着提高低资源数据集上的平衡性能,无论是使用数据增强还是预训练然后微调的模型。
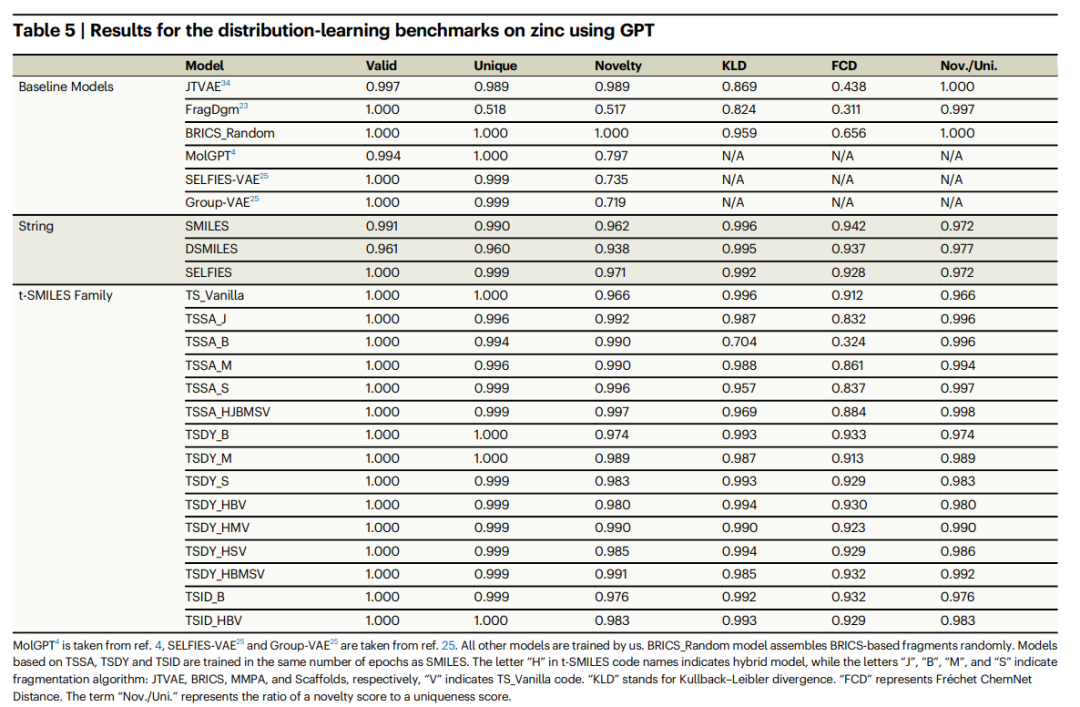
此外,t-SMILES 模型能够熟练地捕捉分子的物理化学性质,确保生成的分子与训练分子分布保持相似性。与现有的基于片段和基于图的基线模型相比,这显着提高了性能。特别是,具有目标导向重建算法的 t-SMILES 模型在面向目标的任务中比 SMILES、DSMILES、SELFIES 和 SOTA CReM 表现出明显的优势。
局限性和有待改进之处
注:封面来自网络
以上是分子100%有效,从头设计配体,湖南大学提出基于片段的分子表征框架的详细内容。更多信息请关注PHP中文网其他相关文章!






















